

Qu’un article de l’eurodéputée Julia Reda soit déréférencé de Google à la demande d’une société de défense de l’industrie culturelle, c’est déjà fort. Lorsque ce même article traite des dangers des robots-copyrights prônés dans la réforme sur le droit d’auteur, cela en devient un superbe avant-goût.
Publié en mai, l’article en question est consacré à deux dispositions phares de la réforme de la directive sur le droit d’auteur.
Il revient en particulier sur l’article 13, qui industrialise le filtrage des contenus sur les plateformes d’hébergement. L’eurodéputée issue des rangs du Parti pirate dénonce les risques pesant sur la liberté d’expression, au profit des seuls intérêts des industries culturelles. Un déséquilibre qu’elle juge inacceptable.
Ironie du sort, cet article a été déréférencé de Google le 22 juin à la demande de Topple Track, un service de protection édité par Symphonic Distrib. Celui-ci a imaginé la présence d’une contrefaçon des œuvres d’une chanteuse, Gamble Breaux. Google a pris en compte alors la réclamation pour retirer automatiquement ces pages faussement litigieuses, lesquelles ne contiennent pourtant aucune œuvre de l’artiste australienne…
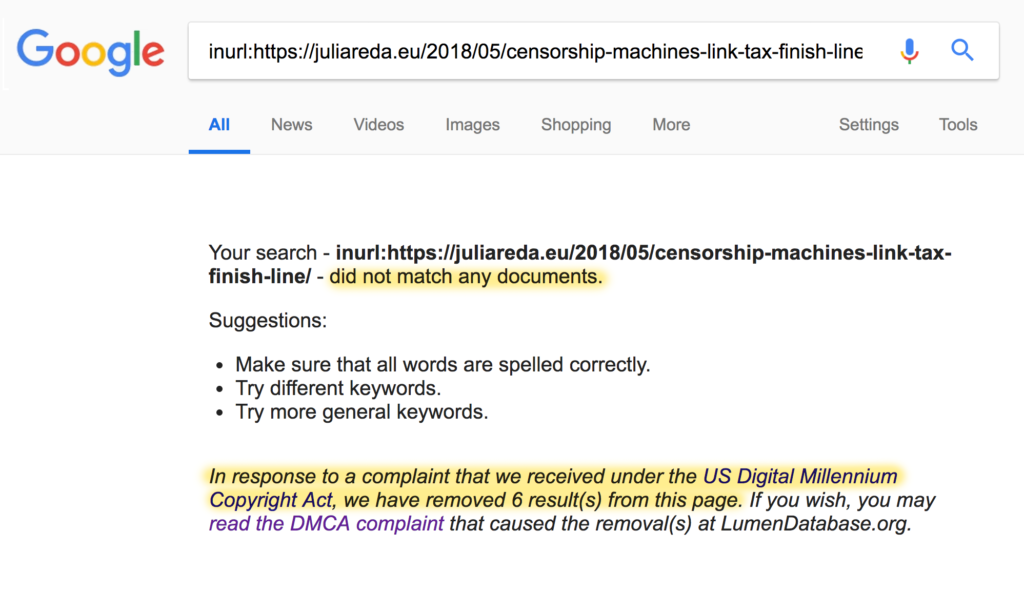
Pour l'eurodéputée, le filtrage « mène invariablement à la censure »
Pour l’eurodéputée, cet incident sous l'égide du droit américain (le DMCA) donne finalement un avant-goût de ce que générera le filtrage des contenus en Europe, du moins si les députés du Parlement adoptent la « filter law ». « C’est un appel aux armes pour continuer à lutter contre les filtres de copyright automatisés. Nous le savons maintenant mieux que jamais : ils mènent invariablement à la censure ».
Selon elle, « si des humains avaient été impliqués à un étage quelconque de ce processus, l’absurdité ou la malveillance de cette demande aurait été immédiatement détectée ». Faute d’un tel dispositif, elle considère qu’il n’y a aucun frein ni contrepoids à ces erreurs aussi flagrantes. Elle se demande au passage, parmi les millions de liens déréférencés, combien ont visé des contenus légitimes, sans que les auteurs respectifs n’aient été prévenus.
Exemples et contre-exemples
L'article a depuis été réinjecté dans le moteur. Les abus et autres couacs dans les demandes de déréférencement ont cependant été nombreux dans le passé. En 2015, pensant avoir repéré des contrefaçons du film Pixels, une société spécialisée avait demandé à la plateforme Vimeo la suppression de plusieurs vidéos, pourtant sans rapport avec la superproduction. Dans le lot, des courts-métrages indépendants, une bande-annonce officielle et même un film lié à un festival belge dénommé « Pixels »....
La même année, mandatée par Universal Pictures France, l’entreprise TMG avait tenté de traquer les copies illicites du film Hacker en réclamant l’effacement sur Google d’un lien vers un article de Techdirt.com évoquant l’affaire… Hacking Team.
Toujours en 2015, Google a été invité à déréférencer cette fois les pages officielles de Skype, Ubuntu, Open Office, Gimp.... En vain cette fois. Deux ans plus tôt, le même moteur déréférençait cependant des liens vers le documentaire The Pirate Bay - AFK, pourtant diffusé sous Creative Commons, à la demande de l’industrie américaine du cinéma.
Parfois, ces procédures sont dignes d'Inception. Google avait reçu en 2014 des demandes d’effacement visant des centaines de demandes de déréférencement répertoriées sur le site LumenDataBase (ex ChillingEffects). Ce même site avait été décrit comme le plus grand répertoire mondial de sites pirates selon l’industrie musicale américaine.
Des contenus présumés coupables
Le vote au Parlement européen, fixé au 12 septembre, sera une nouvelle fois l’occasion pour les partisans du filtrage – en particulier la quasi-totalité des eurodéputés français – de revenir à la charge après un échec cuisant en juillet dernier.
Selon le sens des votes, elle anticipe une situation pire que cet exemple. En effet, « avec les filtres à l’upload, les plateformes ne vont même plus attendre les plaintes des sociétés de défense pour retirer vos posts. À la place, vos contenus ne seront même pas mis en ligne, sauf à passer le contrôle des bases de données des sociétés de défense de l’industrie culturelle. Et vous pouvez être sûr que ces bases seront tout aussi remplies d’ordures et de fraudes ».
Toujours d’après son analyse, ces bases de données qui nourriront les mécanismes de filtrage vont finalement donner à leur propriétaire un contrôle direct sur Internet, puisque « les contenus seront présumés coupables sauf à démontrer leur innocence ».
À ses yeux, l’incident dont elle a été victime, outre les innombrables précédents, devrait éclairer utilement les législateurs européens. « L'application automatisée des droits d'auteur ne fonctionne pas. Les filtres menacent gravement notre liberté d’expression. Ils doivent être rejetés » implore-t-elle.
Le 26 août, une journée de mobilisation est organisée contre le filtrage automatisé des contenus sur droit d’auteur, ainsi que la création d’un droit voisin pour les éditeurs de presse (la fameuse « Link Tax »). Les premiers amendements sont attendus au Parlement dans les jours à venir.






















Commentaires (68)
#1
Mais putain… mais putain… mais putain…
#2
Hé oui ! On n’avait gagné que deux mois de sursis pour les vacances, en réalité…
Mais tu sais : si jamais le Parlement européen devait confirmer son refus de juillet, tu peux être sûr que les vrais voleurs de la culture (les SACEM, SCPP, SACD et autres équivalents européens) ne cesseront de revenir à la charge tant qu’ils n’auront pas eu la peau d’Internet (leur unique objectif depuis 20 ans). Et là, ils sont plus proches que jamais de l’emporter enfin…
#3
Vu le binz, j’ai plus qu’a fermer inlibroveritas moi " />
" />
#4
Coïncidence ou pas, le site https://saveyourinternet.today/ (cf. le lien pour la mobilisation du 26 août) est bloqué dans mon entreprise pour le motif “Malicious Sites” / “High Risk”…
#5
Le TLD « .today » qui doit pas plaire…
#6
Ouais, les terreauristes étaient en vacances aussi.
 " />
" />
C’est la rentrée, paf, y en a un qui arrive chez Christophe Collomb.
#7
Là les choses sont graves, on est plus dans l’indignation préventive tout en se drapant des grands principes.
#8
il était évident qu’une telle bourde finirait par arriver.
j’aurais pas espéré si tôt. ^^
#9
Autant, je pense, qu’on ne peut pas demander à Google de vérifier la légitimité des demandes de référencement, autant il serait souhaitable que les sites qui se sont vu retirer des liens, puissent être informé par google (si ce n’est pas le cas) des coordonnées de celui qui a demandé le déréférencement afin que, si la demande est abusive, puisse se retourner devant les tribunaux et demander des dommages et intérêts conséquents, ce qui devrait calmer un peu ces demandes de déréférencement abusives.
#10
D’ailleurs j’en profite pour signaler que l’heure et le lieu de la mobilisation à Paris contre les articles 11 et 13 de la réforme du droit d’auteur ont été fixés : ce sera à la Place Jules Joffrin dans le 18ème à partir de 14h30.
#11
#12
#13
#14
#15
#16
Ses lois ne sont pas faite pour vous… dans tout les cas.
#17
#18
L’analogie n’est pas très bonne. La légitimité de la source de la demande n’est pas discutable. Et comme il y a des entaines ou milliers de demande de deferencement, les robots de Google accepte sans broncher les demandes. Théoriquement la responsabilité des demandeurs devaient être engagés avec amandes en cas d’erreurs mais bon…
Résultat on a un dispositif qui ne fonctionne pas bien, mais comme par hasard en faveur des ayants droits.
#19
Moi ce qui me désole un peu, c’est que l’appellation “ayant droit” se soit vue progressivement détournée pour désigner un ennemi imaginaire. Un peu comme “GAFAM” dès qu’on veut invoquer la peste et le choléra.
Par honnêteté intellectuelle, il conviendrait de nommer ces ayants droits, ou inventer un nouvel acronyme à la mode comme “GAFAM”, “NATU”, etc.
Nous sommes potentiellement tous des ayants droits au regard du droit d’auteur. Tout comme cette expression désigne aussi par exemple les bénéficiaires des droits d’un affilié au régime de la sécurité sociale (enfants d’une famille, etc).
Juste un petit mot pour remettre les choses dans leur contexte.
#20
En meme temps ça a l’air dangereux, ya du noir et blanc et des grosses croix ! " />
" />
#21
Effectivement, nous sommes tous de potentiels ayant droits, mais quand les GAFAM automatise des traitement déréférencement/censure / vol de revenu au profit des puissant sans que j’en ai été informé au préalable ou sans possibilité de recours…
#22
wow, ils (google) n’auraient pas pu faire mieux pour donner de la légitimité à son article.
Bien joué Google !
edit : neutralité du net ? ya pas un soucis quelque part à faire chier le pékin lambda avec ses droits et ses devoirs sur internet quand des touts puissants peuvent se permettent se genre de choses ?
#23
#24
C’est d’autant plus vrai que bien souvent ce terme n’est pas utilisé pour parler des ayants droits eux-même mais plutôt des organismes chargés de collecter les droits en question.
#25
#26
#27
#28
Pour se rapprocher d’autres sujets, les robots (deep learning, etc) sont en train de dépasser les médecins pour les diagnostics (en progression) et à terme les remplaceront, ils décideront bientôt de qui sera embauché ou licencié dans les sociétés (en voie de progression), et dans notre cas, sont décideurs dans le domaine de la censure, car c’est bien de ça qu’il s’agit. Beaucoup d’inquiétude pour l’avenir en somme.
#29
Google est en train de scier sa branche…
#30
Pour apporter mes 2 centimes au débat:
#31
#32
Le Conseil des ministres de l’UE vote en faveur des brevets logiciels La deuxième étape du long processus de validation d’une directive européenne a eu lieu mardi. Le Conseil des ministres est revenu à la première mouture du texte, balayant les amendements apportés par les eurodéputés fin 2003. (24/05/2004) ………. “Il y a eu changement de fusil d’épaule car le bébé a été donné aux Irlandais. On voit que les lobbies ont bien fait leur travail. La démocratie est battue en brèche ! Nous allons désormais être soumis aux desiderata des puissances financières qui prennent le contrôle des brevets grâce à la complicité de l’OEB [NDLR : Office Européen des Brevets]. Il y a quelques années, on aurait parlé de haute trahison !”, déclare Bernard Giraud, président du SPECIS (Syndicat professionnel d’études, de conseil, d’ingénierie, d’informatique et de services). <http://www.journaldunet.com/solutions/0405/040524_brevets.shtml >
_____________________
Voici ce qui se disait en 2004. Aujourd’hui, nous y sommes, le fachisme s’installe !
#33
#34
#35
#36
#37
Parce que la loi le dit.
Je ne dis pas que c’est bien, juste que c’est comme ça.
Si les sanctions en cas de faux signalements étaient appliquées, on rigolerait plus c’est sur ^^”
#38
#39
#40
Huuum mais du coup, quid des alternatives? Qwant, duckduckgo…
Quand je suis pas satisfait par un service, autant se barrer. ça fait déjà longtemps que les voyants sont au rouge cramoisi au sujet de gogole, il est temps de filer à la concurrence, encore plus avec cette affaire.
Je trouve que qwant et duckduckgo font le taf pas si mal, pour moi à peine moins bien que gogole. ça fait déjà presque 2 ans que je fais une recherche gogole une fois toutes les 2 semaines.
#41
la loi vaut pour tous donc le problème sera le même donc …