 histoire de l'infobésité")
Intitulée « Face à l'explosion des données : prévenir la submersion », la 36e note de l’Office parlementaire d’évaluation des choix scientifiques et technologiques (OPECST) revient sur l'histoire de cette notion. L'idée d'une surcharge ou d'une obésité d'information remonte à plusieurs siècles et a permis à deux bibliographes pacifistes d'esquisser ce qu'allait devenir Internet dès 1920.
L'OPECST commence par dresser le constat de l'augmentation exponentielle du volume de données échangées :
« L’explosion des données est une réalité incontestable dont il convient de prendre toute la mesure : en croissance exponentielle, les données créées sont passées de 2 zettaoctets en 2010 à 18 zettaoctets en 2016, et atteindront, selon les prévisions, 64 zettaoctets en 2020 et 181 zettaoctets en 2025, soit 181 mille milliards de milliards d’octets. »

Statista (qui ne propose pas, hélas, de courbe remontant au-delà de 2010) précise que « cependant, seul un petit pourcentage de ces données nouvellement créées est conservé, puisque seulement 2 % des données produites et consommées en 2020 ont été sauvegardées et conservées en 2021 ».
« Bien qu’il ouvre diverses opportunités, ce phénomène pose différents problèmes », souligne l'OPECST. Non content d'avoir un impact environnemental, cette explosion de données « a des conséquences sociales et politiques considérables : évolution vers un capitalisme cognitif marqué par une économie de l’attention et des bulles de filtre, domination des entreprises et des data centers américains, risques de surveillance de masse, nouvelles inégalités, etc. » :
« Il accélère, de plus, la surcharge informationnelle, ou infobésité, avec son corollaire de difficultés : stress, anxiété, dépression, épuisement, addiction, moindre créativité, etc. Il a des effets indirects moins visibles mais plus profonds : déclin du raisonnement par déduction au profit du raisonnement par induction, modification des structures cognitives elles-mêmes sous la forme d’une baisse durable des capacités de concentration, de traitement de l’information, de mémorisation. »
Infobésité : notre décryptage de la note de l'OPECST
- L'OPECST revient sur la (longue) histoire de l'infobésité
- Infobésité : l'OPECST appelle à la sobriété numérique
En 1613 il y avait déjà trop de livres, en 1773 trop de publicités
Intitulée « Face à l'explosion des données : prévenir la submersion », la note commence par rappeler que « même si d’autres déluges de données ont pu être rencontrés dans le passé, l’ampleur du phénomène actuel (...) à l’ère de la civilisation numérique et du Big Data, marquée par les "3 V" (volume, vélocité et variété des données), est inédite ».
Le signataire du rapport, Ludovic Haye, ingénieur en cybersécurité et sénateur du Haut-Rhin, s'amuse ainsi à rappeler que le soldat et auteur britannique Barnabe Rich se plaignait déjà, en 1613, de la prolifération de littératures :
« L’une des maladies de notre époque est la multiplicité des livres. Ils surchargent tellement le public que celui-ci est incapable de digérer l’abondance de matières oiseuses quotidiennement éclose et répandue dans le monde. »
Dans un article consacré à la société de l'information du 18e siècle, l'historien Robert Darnton relevait de son côté que « les gens se sont plaints d'un excès d'informations au cours de nombreuses périodes de l'histoire », évoquant un almanach de 1772 qui déplorait quant à lui « notre siècle de publicité à outrance ».
Une submersion (technologique) de données depuis au moins 1850
Le spécialiste de Sociologie de la quantification Emmanuel Didier soulignait lui aussi la récurrence des discours sur l’explosion de données : « il y a une très belle chose qui frappe quand on est historien de la statistique, c’est que, depuis au moins 1850, à chaque fois qu’il y a une révolution technologique, s’installe un discours selon lequel nous sommes submergés par les données ».
Le bibliographe belge Paul Otlet se plaignit lui aussi de cette inflation documentaire. À la fin du XIXe siècle, cet homme mit en place un « répertoire bibliographique universel » (RBU) rassemblant tous les ouvrages publiés dans le monde, considéré comme un ancêtre de Google ou de Wikipédia. En 1930, il notait, à propos des livres et documents sur lesquels il travaillait, que « leur masse énorme accumulée dans le passé s’accroit chaque jour, chaque heure, d’unités nouvelles en nombre déconcertant, parfois affolant » :
« D’eux comme de l’eau tombée du ciel, on peut dire qu’ils peuvent provoquer l’inondation et le déluge ou s’épandre en irrigation bienfaisante. »
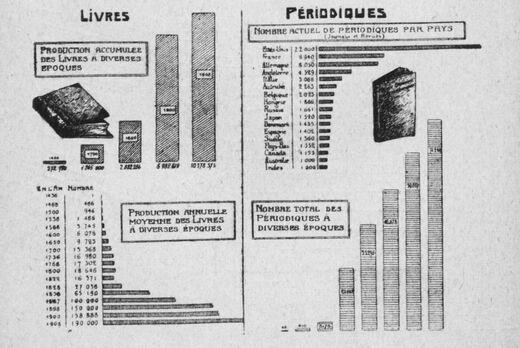 Manuel de la bibliothèque publique (3e édition) / P. Otlet et L. Wouters Source gallica.bnf.fr / BnF
Manuel de la bibliothèque publique (3e édition) / P. Otlet et L. Wouters Source gallica.bnf.fr / BnF
Dans son Traité de documentation, publié en 1934, il écrivait par ailleurs que « l'humanité est à un tournant de son histoire. La masse de données acquises est formidable. Il faut de nouveaux instruments pour les simplifier, les condenser ou jamais l'intelligence ne saura ni surmonter les difficultés qui l'accablent, ni réaliser les progrès qu'elle entrevoit et auxquels elle aspire ».
« Le père de l'idée d'Internet »
Les experts réunis au World Science Festival 2012 de New York ont depuis reconnu en Paul Otlet « le père de l'idée d'Internet ». Auteur de nombreux essais sur la manière de collecter et d'organiser la connaissance universelle, il chercha en effet à créer, avec son confrère Henri La Fontaine, un système papier d'indexation de toute la connaissance humaine :
« Leur but est à l'époque de préserver la paix en collectant, puis en classant, la connaissance universelle afin de la rendre accessible au plus grand nombre. Ils mettent alors sur pied un gigantesque Centre international de documentation, qu'ils appellent “Mundaneum”. »
Un siècle plus tard, le Mundaneum, qui indexa jusqu'à 16 millions de fiches et que l'on peut visiter à Mons, est surnommé le « Google de papier ».

Dès les années 1920, Paul Otlet imagine des systèmes de vidéoconférence et de consultation de livres à distance. Source : Mundaneum
Paul Otlet eut également l'intuition de l'ordinateur (ou terminal) personnel. Son projet de « Mondothèque-Pantothèque-Mundaneum-(Documentothèque) » était en effet pensé comme un meuble que chacun aurait chez lui, ceci afin d'encourager l'accès à – ainsi que la production – de nouvelles connaissances, comme il le décrivit dans son Traité de documentation en 1934 :
« Ici, la table de travail n’est plus chargée d’aucun livre. À leur place se dresse un écran et à portée un téléphone. Là-bas, au loin, dans un édifice immense, sont tous les livres et tous les renseignements. De là, on fait apparaître sur l’écran la page à lire pour connaître la question posée par téléphone. »

Par Mundaneum, Domaine public, Lien
Pour lui, « cinéma, phonographes, radio, télévision, ces instruments pris comme substitut du livre deviendront en fait le nouveau livre, les œuvres les plus puissantes pour la diffusion des pensées humaines, ce sera la bibliothèque rayonnée et un livre télévisé ».
« Trop de changements se passent en trop peu de temps »
Près d'un siècle plus tard, l'OPECST relève que « les capacités humaines et technologiques nécessaires au traitement et au classement des données numériques ont du mal à suivre » le rythme exponentiel qu'illustre la courbe de Statista, « en raison de coûts très élevés et de la concentration des moyens autour d’un nombre limité d’acteurs » :
« Par exemple, alors que les lettres étaient rarement sauvegardées dans le passé et n’étaient pas des données, les e-mails le sont de nos jours : ils sont conservés pour être scrutés par des algorithmes aujourd’hui et demain.
De plus, alors qu’auparavant l’État était avec l’Église le principal collecteur de données, celles-ci sont aujourd’hui principalement récoltées par des entreprises privées à travers des sources multiples (Internet, capteurs physiques, caméras, satellites, systèmes de navigation, processus industriels, santé, activités scientifiques, génomique...). »
La notion de « surcharge informationnelle » (« information overload » en anglais), pour autant, ne date pas d'Internet. Apparue aux débuts des années 1960 comme l'une des sources de dysfonctionnements des organisations, elle a été popularisée par le futurologue américain Alvin Toffler en 1970.
Son essai Le Choc du futur y décrivait en effet l'état psychologique des individus et des sociétés confrontés à une impression que « trop de changements se passent en trop peu de temps » du fait de l'accélération des progrès sociaux et technologiques.
De 500 publicités par jour en 1971 à 3 000 en 1997
Le concept d'« infobésité », lui, est apparu dans les années 90 sous la plume de David Shenk, qui relevait en 1997 que, « en 1971, l'Américain moyen était ciblé par au moins 560 messages publicitaires quotidiens. Vingt ans plus tard, ce nombre a été multiplié par six, pour atteindre 3 000 messages par jour » :
« Tout comme la graisse a remplacé la famine en tant que problème alimentaire numéro un de cette nation, la surcharge d'informations a remplacé la pénurie d'informations en tant que nouveau problème émotionnel, social et politique important. »
Enfin, souligne l'OPECST, « le fait que la quantité de données inexactes augmente fortement renforce la difficulté à traiter toutes les données disponibles ».
A contrario, et d'un point de vue industriel et capitalistique, cette explosion du volume de données offre autant de « nouvelles opportunités » qui explique l'engouement autour du « Big Data », « notamment sur un plan économique, comme en témoignent ces métaphores : nouvel or noir, pétrole du XXIe siècle, révolution du Big Data, etc. » :
« Si les données isolées ont peu d’utilité, leur agrégation et leur traitement permettent d’en extraire des connaissances et de faire des prédictions ».
Nous y reviendrons dans un second article.








Commentaires (5)
#1
Très intéressant. Merci Jean-Marc
#2
C’est vrai que nous sommes tous coupables en conservant nos vieux e-mails dans nos Boites Aux Lettres électroniques gratuites sur Google Mail, Hotmail, Yahoo Mail et consorts.
#3
Énorme ce type Paul Otlet ! GG l’ancien, il a du etre prit pour un doux dingue
#3.1
Dans le même genre, ce documentaire de 1947 qui anticipait les smartphones et leurs effets…
#3.2
Oui étonnant aussi, mais Paul Otlet a fait preuve d’une imagination très poussée dans l’intérêt, le fonctionnement et les applications.