
Backblaze propose depuis des années un bilan des pannes rencontrées sur les dizaines de milliers de disques durs que la société utilise dans ses datacenters. Depuis fin 2018, elle utilise également des SSD comme périphériques de boot. Le bilan 2022 de ces derniers vient d'être mis en ligne. Voici ce qu'il faut en retenir.
Comme toujours, la société utilise une méthode de calcul maison qui se veut plus « juste » qu'un simple pourcentage du nombre de pannes. Elle prend en effet en compte la durée de fonctionnement sur chaque période et parle d’un « taux de panne annualisé », ou AFR (Annualized Failure Rate), pour chaque référence de SSD.
AFR, Drive Days... : session rattrapage
Cela permet ainsi de faire la différence entre des SSD arrivés récemment et d'autres qui résistent pendant des années avant de rendre l'âme. L'AFR (un pourcentage) se calcule avec la formule suivante :
100 * (nombre de pannes / (jours cumulés de fonctionnement / 366))
Les jours cumulés de fonctionnement (ou Drive Days) correspondent à l'addition du nombre de jours de fonctionnement de chaque SSD d'une même référence. Ainsi, si 100 SSD ont fonctionné pendant 100 jours, cela donne 10 000 Drive Days (100 x 100). De même, 100 SSD en service durant 50 jours et 100 autres sur 200 jours (tous de la même série) donneront un Drive Days de 25 000 (5 000 + 20 000).
Sept références sans la moindre panne
Fin 2022, 2 906 SSD étaient utilisés dans les datacenters. L'entreprise reconnait que cela « représentent un nombre relativement restreint de périphériques sur lesquels effectuer une analyse et, bien que ce nombre conduise à des intervalles de confiance plus grands que souhaité, c'est un bon début ». Au même moment, Backblaze revendiquait plus de 230 000 HDD en service (stockage et boot confondus).
Sur les 2 906 SSD en service, l'entreprise annonce 934 000 Drive Days pour 25 pannes, soit un AFR de 0,98 %. C'est un peu mieux qu'en 2021 où le taux AFR était à 1,05 % (627 000 Drive Days pour 18 pannes) et qu'en 2020 avec 0,39 % (281 000 Drive Days pour 3 pannes).

Sept références de SSD ont un taux AFR à 0 %, signifiant qu'aucune panne n'a eu lieu l'année dernière. Par contre, six d'entre elles affichent « un nombre limité de Drive Days (moins de 10 000), ce qui signifie qu'il n'y a pas suffisamment de données pour faire une projection fiable sur les taux de pannes pour ces modèles de disque ». Comme sur les disques durs et de manière générale en statistiques, plus l'échantillon est grand, plus la marge d'erreur est faible.
C'est par exemple le cas des WD Blue SA510 de 250 Go qui ne sont que trois et installés pour un total de 102 Drive Days au cours des dernières années. Alors certes, l'AFR est à 0 %, mais l'intervalle de confiance oscille entre 0 et 1 320 %, ce qui est tout sauf significatif.
Les SSD Dell BOSS VD ne flanchent pas depuis des années
Les Dell BOSS (Boot Optimized Storage Solution) VD de 500 Go sortent du lot avec plus de 123 000 Drive Days (ce qui équivaut à 400 SSD environ utilisés pendant l'année complète) et aucune panne. Aucune panne n'était non plus identifiée en 2021 et en 2020, avec respectivement 63 700 et 31 500 Drive Days.
Ces données sont d'autant plus intéressantes que l'âge moyen des SSD Dell est d'un peu plus de deux ans. Backblaze précise par contre qu'il s'agit de « SSD M.2 montés sur une carte PCIe (HH-HL ou half height, half length) destiné aux déploiements de serveurs » ; ils ne sont généralement donc pas accessibles au grand public.
Le Seagate Barracuda 250 Go (ZA250CM10003) se tient bien
Pour le reste, trois SSD dépassent le cap des 100 000 Drive Days, une limite théorique que se fixe Backblaze pour avoir des données significatives. Sur l'année 2022, celui qui s'en sort le mieux est le Seagate Barracuda de 250 Go (ZA250CM10003) avec un taux de panne annualisé de 0,73 %. Sur 1 104 SSD en service (totalisant plus de 400 000 Drive Days), huit pannes ont été relevées.
C'est en légère hausse par rapport à l'année dernière où l'AFR n'était que de 0,66 % avec un Drive Days à 276 000. En 2021, aucune panne n'était relevée, mais le Drive Days n'était alors que de 47 000. C'est dans tous les cas un bon score pour Seagate avec moins de 1 % d'AFR sur trois dernières années. Depuis 2018, l'AFR est de 0,66 % avec un intervalle de confiance entre 0,3 et 1,1 %, soit un delta de moins d'un point.
Le Crucial MX500 250 Go (CT250MX500SSD1) redresse la barre
En suivant, on retrouve le Crucial MX500 de 250 Go (CT250MX500SSD1) avec un taux AFR de 1,04 % (un peu plus de 100 000 Drive Days avec 488 SSD pour trois pannes). Le score de 2021 avait de quoi faire peur avec un AFR à... plus de 43 %, mais avec un Drive Days à seulement 1 689, cela n'avait rien de significatif. Preuve en est le nouvel AFR de 2022.
« Les disques Crucial (CT250MX500SSD1) se sont bien rétablis en 2022 après avoir connu quelques défaillances précoces en 2021. Nous prévoyons que cette tendance va se poursuivre », précise Backblaze. Depuis 2018, l'AFR est à 1,7 % avec un intervalle de confiance entre 0,4 et 3,5 %, un delta important de plus de trois points.
Hausse des pannes sur Seagate Barracuda 250 Go (ZA250CM10002)
Enfin, la troisième référence est de nouveau un Seagate Barracuda de 250 Go (mais portant la référence ZA250CM10002), avec un AFR de 1,98 %. C'est le taux le plus haut de tous les modèles confondus. C'est une belle hausse par rapport à 2021 où le taux de panne annualisé n'était que de 0,36 %. Le Drive Days était du même acabit (204 000 en 2021 et 203 000 en 2022), mais avec deux SSD seulement en panne en 2021 contre onze en 2022, ce qui explique la forte augmentation du pourcentage.
Backblaze n'explique pas les raisons de cette forte augmentation, si ce n'est que le ZA250CM10003 est une nouvelle version du ZA250CM10002, notamment avec une consommation IDLE en baisse à 116 mW au lieu de 185 mW. Alors que le taux de panne du ZA250CM10002 est montée en flèche en 2022, Backblaze se demande si son grand frère suivra la même tendance dans les années à venir ou s'il va tracer sa propre voie. Affaire à suivre.
Sur l'ensemble des données de Backblaze (en remontant à début 2018, mais uniquement pour les SSD encore actifs au 31 décembre 2022), le taux de panne des SSD est de 0,89 %, en dessous de celui des disques durs qui est à 1,39 % (dans les mêmes conditions évidemment).

Des informations SMART pas très smart
La société profite de son bilan annuel de la fiabilité des SSD pour faire un détour par les informations SMART sur l'état de santé : elle a constaté « qu'il n'y a pas beaucoup de cohérence sur les attributs ou la dénomination que les fabricants de SSD utilisent pour enregistrer les données SMART ». C'est notamment le cas d'informations comme « wear leveling, endurance, lifetime used, life used, LBAs written, LBAs read... » qui manquent de cohérence entre les constructeurs ou qui ne sont parfois même pas enregistrées.
Il existe une exception : la température est une donnée à peu près stable sur les différents SSD, même si le Dell BOSS VD « ne rapporte pas de valeurs brutes ou normalisées ». Ces SSD sont donc exclus du bilan des températures de l'année 2022.
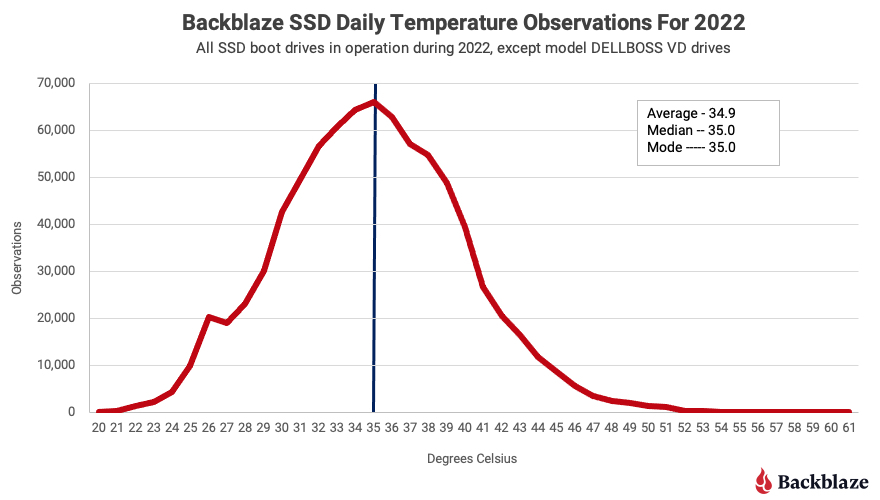
Des mesures allant de 20 à 60 °C, avec une moyenne à 34,9 °C
Backblaze récupère entre près de 60 000 et 80 000 relevés de température par mois, avec une moyenne mensuelle entre 34,4 et 35,4 °C ; soit à peine 1 °C d'écart entre le minimum et le maximum. La moyenne annuelle est de 34,9 °C, mais avec de grands écarts sur les mesures individuelles.
En effet, Backblaze a enregistré quatre fois une température de 20 °C sur ses SSD, et jusqu'à 61 °C (une seule fois). La médiane est à 35 °C, qui est donc quasiment identique à la moyenne. La courbe de répartition des températures prend la forme d'une cloche, comme celle que Backblaze retrouve sur les températures des HDD.
À titre de comparaison, la température moyenne des HDD sur la même période est plus basse avec 29,1 °C. « Cette différence semble aller à contre-courant de la croyance populaire selon laquelle les SSD chauffent moins que les disques durs [Dans le cas d'un usage et d'une installation de type datacenter comme le fait Backblaze, ndlr]. Une raison possible étant que dans tous nos serveurs, les disques de boot sont plus éloignés du couloir froid où se trouvent les HDD pour le stockage des données ».







Commentaires (26)
#1
Une donnée intéressante serait d’avoir une demi-vie par modèle. À l’instar des noyaux atomiques, cela correspondrait à la durée au bout de laquelle 50% des SSD sont en panne. On peut bien sûr prendre une autre valeur que 50%.
Car l’AFR ne donne pas ce genre d’infos (ou alors elle est cachée). Si par exemple, on achète 1000 SSD neufs du même modèle qu’on fait tourner un an, l’AFR indiquera seulement la probabilité de ces modèles de SSDs de tomber en panne la première année.
#1.1
Avec des taux de panne autour de 1%, la demie vie (théorique) risque d’être autour de 50 ans. À cet âge là, l’usure va indubitablement jouer un rôle avant. Mais on n’a pas assez de recul pour évaluer le vieillissement sur d’aussi nombreuses années, sans compter que ça n’a pas trop de sens, le matériel sera remplacé avant.
#1.2
Pas justement, non on n’en sait rien. Tu suppose que la courbe est linéaire mais rien ne le dit. On peut aussi imagine que le disque dur à une chance sur 2 de tomber en panne après 2 ans.
#1.3
Eh non, justement, je ne suppose pas. Je dis juste qu’on n’a aucun ensemble de SSD assez vieux pour arriver à 50% de défaillance, donc on ne sait pas, on ne peut pas savoir, et on ne saura sans doute jamais parce qu’il y a de grandes chances pour que les SSDs soient renouvelées systématiquement avant d’arriver à ce taux.
Mais bon, la demie-vie des atomes radioactifs, c’est une métrique qui marche justement parce qu’on a une exponentielle décroissante. Si ce n’était pas régulier, cette métrique serait bien foireuse.
#2
Comment expliquer l’intervalle de confiance de façon simple ? Est-que ça veut dire que si je mesure 1% d’AFR, et que l’intervalle de confiance est de 10, ce même AFR peut en fait avoir oscillé entre 0 et 10 au cours de la période mesurée ?
Si tu me dis : “J’ai à peu près trois grenouilles dans ma baignoire en permanence, mais l’intervalle de confiance est de 4” Ça veut dire que des fois tu as une grenouille, d’autres fois quatre, et d’autres fois pas du tout… non ?
Du coup, comment faire confiance à la valeur d’AFR, lorsque l’écart entre les intervalles de confiance mini et maxi est très élevé ? Est-ce qu’elle signifie alors encore quelque chose ?
#3
“Des informations SMART pas très smart”, c’est exactement ce que je remarque chez moi (et pourtant j’ai clairement bien moins de matos que BackBlaze).
#4
Normalement un intervalle de confiance est toujours associée à une probabilité. Par exemple on a 90% de se trouver dans l’intervalle de confiance donnée.
#4.1
Merci pour ta réponse. Donc l’idéal, ce serait une valeur élevée ? Mais si l’intervalle est de 1 (mini) à 10 (maxi) est-ce que cela veut dire : un chance sur 10 de se tromper ? Ou en d’autres termes : une mesure sur 10 n’est pas fiable, et peut induire en erreur ?
Pardon pour mon ignorance, je suis juste curieux et cette valeur m’interroge.
#5
Et aussi peut-être, vu que les tests et le marketing ont beaucoup communiqué dessus, les TBW et TBW à la panne?
#6
Si tu as un intervalle de confiance de ta mesure de température de (valeurs au pif) 10°C à 50°C à 90%, ça veut dire que 90% des températures sont comprises entre 10 et 50. En général, on aime bien avoir un pourcentage élevé et un intervalle faible.
Il est facile de dire qu’on a un intervalle de températures de 0°K à +infini°K à 100% mais c’est peu utile
#6.1
(reply:2123977:pamputt)
Merci pour vos éclairages Peut-être que l’auteur de l’article pourrait aussi donner son grain de sel ? …Ou pas, s’il n’a pas le temps, pas de soucis !
Peut-être que l’auteur de l’article pourrait aussi donner son grain de sel ? …Ou pas, s’il n’a pas le temps, pas de soucis !
#7
Bah, j’avoue que tel que c’est écrit, je n’arrive pas à interpréter la valeur non plus. J’ai regardé l’article source et il n’y a pas plus d’informations. Normalement, on devrait lire quelques chose comme
Depuis 2018, l’AFR est à 1,7 % avec un intervalle de confiance entre 0,4 et 3,5 % au niveau de 90%, un delta important de plus de trois points. au lieu de
Depuis 2018, l’AFR est à 1,7 % avec un intervalle de confiance entre 0,4 et 3,5 %, un delta important de plus de trois points.
J’ai mis 90% mais ça peut être n’importe quelle autre valeur. Dans ce cas, ça signifie qu’il y a 90% de chance que la valeur « réelle » se trouve entre 0,4 et 3,5 %.
#8
Dans un cours de physique, on apprend que toute mesure physique a un intervalle de confiance / une précision, et connaître cette précision est important, voire indispensable selon ce qu’on veut faire (apporter une preuve ou contre-preuve à une théorie, en particulier).
On peut voir sur les publications scientifiques, quand il y a des graphiques et des chiffres, l’intervalle de confiance (dessiné par une segment vertical autour des points ou de la courbe).
#8.1
En Finance, le même type de représentation est généralement utilisé: une courbe représentant l’évolution de la valeur moyenne d’une action par exemple sur plusieurs jours et pour chacune de ces valeurs moyennes, un segment vertical représentant les 2 valeurs min et max de chacune des journées.
Ça s’appelle des chandelles japonaises (et j’ai aucune idée du pourquoi du nom).
#9
Je n’ai pas eu la chance de faire de vraies études, donc tous ces éclaircissements me sont précieux.
#10
Quid du nombre de cycles d’écriture vs taille du disque ?
Cette info serait pertinente dans le cas des SSD, d’autant que cette valeur a tendance à diminuer à chaque nouvelle génération.
#11
Sur une flotte de 400 laptops équipés de disques durs (donc plus maltraités que des postes fixes) 3% tombaient en panne chaque année, c’était assez constant. Lors de la transition vers le SSD, nous n’avons plus constaté aucune panne pour défaillance de disque de stockage. Outre le confort d’utilisation, c’était une épée de Damoclès en moins, une vraie révolution pour les utilisateurs.
Par contre le talon d’Achille reste les TBW, une grappe raid 5 de Crucial MX500 sur un serveur esxi peu utilisé avait réduit les disques à 50% de leur espérance de vie en 3 ans environ.
Mais est-ce mieux avec les DD vendus pour 550TB écrits/lus par an pour 5 ans de garantie?
Par conséquent, il serait intéressant que Backblaze indique les TBW de ses SSD car peu utilisés en écriture comme dans un laptop, cela ne tombe (presque) jamais en panne
#11.1
Lorsqu’on avait encore des outils de monitoring installés sur les laptops du boulot, il y avait un point commun à la grosse majorité des pannes de SSD : remplissage du SSD à + de 90% en permanence.
#12
Dans les portables les soucis sont généralement plus dus aux chocs qu’à autre chose pour les HDD (la tête qui touche le disque). Les SSD étant insensibles aux chocs ça aide beaucoup.
En machine fixe, les HDD tiennent bien la route aussi :-)
#13
J’ai également remarqué un défaut sur 2 SSD Samsung 980 512Go (MZ-V8V500BW) avec les infos SMART. De manière totalement aléatoire, j’avais des relevés de température qui plafonnait à 84°C sur l’une des 2 sondes pendant quelques minutes (entre les 2 SSD c’était pas la même). Sans raison apparente et la seconde sonde restait à 35-40°C. Donc c’était clairement un défaut logiciel. Suite à une maj de firmware, il y a plus d’un mois (3B4QFXO7), je n’ai plus cette erreur.
D’ailleurs je confirme également que les données SMART collectées sur les SSD sont bien différemment affichées que les HDD classique.
#14
Marrant, je viens juste de faire un RMA sur un SSD samsung et l’article sur la fiabilité des SSD tombe.
Mon expérience personnelle:
Samsung dans le smart, je fais appel à la garantie si je ne vois pas “0” dans les valeurs:
#14.1
Samsung et Crucial ont de GROS problèmes dernièrement, ainsi que des accusations de malversation (genre le Crucial MX500 de 4 To serait en QLC, etc.)
Selon ce topic et quelques observations ici et là, je pense dire que les :
Crucial MX500
Samsung 870 EVO
Samsung 980 PRO
Samsung 990 PRO
de fabrication récente sont susceptibles de mourir prématurément. Toujours dans le topic d’ailleurs il semblerait que les 870 EVO sont maintenant produits avec un nouveau process depuis Novembre 2022.
#15
Ce qui est gênant c’est “Uncorrectable error count” puisqu’il s’agit d’erreurs détectées mais pas corrigibles. Les autres erreurs ça me semble normal que ça arrive dans la vie d’un disque, des erreurs sont détectées et les données sont réécrites ailleurs, c’est prévu dans le fonctionnement, et les compteurs permettent de savoir où on en est des réserves de blocs.
#15.1
En général quand l’une des erreurs commence à se montrer, son nombre augmente très rapidement montrant une défaillance.
Je n’ai pas eu le cas du SSD dont le smart montre un nombre d’erreurs “stables”.
Donc, dorénavant, dès qu’une erreur point son bout du nez, je ne cherche pas à comprendre (ni mettre en jeu des données) et je fais appel à la garantie car je n’ai pas envie de me retrouver avec des fichiers sur lesquels je travaille corrompus.
#15.2
J’ai un de mes SSD qui a eu des erreurs mais on est loin des valeurs qui posent problème, ça fait plus d’un an.
#16
Pour ces 2 là c’était à priori un bug de firmware qui a été corrigé depuis. La mise à jour empêche les problèmes futurs mais ne récupère pas l’usure passée (pour ça il reste la garantie).
Après ce sont les dires du constructeur, on ne saura jamais ce qui a vraiment été changé, et pour le 990 Pro c’est même encore un peu tôt pour valider le résultat vu que la correction a moins d’un mois.