
Il y a quelques jours, Amazon clôturait sa conférence re:invent. La société y a présenté une véritable avalanche de services dédiés au cloud, et dans pratiquement tous les domaines possibles. Une volonté farouche de rappeler à la concurrence – et à la clientèle – qu'elle compte bien rester en haut du podium.
Amazon avait déjà marqué les esprits l’année dernière lors de sa conférence re:Invent en annonçant pas moins de 1 400 nouvelles fonctionnalités, réparties dans de nombreux services, interfaces de programmation (API) et autres.
Cette année, c’est à nouveau la déferlante. Son empire sur le cloud, menacé par un Microsoft dont les ambitions et la croissance ne faiblissent pas (bien au contraire), se retrouve survitaminé par des annonces dans pratiquement tous les domaines, y compris ceux où la firme de Redmond s’est fait une spécialité, en particulier le cloud hybride et les installations sur site.
À moins de toute façon qu’Amazon ne se prenne les pieds dans ses produits, le nombre d’annonces n’a que peu de chances de baisser dans le temps : il suffit de présenter du neuf dans chaque catégorie pour produire automatiquement un effet de vague. Puces maison, Elastic Cloud, stockage, serverless, objets connectés, machine learning, blockchain, produits sur site, virtualisation ou encore bases de données : Amazon veut être partout et se montre plus agressif.
Graviton : des puces ARM maison pour ses propres serveurs
La première grande annonce d’Amazon concerne le lancement de nouveaux serveurs basés sur des processeurs ARM. Comme nous l’avons déjà indiqué, ces puces ne sont pas « standards », puisqu’il s’agit de modèles maison, résultats du rachat d’Annapurna Labs en 2015.
Nommées Graviton, elles exploitent les nouveaux cœurs Neoverse annoncés par ARM il y a quelques semaines. Elles permettent un parallélisme à moindre coût des instructions, du moins sont-elles présentées ainsi par Amazon.
L’offre se répartit en cinq serveurs, allant du a1.medium avec 1 vCPU et 2 Go de mémoire vive au a1.4xlarge avec 16 vCPU et 32 Go de RAM. À chaque palier, le nombre de vCPU et la quantité de mémoire sont doublés. Pour les quatre premiers, la bande passante Elastic Block Store grimpe « jusqu’à » 3,5 Gb/s, contre 3,5 Gb/s pour le dernier. Dans tous les cas, la bande passante réseau est de 10 Gb/s.
Les tarifs vont quant à eux de 0,0255 dollar à 0,4080 dollar par heure. L’entrée peut surprendre, puisque plus chère par exemple qu’une instance t3.small, qui embarque pourtant deux CPU Xeon Platinum 8000 et 2 Go de mémoire vive. Mais attention, car cette dernière table sur un taux d’occupation moyen de 20 % et peut donc entraîner une facturation supplémentaire en cas de pics d’utilisation. Les instances a1 n’ont pas de telles conditions, et c’est bien là-dessus que compte Amazon bien sûr.

On ne sait cependant pas précisément ce que l’on peut attendre des performances de ces instances. Il faudra attendre les retours des clients pour les vérifier, d’autant que tout ne sera pas exploitable directement. Les scripts sont ainsi exécutables en l’état, mais pas le code natif, qui devra être recompilé pour ARM, comme on s’en doute.
En outre, si tous les rôles habituels de serveurs sont disponibles pour ces nouvelles instantes, tous les systèmes d’exploitation ne le sont pas. Pour l’instant, seuls Amazon Linux 2, RHEL et Ubuntu sont pris en charge, la société en promettant d’autres à l’avenir, sans dire lesquels ni quand.
Machine learning : puces Inferentia et instances Elastic Inference
Avant de plonger dans les nouveautés annoncées dans ce domaine, il faut rappeler ce qu’est l’inférence. Le mot est issu du jargon de la logique. Synonyme d’induction, elle représente l’opération par laquelle une proposition devient admise en vertu de ses relations avec d’autres propositions admises précédemment.
En informatique (au sens large), le mot est repris principalement dans deux contextes. D’abord en développement logiciel avec l’inférence de types : le compilateur (ou interpréteur) cherche automatiquement le type associé à chaque expression, en fonction de celle-ci. En intelligence artificielle, l’inférence permet la création de liens logiques entre informations, selon des références définies. En fonction des cas, elle crée des hypothèses, des propositions ou des conclusions.
Dans ce domaine, les opérations d’inférences – dont de mise en relation des données – ne peuvent pas être exécutées plus rapidement que par des GPU. Pour les besoins intensifs chez Amazon, il faut donc acheter des instances P3 dédiées. L’éditeur, grand prince, considère que le coût est actuellement trop élevé pour de nombreux clients.
Il annonce donc Amazon Elastic Inference, qui change complètement d’approche pour les besoins légers à moyens. Constatant que l’utilisation moyenne des GPU dans les instances P3 va de 10 à 30 % en moyenne, AEI permet de s’en affranchir pour un modèle plus souple, où le client peut ajouter de l’inférence accélérée matériellement à ses instances EC2 classiques quand il en a besoin. Selon Amazon, la réduction de coût peut atteindre 75 %.
Trois variantes sont proposées pour Amazon Elastic Inference :
- eia1.medium : 8 TeraFLOP (mixed-precision)
- eia1.large : 16 TeraFLOP (mixed-precision)
- eia1.xlarge : 32 TeraFLOP (mixed-precision)
Un « bonheur » n’arrivant jamais seul, Amazon en profite pour frapper plus fort. Que Google, Intel, NVIDIA et les autres se tiennent prêts, car un nouveau concurrent débarquera bientôt dans le secteur des puces dédiées au machine learning.
Nommée Inferentia, la puce ne laisse aucun doute sur les intentions du géant. Décrite comme « très haut débit, à faible latence, aux performances soutenues et très rentables », cette puce ne sera disponible que dans le courant de l’année prochaine, sans autre précision sur la période.
Il est évident qu’il s’agira d’un premier pas d’Amazon dans ce domaine, et que les performances ne pourront pas être par magie au même niveau que les autres. D’autant que l’inférence n’est que la deuxième des deux grandes phases du machine learning. L’autre, l’entraînement, n’est donc pas pris en charge.
Mais l’entreprise va jouer sur d’autres terrains, notamment l’ouverture. Inferentia sera compatible avec la plupart des précisions, dont INT8, FP16 et mixte. Côté frameworks, tous les plus courants devraient eux aussi être pris en charge, notamment Caffe2, TensorFlow et ONNX. Ce qui permet du même coup de rapatrier les modèles conçus ailleurs si les performances devaient s’avérer intéressantes… ou les coûts. Et bien sûr après la phase d’entraînement.
Amazon risque fort de jouer en effet la carte du tarif pour se démarquer. La mention d’une puce « très rentable » n’est pas là par hasard. On attend donc de connaître les prix, qui pourraient ne pas arriver avant plusieurs mois, le temps qu’Amazon soit prêt à utiliser ces puces en production.
Entraînement des modèles : simplifier l’étiquetage
Après l’inférence, l’entraînement. Cette étape consiste à faire avaler à un modèle de machine learning de vastes quantités de données. Mais avant de pouvoir se lancer, encore faut-il disposer d’un stock parfaitement labellisé.
L’étape est rébarbative et, dans la plupart des cas, à la seule charge de l’utilisateur. Amazon annonce donc Ground Truth pour SageMaker. Ce dernier est pour rappel le service qui propose depuis quelques années de simplifier la création, l’entraînement et le déploiement des modèles de machine learning, y compris à grande échelle.

Ground Truth permet à une entreprise de pointer un ou plusieurs silos de données et d’y lancer une détection pour apposer automatiquement des labels. Les quatre grandes reconnaissances sont de la partie : texte, images, objets et segmentation sémantique. L’automatisation du processus est réglable, de manière à laisser d’authentiques êtres humains superviser le travail, voire en effectuer une partie. Les utilisateurs peuvent d’ailleurs ajouter leurs propres classements.
Il est probable que Ground Truth devrait être un service populaire si son efficacité de reconnaissance est confirmée. Les entreprises intéressées peuvent potentiellement gagner un temps précieux, qui pourra être dépensé dans d’autres opérations. Sans parler d’éviter à des utilisateurs la tâche particulièrement ingrate d’avoir à étiqueter eux-mêmes les objets dans des images.
Un modèle réduit de voiture pour apprendre le reinforcement learning
Le machine learning est clairement l’un des sujets phares d’Amazon depuis plusieurs années. En plus des services déjà présents, d’autres sont venus s’ajouter à un bouquet déjà bien garni.
On commence avec un nouveau service d’apprentissage sortant de l’ordinaire : DeepRacer. Le nom résigne à la fois un service et un modèle réduit à l’échelle 1/18e d’une voiture de course. Objectif, perfectionner les talents des utilisateurs en machine learning, via une approche différente.
On parle ici de « reinforcement learning », qui est une autre manière d’entraîner un modèle ML. Au sein d’un environnement interactif (ici la voiture), un agent est chargé d’agir. Sur la base d’une approche « essais et erreurs », l’agent apprend donc des retours de ses actions, mesurant ses progrès vers un objectif déterminé par les développeurs. C’est par exemple cette technique qui est utilisée pour concevoir des « IA » dans les jeux d’échecs et de Go.
Grande différence avec d’autres techniques, le reinforcement learning peut s’utiliser à partir d’une page blanche, donc sans lot de données préalables. DeepRacer ambitionne de joindre l’utile à l’agréable en permettant une hausse des compétences dans un domaine très concret – la conduite autonome – en évaluant les résultats sur le modèle réduit.

Au début, il faudra entraîner le modèle conçu dans un environnement virtuel et un simulateur, sur des circuits créés à l’aide de RoboMaker. Le service fournit un lot de circuits préconçus, mais les développeurs sont libres d’en ajouter autant qu’ils le souhaitent. Quand ils estiment le modèle suffisamment préparé, ils peuvent alors le télécharger et l’installer dans le modèle réduit.
Ce dernier, contrôlé par radio et équipé de quatre roues motrices, embarque un processeur Atom. Il alimente une distribution Ubuntu 18.04 accompagnée du kit d’outils OpenVino d’Intel et de ROS (Robot Operating System). La batterie doit permettre une autonomie de deux heures, le tout avec du Wi-Fi 802.11ac, plusieurs ports USB et une caméra de 4 mégapixels pour du 1080p.
Et si la dimension « fun » de la voiture n’était pas assez claire, Amazon organisera régulièrement des évènements DeepRacer League. Les joueurs s’affronteront sur des circuits dont les plans auront été communiqués à l’avance. Les voitures pourront donc être entraînées jusqu’aux matchs, qui se dérouleront en environnement réel. Lors de la prochaine conférence re:invent (donc fin 2019), Amazon remettra une coupe à l’équipe qui aura remporté le plus de victoires (logique).
Vous reprendrez bien un peu de machine learning
Amazon continue sa grande offensive vers la simplification des opérations de machine Learning avec Forecast, littéralement « prévision ». Cet outil clé en main permet aux entreprises clientes de lui faire ingérer tout un lot de données, le service produisant automatiquement des prévisions en fonction des types d’informations fournis.
L’exemple fourni est parlant. En entrée, on trouve des données historiques (ventes, trafic web, chiffres d’inventaire, flux financiers, etc.) et données périphériques (planning de vacances, descriptions des produits, promotions et autres. Forecast reconnaît les données et produit automatiquement des prévisions sur la gestion des stocks, les ventes et autres.
Selon Amazon, Forecast produit de lui-même des résultats plus pertinents que ce que la plupart des entreprises créent par elles-mêmes, tout en s’épargnant – évidemment – l’effort de développer son propre modèle. Forecast fonctionne par défaut en mode totalement automatisé, piochant dans une réserve de huit modèles préconçus de machine learning, puis l’entraînant en fonction des données analysées. Une entreprise cliente peut cependant fournir un modèle spécifique pour personnaliser davantage les résultats.
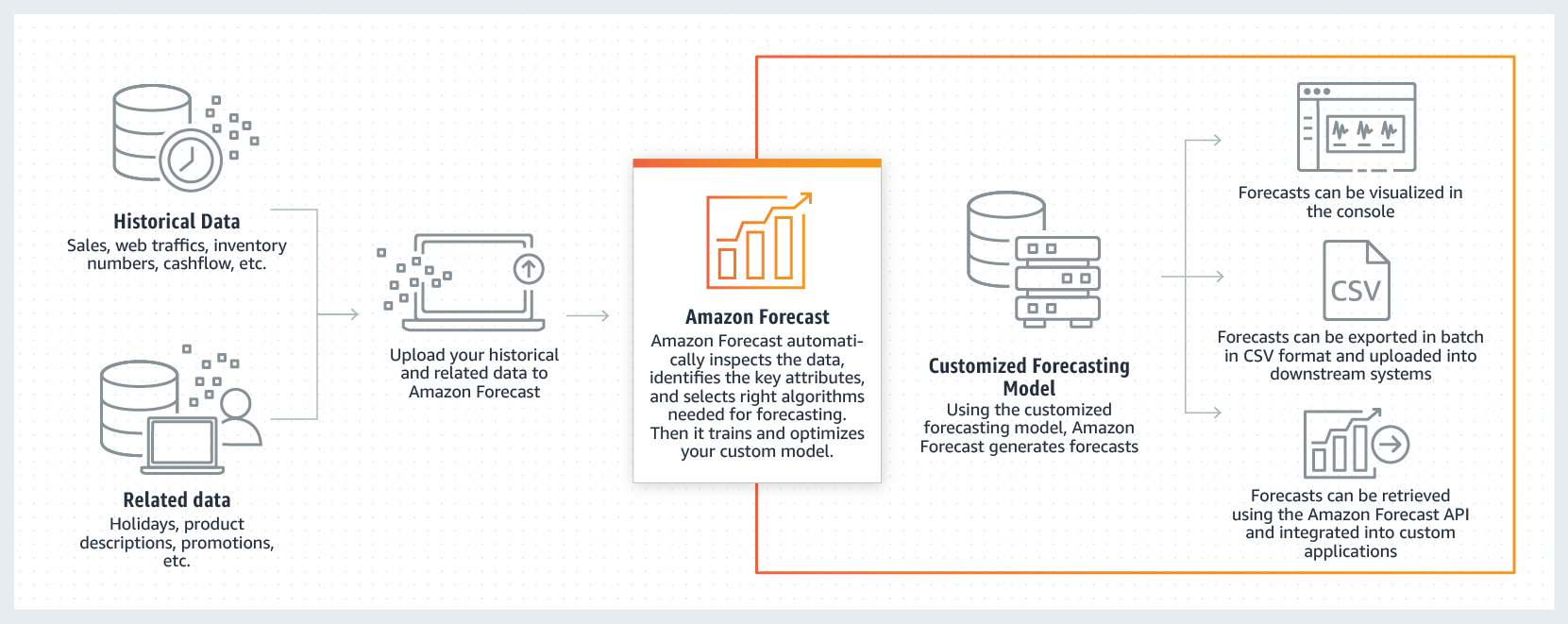
Les prévisions sont dans tous les cas visibles dans la console, exportables en lots de CSV ou encore accessibles via la nouvelle API Forecast, faisant le lien entre le service d’Amazon et des applications tierces. Des ponts ont notamment été mis en place pour faire circuler les données vers SAP et les produits Oracle. Bien entendu, les données sont récupérables directement dans les nouvelles bases de données Timestream, sur lesquelles nous reviendrons.
Et s’il fallait un argument massue, Forecast est la technologie utilisée par Amazon pour gérer son site principal.
Cette volonté de simplification se retrouve encore dans Amazon Personalize, qui cherche à chapeauter tout le travail de personnalisation et de recommandation, en temps réel. Le concept initial n’est donc pas nouveau, SageMaker permettant d’en créer depuis des années. Selon l’éditeur toutefois, ce processus long et coûteux peut être largement accéléré avec le nouvel outil.
Personalize se sert notamment d’AutoML pour automatiser la plupart des tâches liées au machine learning : conception, entraînement et déploiement. Il supporte les jeux de données stockées ou en flux, Amazon donnant comme exemple des évènements générés en temps réel par un traqueur JavaScript ou un serveur quelconque.
Textract : de la reconnaissance de caractères à celle des formulaires
La reconnaissance d’écriture est déjà un vieux domaine. Ce que l’on nomme OCR (pour « optical character recognition ») accompagne depuis bien longtemps les scanners, avec la promesse – aujourd’hui tenue – que les textes seront reconnus et transformés en version numérique exploitable. Du moins tant que l’on reste sur des formats classiques.
Avec Textract, Amazon s’aventure dans le territoire sauvage des formulaires. On quitte les simples paragraphes pour des éléments d’informations répartis dans des structures pouvant fortement varier. Amazon décrit son nouveau service comme un « OCR intelligent », capable de reconnaître les éléments de texte, mais aussi la manière dont les informations sont organisées dans une page.
Sur scène, l’éditeur s’est livré à une comparaison simple entre un produit classique et son Textract. Face à un formulaire contenant un tableau, le premier n’a vu que du texte et l’a interprété comme les morceaux séparés d’une phrase. Le second a bien vu un tableau et en a extrait les données comme telles.
Cet aspect intelligent s’étend jusqu’aux informations elles-mêmes. Si le tableau contient par exemple des informations personnelles telles que l’adresse postale, l’adresse email, le numéro de téléphone ou encore celui de sécurité sociale, Textract peut les repérer et les répartir automatiquement où l’utilisateur lui aura demandé de les stocker.
Stockage de fichiers : sus à Windows !
Le cloud d’Amazon est devenu initialement célèbre pour le stockage de fichiers. Depuis, la société propose des serveurs de fichiers sous Linux. Mais toutes les entreprises n’ont pas forcément intérêt à basculer chez l’éditeur, notamment celles ayant des besoins spécifiques de compatibilité avec Windows.
Qu’à cela ne tienne, l’éditeur propose désormais Amazon FSx for Windows File Server. Ces serveurs utilisent des SSD, sont formatés en NTFS et gérés par Windows. Ils sont accessibles via le protocole SMB (versions 2.0 à 3.1.1), Amazon vantant les performances en bande passante (jusqu’à 2 Go/s), opérations d’entrées/sorties et temps d’accès, inférieurs à la milliseconde selon le responsable Jeff Barr dans son billet de blog. Chaque partition peut faire jusqu’à 64 To.
Les données partagées sont accessibles via les instances Elastic Compute Cloud, les bureaux virtuels WorkSpaces, les applications AppStream 2.0 et VMware Cloud sur AWS. Côté postes de travail, la compatibilité est assurée dès Windows 7 et Server 2008 pour l’univers Microsoft, et l’ensemble des distributions Linux actuelles, à travers Samba.
La nouvelle offre est évidemment une manière pour Amazon de grignoter des parts de marché à Microsoft, dont le bouquet Azure ne cesse également de s’étoffer, en tapant dans un secteur qui était traditionnellement associé à Windows.
Amazon veut simplifier la formation des lacs
Derrière ce titre hydrogéologique se cache une vraie volonté de l’éditeur de faciliter la création de lacs de données. Ces derniers sont des réserves de données brutes ou très peu transformées, stockées sous cette forme pour des utilisations éventuelles plus tardives. Ils sont caractérisés par des mélanges des informations de natures différentes et ne se présentant même pas toutes sous forme de fichiers.
Quand Amazon parle de simplification, il traduit la mise en place d’un lac de données en « quelques jours ». Les opérations habituelles sont nombreuses puisque les lacs servent à réunir dans un même endroit des données issues de différents silos : configuration du stockage, déplacement des données, ajout des métadonnées, référencement dans un catalogue, puis éventuellement d’autres opérations ensuite, comme le nettoyage et les règles de sécurité.

Selon Amazon, il faut habituellement jusqu’à plusieurs mois pour mettre en place un tel lac. Le nouveau service AWS Lake Formation veut donc réduire drastiquement ce délai en réunissant notamment au même endroit tout ce dont un administrateur aurait besoin. Les processus gèrent automatiquement et au fur et à mesure des opérations comme la déduplication, l’ajout de labels ou encore le nettoyage. Le service propose ensuite des règles de sécurité qu’il estime adaptées aux données présentes.
Serverless, cloud hybride : Amazon attaque partout
Avant de continuer, il faut rappeler ce qu’est le concept de « serverless computing ». On parle d’informatique sans serveur, bien que l’appellation soit trompeuse : il y a bien des serveurs, mais le prestataire de service les alloue dynamiquement en fonction des besoins du client. Ce dernier fournit simplement des instructions et est facturé en fonction des capacités nécessaires à leur réalisation.
Chez Amazon, les services liés au serverless sont réunis sous l’étiquette Lambda. Cette année, Lambda se dote justement de nouvelles capacités, dont la prise en charge de plusieurs nouveaux langages, ce qui était largement réclamé par les développeurs, selon l’éditeur. Les fonctions Lambda peuvent par exemple maintenant être écrites en Ruby ou en C++.
Une envie de séduire qui s’étend au support des environnements de développement intégré. Visual Studio, PyCharm et IntelliJ (en préversion) sont ainsi pris en charge.
Bien que l’informatique « sans serveur » promette une simplification des opérations, Amazon se dit peu satisfait de certains cas, quand les développeurs se lancent dans des projets plus complexes ne pouvant plus se résumer à de simples déclencheurs d’évènements. L’éditeur lance donc Lambda Layers, qui permet une gestion centralisée du code et des données partagés entre des fonctions multiples.
Amazon lance également sa Step Functions Service Integration. Ce service permet de créer un lot d’étapes et de déclencheurs, récupérables ensuite dans d’autres produits Amazon, tout particulièrement DynamoDB et Sagemaker.
Amazon fait en outre un premier pas vers les installations sur site, alors qu’il a toujours été jusqu’à présent un pur acteur du cloud. On est encore loin du bouquet fourni par Microsoft avec Azure dans ce domaine, mais avec ses Outposts, Amazon fait une incursion dans les centres de données. Le service se présente via deux méthodes, VMware Cloud on AWS Outposts et AWS Outposts. Le premier fait appel à la virtualisation, pas le second.
Avec Outposts, Amazon vend son matériel aux entreprises intéressées, qui peuvent alors l’installer sur leurs propres sites. Cet aspect est une condition sine qua non pour que les services d’Amazon puissent fonctionner sans que la firme ait besoin de développer toute une gestion du matériel tiers (problématique que Microsoft connaît bien).
Une fois le matériel en place, Amazon se charge de l’entretien, mais l’entreprise cliente le configure comme elle le souhaite, de même que tous les composants logiciels. Les traitements sont alors effectués là elle le décide, supprimant les difficultés classiques liées au cloud, notamment l’emplacement des données et la question du contrôle. Une société peut par exemple s’intéresser aux facultés d’AWS tout en souhaitant protéger ces traitements de toute connexion.
Notez que si Outposts vient d’être annoncé, il n’est encore qu’en préversion. Il est d’ailleurs accompagné d’un autre outil, Transit Gateway, conçu pour construire une topologie réseau au sein d’AWS entre les instances du client, qu’elles soient publiques, privées (via Amazon Virtual Private Cloud) ou maintenant sur site.
Une base de données dédiée aux évènements dans le temps
Avec Timestream, Amazon veut répondre à des demandes spécifiques, nombreuses selon lui. L’éditeur peste ainsi contre les bases de données relationnelles classiques, bien peu adaptées au suivi d’évènements dans le temps.
Timestream est donc une base de données où chaque entrée correspond à un horodatage, avec un ou plusieurs attributs supplémentaires. La structure est donc différente, les données étant organisées par intervalles de temps et pouvant bénéficier d’une compression spécifique. Les performances en seraient améliorées, la base nécessitant notamment d'être moins souvent scannée.
Amazon n’hésite en fait pas à annoncer que son service Timestream peut se montrer jusqu’à mille fois plus rapide qu’une base de données relationnelle classique, pour un dixième du coût. Certes, mais pour qui ? Timestream se destine à des usages particuliers et pourrait prendre tout son sens par exemple pour stocker les données d’objets connectés chargés d’assurer n’importe quel type de surveillance.
On pense par exemple à une usine bardée de capteurs de pression, température, humidité et autres. Une base Timestream serait alors chargée d’enregistrer l’historique des relevés, pour ensuite alimenter d’éventuels algorithmes. Tant qu’à faire, il serait dommage de ne pas puiser dans les autres services de l’entreprise.
Plus d’hésitations sur la blockchain
Si toutes les annonces précédentes vont dans le sens d’un renforcement et d’une volonté de simplifier l’utilisation des services, données et modèles, la blockchain est un domaine auquel Amazon résistait jusqu’à présent. L’éditeur était même allé jusqu’à se débarrasser de l’idée d’un revers de la main, jugeant qu’il ne bâtissait pas des services « juste parce que c’est cool ». Sous-entendant que la blockchain n’était dans le fond pas une technologie bien sérieuse.
Quel changement en un an, avec le lancement de deux services dédiés. Le premier, Amazon Managed Blockchain, est comme son nom l’indique dédié à la gestion d’une blockchain et son utilisation dans des applications. Actuellement, seule Hyperledger Fabric est utilisable, mais Ethereum devrait arriver dans les mois qui viennent.

Selon Amazon, son service a les reins assez solides pour gérer des milliers d’applications et des millions de transactions en même temps. L’éditeur ne dit cependant pas un mot sur les performances, qui finissent par être le problème avec l’augmentation de la charge. Les développeurs intéressés seront en mesure de « créer des réseaux en quelques clics » et de les gérer via des appels aux nouvelles API. En clair, le service et les applications doivent pouvoir se gérer aussi simplement que n’importe quel autre produit du bouquet AWS.
Le deuxième service est une base de données reprenant le mode de fonctionnement d'une blockchain, mais sans faire appel à des nœuds exterieurs, donc sous l'égide d'une autorité centrale de confiance. Nommée Amazon Quantum Ledger Database, ou QLDB, elle constitue ainsi un journal immuable et n’autorisant que les ajouts pour stocker l’intégralité des changements intervenus sur la blockchain utilisée.
Le produit se veut deux à trois fois plus rapide dans cette tâche que les solutions concurrentes plus traditionnelles. Comme avec les autres annonces du même acabit, on attendra de juger sur pièce.
Amazon reste le leader du cloud
Avec ses Web Services, Amazon reste indubitablement premier dans le domaine du cloud et des services déportés. Plus aucun domaine n’échappe aux appétits d’un ogre qui, pour le malheur de ses concurrents, sait en plus écouter les demandes de ses clients.
L’offre mute vers un niveau d’abstraction qui signe la maîtrise technique de l’éditeur, avec une simplification notable d’un nombre croissant d’aspects. Conséquence, elle en devient d’autant plus désirable pour des entreprises jugeant jusqu’à présent trop complexe une éventuelle déportation de leurs opérations vers le cloud.
Comme toujours quand une entreprise est partout, d’autres seront par contre gênés qu’Amazon soit pratiquement en mesure de répondre à n’importe quel besoin, avec un ensemble d’outils qui auraient tôt fait de rendre l’éditeur incontournable. Oracle essaye par exemple d’intégrer ce domaine depuis un moment. Mais non seulement l’entreprise a bien du mal, mais Amazon vient maintenant jouer sur son propre terrain en lançant plusieurs nouveaux services de bases de données. Avec FSx for Windows File Server et les prémices de produits sur site, Microsoft n’a pas non plus été laissée tranquille. Chez Google, on a dû observer avec suspicion l’arrivée des puces Inferentia et des instances Elastic Inference.
Le danger qui guette Amazon réside finalement dans son objectif : le risque d’empâtement quand le bouquet Web Services sera en mesure de répondre à tous les besoins. On espère donc que la concurrence restera vive, et pas nécessairement dans le seul cloud, qui ne saurait être la réponse universelle à tous les problèmes, en dépit de ses promesses.











Commentaires (10)
#1
Bonjour,
“inférence = Synonyme d’induction” ??? Ça me semble confus.
L’induction généralise des cas particuliers pour en formuler une loi générale. C’est donc l’entraînement en IA.
Ça utilise un max de GPU grâce aux frameworks dédiés (calculs tensoriels sur cuda-cores)
L’inférence correspond à l’utilisation des modèles, après entrainement.
C’est plus léger en calcul. D’où les puces dédiées sur les smartphones.
D’où la proposition d’Amazon de combiner CPU avec un peu de GPU si besoin.
#2
la création de lacs de données
ça prends l’eau ? c’est quoi un lac de données ?
#3
C’est comme une flaque de données, mais en beaucoup plus large et profond.
#4
C’est super tout ça mais quand tu n’as pas besoin de tous ces services dont l’hébergement “on premise” est complexe, et que tes workloads ne sont pas AWS ça reste super cher.
Autre point : le jour où tu veux sortir d’AWS (notamment parce que ça coûte un bras et que tu as zéro maîtrise de tes coûts vu qu’ils peuvent décider unilatéralement de modifier les tarifs et qu’ils ne se privent pas de le faire) c’est ultra compliqué.
#5
#6
#7
#8
Le vendor locking c’est inévitable. Même avec K8s, quand tu passes un workload d’un provider à un autre il faut refaire la moitié de ta conf, monitoring, pipeline de déploiement etc.
 " />
" />
Et pour ceux qui voient / comparent le prix des services AWS avec le prix d’offres IAAS ou hébergement on-premises il est temps de se réveiller
#9
#10
il est certain que faire du cloud n’est pas le meme savoir faire que du on premise, malgré tout un cloud bien maitrisé coute moins cher, mais la maitrise elle n’est pas encore le fait de tout le monde.