

Le no-code est un concept peu précis que l’on pense nouveau et qui sert à vendre des logiciels. En tout cas voici l’idée que j’en avais avant de me dire que ça faisait un peu trop de buzz pour continuer à l’ignorer : il est donc temps d’en parler un peu pour découvrir ce que c’est.
On trouvera aussi NC/LC dans la littérature pour parler des solutions no code/low code, dont le concept est très proche, vous vous en doutez. On nous prome(u)t une programmation visuelle, avec peu ou pas de code, mais jusqu’où peut-on aller ?
Low-code et déceptions conceptuelles attendues
Bien que nos vendeurs favoris nous garantissent que l’avenir est dans le no-code, l’émergence concomitante du terme low-code nous laisse entrevoir des déceptions inévitables, avec une revue des ambitions à la baisse. Pour ma part, j’imagine très mal qu’un outil n’ait besoin d’aucune indication, aucune précision, ni aucune interaction complémentaire avec un humain pour fonctionner correctement ou faire correctement tout ce que l’on souhaite : cela signifierait que tous les cas sont prévus et qu’il serait possible de tout faire.
Il est donc fort probable que de petits ajustements soient nécessaires, par l’ajout de code ici ou là : on pourrait ainsi dire que le no-code serait une limite hypothétique à laquelle on tendrait grâce à des outils de développements qui autorisent un minimum de programmation.
Autre façon de voir les choses, le no-code pur pourrait se limiter à des réalisations simples et rapides, auquel cas il faudrait s’accommoder des limitations inhérentes aux environnements de développement proposés. Mais pourquoi pas : il n’y a pas mal d’usages de ce type possibles en entreprise. Donc soit on veut pouvoir tout faire, et il faudra rajouter du code à un moment ou à un autre, soit on reste dans un concept purement sans code et on sera limité par ce qu’on peut faire.
Autre déception conceptuelle attendue : on a beau dire que le no-code se fait sans code, en réalité c’est un raccourci fallacieux. Le no-code se rapporte en réalité à une programmation visuelle, sans écriture textuelle de code, mais qui représente néanmoins un algorithme qui reste, même avec une forme visuelle, un programme. No-code ne signifie pas no program. Les concepts utilisés resteront les mêmes, mais exprimés différemment.
L’espoir est que ces concepts soient accessibles et utilisés par des populations nouvelles, pour des raisons de gain de temps (« time-to-market ») mais aussi pour éviter certaines erreurs dues à l’éloignement fréquent des développeurs et des métiers, voire pour pallier le manque de main-d’œuvre, le marché de l’emploi en informatique restant assez tendu. Certains programmes d’automatisation trouvent aussi leur place : leur rôle étant d’automatiser des tâches souvent non scriptables (en passant par l’interface utilisateur), la programmation visuelle y trouvera aussi sa place.
Concept jeune ou vieux ?
En tant que vieux moi-même, je sais que ce concept n’a rien de nouveau : je me suis amusé avec des outils de ce genre – même si ça n’en portait pas le nom – dès les années 1990 (voir un peu avant). Sur Mac, il y avait le fameux HyperCard (et son concurrent SuperCard) créé par le génial Bill Atkinson, un outil payant au départ, mais ensuite rapidement distribué sur tous les Mac puis redevenu payant pour les développeurs.
Le principe était de proposer des piles (« stacks ») dont on pouvait concevoir visuellement l’interface graphique, avec la possibilité de coder des actions plus ou moins complexes dans le langage HyperTalk. Essentiellement graphique, on pourrait classer cet outil comme un des premiers outils de low-code. On pouvait y créer des jeux, des livres interactifs, des outils divers (généalogie, composition musicale, etc.) ainsi que des applications sérieuses avec des bases de données.
 Source : Blog de TheArchive.org
Source : Blog de TheArchive.org
Dans la même veine, et à la même époque, Adobe Authorware a pu proposer un équivalent, mais sa programmation en mode visuel se limitait souvent à produire des e-learnings (fonction aujourd’hui reprise par Captivate chez Adobe, mais sans que cet outil ne revendique spécialement être low-code).
Plus récemment, webMethods, une plateforme d’intégration d’application d’entreprise (EAI), utilisait une programmation essentiellement visuelle pour réaliser des tâches pouvant être complexes, mais orientées vers les fonctions d’un EAI (à savoir faire circuler les informations et créer des services au sein du système d’information d’une entreprise). Très souvent, des éditeurs de solutions BPM (Business Process Management) se sont orientés vers cette approche très adaptée pour la création et la mise en œuvre de flux métiers (“workflows”), révélant ainsi un cas d’usage tout trouvé pour ce type d’outil.

Exemple de « programme » sous webMethods : on y voit une séquence avec différentes tâches, conditions et boucles, sous forme visuelle. Source : documentation (site softwareag.com)
De nos jours, on trouve des outils low-code chez Microsoft, dans la longue suite d’outils associés à Office, avec par exemple PowerApps. Notez que Microsoft prend bien soin de parler de low-code pour ne pas trop induire ses clients en erreur.
Salesforce ou Zoho proposent aussi des outils low code pour rendre leurs offres encore plus attrayantes, et effectivement l’enrichissement d’un CRM via des petites applications « maison » est également un cas d’usage parfait pour ces usines low code. Du côté des RPA (Robotic Process Automation), on trouve UIPath ou Automation Anywhere, mais aussi Pegasystem, SAP, IBM etc.
À quoi ça sert ?
Le no-code reste de la programmation, ne nous y trompons pas. Par contre, il est évident que la façon de faire tend à rendre accessible la réalisation de programmes informatiques à une population a priori peu familiarisée avec le développement informatique classique, avec ses avantages et ses inconvénients.
Première cible : CRM et workflow
Par workflow, on entend une automatisation de tâches liées à son activité professionnelle, et souvent cela partira de la gestion de la relation client, ou CRM en anglais (“Customer Relationship Management”).
Il s’agira bien souvent d’utiliser une ou plusieurs sources de données pour en créer ou modifier d’autres. Exemple typique : importer des données d’un fichier .csv dans la « vraie » base client de l’entreprise, en vérifiant certaines conditions ou en enrichissant les données à partir des référentiels internes déjà existants.
On peut imaginer un collaborateur qui se déplace et qui n’a accès que périodiquement à son SI (système d'information), et qui note les infos de ses clients ou interlocuteurs sur un coin de table(ur) mais qui a besoin d’officialiser ses contacts. Ou sinon un site web réalisé à l’arrache pour une campagne de marketing, qui aurait recueilli (légalement) des informations sur des prospects, qu’il faudra à un moment ou à un autre faire rentrer dans la base.
Principes d’usage et de programmation
Avant, on requêtait via SQL, on chargeait via un script (ou un ETL pour les plus audacieux), on montait un projet, mais aujourd’hui on clique pour réaliser l’équivalent. Notons que cela diminue forcément le taux d’erreur, principalement dans le paramétrage.

Exemple sous Salesforce de déroulement d’étapes de création d’une application, tout en mode visuel (source : Salesforce)
Autre remarque importante : on voit bien que ces étapes sont génériques, et ne comportent quasiment aucune logique (au sens « métier »), parce qu’une fonctionnalité métier est souvent longue et complexe à décrire, et qu’on rentre alors dans les cas où la programmation visuelle n’apporte pas de gain évident par rapport au code classique. Certains audacieux ajoutent la possibilité de se connecter à un module d’IA pour aider à la décision, mais cela reste pour l’instant difficile à maîtriser.

Étape suivante : gérer le “workflow”, à savoir les suites d’actions à entreprendre, de façon automatisée mais pas obligatoirement (source : Salesforce)
Une fois votre workflow défini (dans votre tête), vous le construisez visuellement puis vous le faites glisser sur votre jolie application finale, et le tour est joué !
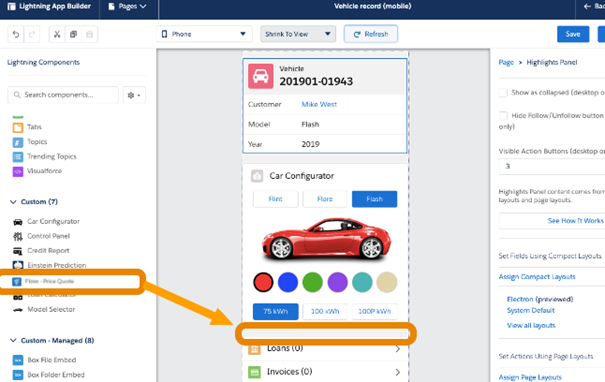
Et maintenant on glisse (source : Salesforce)
On voit bien que c’est joli, rapide, mais qu’on est obligé de faire des compromis : pour que tout soit « intégré », il faut accepter les modèles (« templates ») proposés par le produit sans chercher la personnalisation ou la performance à outrance. On ne va pas concevoir un traitement par lots de millions d’enregistrements par cette technique.
 Idem pour PowerApps : beaucoup de visuel, un peu de code
Idem pour PowerApps : beaucoup de visuel, un peu de code
En résumé, le low code se prête bien à certains cas d’usage :
- Création de workflows simples,
- Création de sites web peu complexes,
- Automatisation de tâches,
- Analyse de données, recherches marketing, aide à la création de modèles de machine learning etc.,
- Échanges entre SI et logiciels bureautiques,
- Prototypage d’applications.
La liste n’est absolument pas limitative, mais elle permet d’appréhender le type de réalisations possibles.
Vous êtes bien urbain, aujourd’hui ?
Les vendeurs de rêve nous parlent de programmation purement visuelle et de « citizen developers », dans le sens où tout un chacun peut développer une application, sans être du « sérail » ; mais il faut aussi retenir que la notion de citoyenneté implique des obligations et une bonne intégration dans la « société » (en l’occurrence l’entreprise), en suivant des règles d’urbanisme.
La corvée de l’administration de l’outil
Car comme la plupart des outils informatiques, on a en général besoin d’administrateurs techniques, même pour des solutions low-code, surtout si l’usage grandit. La maintenance dans le temps, l’intégration dans les SI, mais aussi la gouvernance (« dire comment l’utiliser et suivre l’usage ») et même le choix des outils doivent rester cohérents et maîtrisés afin de ne pas créer une jungle informatique dans l’entreprise. C’est ce qu’on appelle l’urbanisme en informatique, outil essentiel pour maîtriser la qualité, les coûts et la sécurité.
La sécurité
Souvent délaissée même quand on y est sensibilisé, la sécurité risque fort de pâtir du manque de formation d’une population qui n’est justement pas constituée de professionnels du développement. Et cela va de la sécurité des données, du respect du RGDP à la continuité d’activité. Un programme qui marche, c’est bien, mais il faut aussi savoir réagir en cas de panne ou d’attaque, et cela se prépare avec minutie, surtout lorsqu’on touche à une fonction critique de l’entreprise.
L’effet « shadow IT »
Plus c’est facile et plus on a tendance à en faire le moins possible. Faire un truc qui marche dans son coin, c’est bien, mais que se passera-t-il si le collaborateur part ou s’il est malade ? Que deviendra la valeur ajoutée du développement si personne ne sait plus s’en servir ou le faire évoluer ? Et si un produit exotique a été utilisé, comment le faire évoluer ou rapatrier le code en mode visuel (souvent spécifique à chaque produit et donc peu portable) ?
Laisser le champ libre à des non-développeurs ne veut pas dire leur laisser faire n’importe quoi, et donc un minimum de structuration et de formation sera indispensable pour cette population, qui ne doit pas échapper à une bonne gouvernance pour harmoniser et coordonner les pratiques de développement… Sinon effet silo garanti et fort risque de perte de la connaissance à prévoir : on aura un truc qui marche, mais on ne sait plus comment.
Pour finir
Ces outils ne sont pas magiques : ils sont utiles dans certains usages, mais il reste impératif de cadrer les usages (et les utilisateurs). Le no code ne signifie pas « autorisation de tout faire » : si on veut en tirer le meilleur, il faut que cela se fasse avec contrôle et avec une bonne gouvernance, et parfois de la formation. Le fait même que les utilisateurs ciblés ne soient pas des professionnels du développement fait courir le risque de mauvaises pratiques qui effaceraient le gain de la rapidité et de la fluidité de la programmation visuelle.





















Commentaires (42)
#1
Quelque soit l’outil “low-code”/“no-code” que j’ai testé récemment, on atteint vite les limites.
La plupart ne sont pas aussi complet que Access (Microsoft, vers 95), ou même Framework et DBase (je ne sais plus, milieu années 80).
Le meilleur que j’ai utilisé dans le sens “industrialisation possible” (et même grandement facilitée dans ce cas), c’était Cool-GEN, un AGL où il y avait du code, mais on devait cliquer même pour faire un “if”.
Franchement, je préfère un outil pour concevoir le workflow (camunda, rednode), et ajouter mes briques au besoin.
Pour les formulaires, rien à faire: hors outils hors de prix, actuellement je n’ai rien vu de convaincant pour faire du formulaire web, il manque plein de choses ou alors c’est ingérable.
Faire des formulaires FMS sur un VAX était bien plus efficace, en temps de réalisation autant que du point de vue de la consommation de ressources. Et bien plus facile à prendre en main par les utilisateurs.
Je trouve que la programmation Web me demande autant (pardon, plus…) d’effort même que l’assembleur: trop de technos superposées, trop de contraintes et d’imprévus, doc pas claire, cible mouvante…
Dans un contexte où j’ai l’habitude de faire des outils qui doivent durer des années, je trouve qu’on a fait un bond en arrière avec les technos du web en termes de maintenabilité, efficacité, et que pour faire du travail propre le besoin en formation et l’expérience requises sont énormes par rapport à du Winform, du terminal, du Java Swing ou AWT, du Qt, du GTK…
Et les plate-forme nocode se heurtent de plein fouet à trois murs:
Bref, je milite hardemment pour l’abandon du web en tant que plate-forme pour les outils d’entreprise, ou alors pour une vraie révision du HTML pour que les balises “INPUT” servent réellement à quelque chose d’utile sans nécessiter dix tonnes de code pour que leur comportement puisse être proche d’un composant de l’époque de Delphi 3 (mon RAD de référence, 1997)
#2
1992 pour la V1 de Ms Access.
Toujours indétrônable à mon goût pour une app réseau local.
Et déjà à l’époque on me disait “oui mais Access c’est pas du dev’”, mais quand je vois ce qu’on était capable de sortir en un temps record comparé aux développements plus conventionnels, et finalement qu’on se positionnait sur des gros projets… Bref!
Je me dis juste qu’il est fort dommage qu’ils ne l’aient pas “poussé” vers du web, ca l’aurait sauvé de sa lente agonie…
Power Apps est bien mais très austère à l’usage, et c’est une usine à gaz. De plus c’est loin d’être évident qu’il fonctionne sur la durée sans intervention humaine…
Bref on tente de réinventer la roue, mais comme à chaque fois, en y perdant au passage un bon lot de fonctionnalités…
#2.1
:tousse: :tousse: Fais une “app” Access “partagée” sur un lecteur réseau et on en reparlera…
spoiler : sauvegarde
#2.2
Déjà fait, plusieurs, avec des belles volumétries et un nombre conséquent d’utilisateurs, y’a des best practices à respecter, et les sauvegardes ne posaient pas de soucis.
#3
Ils l’ont fait … et retiré en 6 mois, sans possibilité de récupérer vers Acces ce qu’on avait migré sur leur équivalent web (le nom m’échappe).
Le 1er big fail que j’ai vécu avec office 365: le produit qui sort et disparaît en 6 mois, sans qu’on te donne une solution pour revenir à l’ancien…
Powerapps/powerautomate me sort par les trous du nez pour plusieurs raisons:
Toute l’histoire du Web. Un l’UI d’un outil comme Businness Objects peut sembler vieillote, mais quand on voit la complétude de l’interface d’administration Web, sa présentation claire et ordonnée, et la densité d’information qu’on y trouve, on se demande où on a bien pu se planter des 12 dernières années…
D’ailleurs en redémarrant un Atari ST il n’y a pas très longtemps, je me suis demandé comment on pouvait n’en n’être “que” là en 2022 quand on voit l’interface de 1987.
En fait, un émulateur ST sur le Web est plus léger que des pages de login… à se demander si on ne devrait pas utiliser un émulateur de machine de ce genre pour développer plus vite, mais à l’ancienne…
#4
Sujet très intéressant !
Je nuancerai cependant un point: les bonne pratiques, nécessaires autant pour « faire du code » que du no-code, ne sont pas plus innée chez les dev que les no-codeurs. C’est une rigueur à acquérir , un apprentissage, une courbe de progression.
Il existe de nombreux autres outils plus ou moins à la mode. J’ai mis un place plusieurs dizaines de scénarios avec Make pour automatiser nos commandes avec nos fournisseurs (API sur nos outils , extranets avec ou sans API chez les fournisseurs). On est plusieurs à savoir les maintenir, on track les erreurs, le fonctionnel est documenté. Est ce que c’est aussi fiable qu’une bonne intégration faite par un (bon) dev? Sans doute pas. Est ce que c’est plus rapide à mettre en place et moins chère à maintenir ? Oui.
#5
Trop tard pour édit : Oui, dans notre cas d’usage ;)
#6
Je connais pas du tout les logiciels et applications donnés en exemple dans l’article mais en électronique on trouve pas mal d’exemples d’IDE “low code” qui se revendiquent plus ou moins de ce terme.
Les “vi” de labview par exemple qui proposent de faire des programmes avec leurs interfaces graphiques notamment pour le pilotage d’instruments de mesure et de machines industrielles. Le tout en donnant l’impression de tracer un schéma de circuit électrique, ce qui rassure l’électronicien moyen
 (ça s’est un peu améliorer récemment). Dans le même genre il y a SimuLink de Matlab pour faire du traitement de signal, mais je connais moins.
(ça s’est un peu améliorer récemment). Dans le même genre il y a SimuLink de Matlab pour faire du traitement de signal, mais je connais moins.
Personnellement j’apprécie moyen labview avec son interface horrible
Un exemple que j’aime bien en revanche c’est appinventor du MIT qui permet de faire une appli android en quelques cliques, très sympa y compris pour les jeunes.
D’ailleurs je m’étonne que l’article n’aborde pas le NC/LC sous un angle plus large notamment de l’éducation/médiation où je trouve que c’est un outil formidable pour attirer et rassurer les élèves ou même un public plus large.
Mais du coup on s’éloigne peut-être du sujet ? Je ne sais pas
#7
99.9% des solutions low-code font de la programmation de flux (FBP: Flow-based programming). Et effectivement, ca n’a rien de récent.
Si ca revient à la mode c’est que le monde de l’informatique à jeté aux orties la FBP au profit de la programmation objet, ou pour les plus avant-gardistes la prog fonctionnelle et déclarative. Bref des principes de programmation pensés par des développeurs pour des développeurs.
Mais pas pensés pour des non-informaticiens. Car si on demande à un utilisateur lamnda de décrire son problème et comment il voit la solution, il dessine généralement des données et des activités reliées avec des flèches. Bref, il dessine un workflow.
#8
Sur ce point uniquement, c’est normal et souhaitable dans la stratégie de sécurité de MS.
Dans la philosophiee Zero Trust, les principes du “Just-in-time” et “Least priviledge” sont fondamentaux.
Ségréger les données aux seuls contextes utilisateurs qui exécutent l’application est typiquement la déclinaison de ces principes sur la stack Power : par exemple, sur PowerBI, il est possible de construire des dashboards accessibles à tous mais peuplée uniquement de données liée au contexte via Row-Level Security (ex : faire un dashboard pour les sales, qui peuvent voir leur résultats et quotas propre, sans voir celui des petits copains).
N’oublions pas que les PowerApps sont à la base conçues pour être executée en “espace utilisateur” M365, via son identité et ses données.
Pour ceux qui disent que PowerApps est trop limitée, pourquoi pas. Le produit est à destination des cellules d’innovation, des “power users”, et des business qui veulent prototyper une réponse à un besoin.
Pour les dev, il y a Azure Logic App, qui sera bien plus intéressant pour des gens qui ne veulent se concentrer QUE sur du code métier.
#9
je code très peu, mais c’est la même chose que du WYSWYG pour faire du site web en gros ?
#10
Le seul cas de no code qui me vient à l’esprit et que j’apprécie est scratch. Son intérêt pour l’apprentissage de la programmation est incontestable.
Par contre, la programmation labview qui ne s’adresse pas du tout à des électroniciens mais à des développeurs de bancs de test qui sont bien souvent des quiches en électronique, rend ses utilisateurs parfaitement captifs. Ceux qui savent manier la programmation spaghetti de labview sont bien souvent incapables de produire quoi que ce soit dans un autre langage.
Ils tentent souvent de se rassurer sur leur situation avec des diplômes en chocolat: « architecte labview » .
Ayant eu l’occasion (le malheur ?), de programmer un banc de test en CVI (un environnement labview en C), j’ai pu constater l’horreur de cet environnement où la gestion des erreurs est simplement un enfer si on cherche à faire un programme capable de récupérer tout ce qui peut mal se passer.
Labview est une belle usine à gaz où on aime dupliquer à l’infini du code super simple. Exemple avec les appareils de mesure équipés d’un port série ou GPIB dont l’utilisation est hyper simple avec les commande SCPI. Il suffit de deux fonctions pour travailler avec n’importe quel appareil mais les gens de Labview ont créé autant de « drivers » de de modèles d’appareils.
Tout cela pour vendre leur environnement en faisant croire que s’en passer serait du suicide.
En fait, on peut faire plus simple et plus rapide avec quelques lignes de python ou perl.
Dernier problème avec ce monde artificiel sans mots puisqu’il s’agit de faire disparaître les textes : les commentaires. Je ne trouve pas cela très sérieux.
S’il faut faire des power point avec des copies d’écran par centaines contenant des flèches et des boîtes de dialogue pour expliquer la conception, on est pas rendu.
#10.1
Je répondais pour ajouter à wanou mais j’ai perdu mon message. Je synthétise donc, n’hésitez pas à me relancer si questions il y a.
J’ai utilisé LabVIEW sans être formé puis été employé par National Instruments qui le développe (et j’ai été formé et vu la différence), j’ai vu les deux côtés.
Je pense que ce que j’en tire est probablement valable pour tout le no code. C’est intéressant pour du prototypage ou du proof pour concept. National Instruments fait une partie de son beurre sur les formations pour la simple raison que sans ça, le “code” est dégueulasse, illisible et non maintenable dès qu’il devient gros et dure dans le temps.
Ce sont des problèmes valables pour de mauvais dev en “textuel” (python, c++, etc), sauf que l’écosystème est plus fermé et que faire un diff c’est limite impossible.
Le seul point positif est que la marche est moins haute pour démarrer (je parle de difficulté, le financier…) par contre l’escalier ne mène pas aussi haut.
#11
J’ai travaillé un jour avec un énergéticien qui devait interfacer son modèle de batterie et de BMS sous Simulink avec un programme en C via une liaison série. La gestion de la liaison série faite sous simulink était plus volumineuse visuellement sur son projet que le modèle de la batterie et du BMS… C’était 10 lignes dans mon programme en C.
#12
et voilà. Je pense toutefois que les développeurs ont au moins été initiés aux bonnes pratiques et finissent par comprendre pourquoi ont leur a appris.
Mais en général sans une bonne maîtrise du formalisme. Et dans l’état actuel des choses, alors qu’avant un utilisateur arrivait à s’en sortir avec Access, avec les derniers nocode il y a des notions qui sont incompréhensibles par les utilisateurs.
La plupart ne réussissent pas à abstraire suffisament la technique, et les utilisateurs n’ont plus trop le bagage informatique de base.
Les “vieux” utilisateurs ont connu les menu en texte et les séquences de commandes à taper, les fenêtre standardisées.
Actuellement les utilisateurs sont perdus parce que aucun logiciel ne ressemble à l’autre, et souvent ils ont un effet “boite noire” énorme, qui empêche l’utilisateur d’appréhender le traitement sous-jacent des informations.
De mon point de vue, c’est un problème: des utilisateurs capables d’énoncer un traitement informatisé cohérent un peu plus développé que “j’appuie sur le bouton rouge et ding! voilà!” n’ont pas d’outil qui leur permet de se projeter, de mettre le doigt sur l’élément qui pose problème par eux-mêmes.
Je passe sur la complexité actuelle à faire communiquer les logiciels entre eux: avant onpouvait passer par le disque de l’utilisateur de façon à peu près transparente, maintenant vu qu’on n’a plus accès qu’à l’interface, à part en faisant du RPA on peut être pas mal coincé pour automatiser quoi que ce soit.
En bref, même avec du LC/NC, on se retrouve devant le mur du SAAS…
Oui, bien sûr, sauf que quand un utilisateur créé un workflow chez Ms, les développeurs ne le savent pas et ne peuvent pas y avoir accès: du coup si la personne est absente, ses collègues appellent la cellule informatique qui n’a pas de moyen de retrouver le flux et le déclencher pour eux…
C’est une grosse limitation du self-service de chez Ms: je ne suis pas contre le self service, mais Ms le tourne de façon à ridiculiser les équipes informatiques qui doivent passer par des super admin (ici: le directeur ou le chef des infras) pour débloquer des utilisateurs sur un truc qui leur paraît tellement simple…
#13
C’est marrant que l’article ne touche pas une énorme source de “no code” que sont les modèles de simulation ou les outils de spec formelle pour code embarqué (SCADE, Simulink, etc…). Une armée d’outils génère du code derrière pour aller le faire tourner sur un environnement de simu ou sur calculateur embarqué (avionique & spatial, etc…).
#14
J’aurais trouvé utile de citer les environnements de développement dédiés à l’enseignement et la découverte de la programmation par les enfants, scratch par exemple.
#14.1
Que ce soit l’énergie renvoyé par l’article (“Le no-code est un concept peu précis que l’on pense nouveau et qui sert à vendre des logiciels.” ) ou les commentaires qui rajoutent du contenu… si seulement chaque article/news pouvaient être ainsi (je parle surtout des commentaires).
) ou les commentaires qui rajoutent du contenu… si seulement chaque article/news pouvaient être ainsi (je parle surtout des commentaires). 
On peut aussi évoquer des jeux comme Minecraft avec les redstone mais on s’éloigne de l’article qui se veut “pro”.
#15
Ça inclut l création d’espaces, des bases de données et des traitements de données par exemple. Exemple: faire un portail de saisie des congés, avec l’enregistrement de la demande, des pièces jointes, la confirmation du maanager,…
#16
En plus des autres outils cités dans les commentaires, un petit tour via Node-Red aurait pu être intéressant
#17
Electronicien de formation, j’ai dû, il y a une vingtaine d’année déboguer un banc de test programmé sous Labview (création en 1986, au passage, ce qui ne nous rajeunit pas).
Je découvrais par la même occasion ce langage de programmation (c’est bien un langage, même s’il est graphique). Prise en main très facile.
Par contre, ce qu’avait fait le développeur était horrible.
7 ou 8 niveaux de boîtes imbriquées, avec des paramètres passés en tant que tels entre certaines boites mais écrits en dur dans certaines boîtes intermédiaires…
Ma conclusion:
#18
J’ai tendu le no-code pour mon application android :
Au début c’était vraiment super car t’a pas besoin de coder et c’est assez intuitif puis c’est cette même chose qui m’a aussi démotiver à ne pas continuer. J’aurais bien aimer pouvoir afficher le code et faire des copier coller en adaptant mon code.
Le plus gros problème reste la lisibilité en mode no code.
#19
Ah, IEF Cool-Gen ! On n’était pas vraiment dans du “low code”, à l’époque on parlait plutôt de Langage de 4ème Génération (L4G) et d’Atelier de Génie Logiciel (AGL) (oui, à “l’époque” on francisait encore car les accès et ressources internet étaient limités, et les modems chantaient encore lors des connexions à la toile). J’en garde un bon souvenir même si certains concepts étaient un plaie pour les habitués du codage à La Rach… C’était un environnement de conception semi-graphique qui générait ensuite du code pour différents langages (Cobol, C, Java) et diverses bases de données (DB2, Oracle). On pouvait même faire des “Écrans transactionnels” (IMS, CICS, ou pour Windows). Ça suivait plus ou moins le concept Java WORE (“Write Once Run Everywhere”, ou “… Repair…” selon certains
! On n’était pas vraiment dans du “low code”, à l’époque on parlait plutôt de Langage de 4ème Génération (L4G) et d’Atelier de Génie Logiciel (AGL) (oui, à “l’époque” on francisait encore car les accès et ressources internet étaient limités, et les modems chantaient encore lors des connexions à la toile). J’en garde un bon souvenir même si certains concepts étaient un plaie pour les habitués du codage à La Rach… C’était un environnement de conception semi-graphique qui générait ensuite du code pour différents langages (Cobol, C, Java) et diverses bases de données (DB2, Oracle). On pouvait même faire des “Écrans transactionnels” (IMS, CICS, ou pour Windows). Ça suivait plus ou moins le concept Java WORE (“Write Once Run Everywhere”, ou “… Repair…” selon certains  )
)
Sinon en LC plusieurs ont cité Scratch qui effectivement est un assez bon exemple de mon point de vue, et une excellente introduction à la programmation pour les plus jeunes et les autres.
En plus “pro” dans la série conception de Workflow et analyse de données il y a (avait ?) SAP BW, le module d’analyse multidimensionnelle de l’ERP, plutôt du genre clickodrome avec possibilité d’ajout de code simple pour l’intégration des sources de données.
#20
L’idée de l’article était plutôt de voir à quoi correspondait la vague marketing actuelle sur le no-code/low-code, pas de faire un état des lieux exhaustif. Simulink n’est pas vraiment dans cette vague marketing, et n’est pas non plus un outil à destination du plus grand nombre, c’est plutôt ce qu’on appelle un outil de niche, avec des fonctionnalités largement plus développées que ce que l’on trouve dans les outils estampillés “low code” comme PowerApps. Les commentaires sont d’excellents moyens de compléter cet article avec vos connaissances !
#21
Les outils c’est pas ce qui manque: https://github.com/topics/flow-based-programming
Ce qui manque c’est une standardisation: description du flux, interfaces E/S des activités, services transverses (accès aux données, écurité, paramétrage), contrôle/supervision. Chaque outil vient avec ses propres spécifications, ce qui fait qu’on se retrouve vite emprisonné/limité par l’écosystème choisi.
Il y a fort à parier que les outils des grosses solutions clouds (azure, aws…) vont devenir des standards de fait. Reste à espérer qu’ils offriront une forme d’interopérabilité, ce qui n’est actuellement pas dans leur intérêt (financier).
#22
J’ai pas vu beaucoup de soft qui me fasse autant l’effet wahou!
#23
Je l’ai bien remarqué à la vue des quelques exemples de labview que j’ai pu voir. La question est: peut-on faire des projets à la fois propres et d’envergure avec ce genre de langages ? Personnellement, j’en doute fort.
Les quelques outils dont j’ai eu besoin pour automatiser des manips électroniques ont été écrits par moi-même en perl ou en python. Commander un appareils en envoyant des commande SCPI sur un port série étant super simple. Cela va de la commande simultanée des deux sorties d’une alim bitension, la commande automatique d’une étuve avec relevés à chaque palier…
Pour le GBIB, c’était super complexe avec les interfaces de national instrument ou agilent mais super simple avec des appareils deux fois moins chers vus par le PC comme des port série.
Avec le LXI, c’est encore différent mais la difficulté matérielle (dispo d’un port série ou interface GPIB USB), disparaît.
Pour autant, ce type de programmes nécessitent pas d’être une brute en informatique car il ne s’agit pas de projets destinés à être maintenus et peuvent être écrits à 100% par une seule personne.
C’est vraiment l’équivalent du petit moyen d’essai câblé sur un coin de table.
#24
Il existe aussi toute une série de langages graphiques qui sont assez ancien (les années 1990) comme par exemple LabVIEW ou Simulink. Le premier est utilisé par les physiciens pour faire du traitement avec des entrées matérielles et le second est utilisé par exemple dans l’industrie automobile pour développer à haut niveau puis générer le code pour des cibles bas niveau (par exemple des microcontroleurs).
Chez les fabricants d’avion (Airbus, Boing, etc), le langage graphique SCADE est utilisé car il permet à des physiciens d’écrire par exemple le contrôleur de vol. Puis le code est généré (en C par exemple) pour un processeur. L’avantage est de pouvoir raisonner et tester (voire prouver) à haut niveau sans se préoccuper des problèmes de programmation (pointeur, ordre des calculs, etc).
#24.1
Et plus ancien encore (1977), il y a le grafcet.
#25
Oh purée le coup de pelle dans la tronche !
J’ai utilisé le grafcet sur l’écran à cristaux liquide d’un automate “académique” pendant ma seconde Technique des Systèmes Automatisés en 89-90… Effectivement bel exemple de no code
#26
Le grafcet reste l’un des 6 languages officiels des automates programmables à ma connaissance.
Il est très bien adapté aux machines d’état et peu servir pour documenter de manière assez accessible des machines implémentées dans des FPGA.
Du coup, pn peut tout autant le considérer comme un language NoCode que comme un language de modélisation comme l’UML
#27
Je débarque un peu après la bataille mais de mon côté les principaux enjeux sont en terme de sécurité et maintenabilité.
Je ne parle même pas de question de RGPD qui restent pour l’instant insoluble tant les principaux éditeurs de no/low -code ne prennent pas à coeur ce sujet ou sont basés dans des juridictions non compatibles.
#28
Sous Bonita studio ça utilise des diagrammes BPMN ce qui est un standard international pour modéliser des workflows/flux.
#29
Etant un grand fan de la notation BPMN, je ne peux qu’applaudir ce choix.
#30
Je suis le seul à me rappeler de Klik & Play ? C’est du nocode aussi, et en plus c’est français… (et ça a un lointain descendant encore maintenu)
#31
Pour contre balancer un peu avec tous les avis, on utilise dans ma boite énormément le no-code et low-code pour faire des landing pages, app mobile et plate-formes web. On s’en sert pour les MVP et v1.
On utilise pas mal Bubble, Webflow ou Airtable selon le contexte. Et également Zapier autant que possible.
Nous avons des spécialistes no-code et le gain de temps pour la partie front est de x4… Il n’y a clairement aucune concession à faire sur le rendu final.
En ce qui concerne le back, bien entendu ça ne remplace pas encore totalement de vrais développeurs.
#32
Bonjour,
En fait, c’est comme souvent un détournement de vocabulaire. Le low code ici vendu est en fait du high code (haut niveau, plus de vocabulaire, moins d’instructions) puisque sensé être plus proche des langages naturels (écrit, parlé, schéma, etc.). On oublie que même les messages que nous sommes en train d’écrire ici, c’est aussi avec un code (alphabétique), c’est pourtant un concept linguistique de base. Et du coup, on reste sous cette confusion (avec une grande responsabilité de l’anglais) entre codage et programmation.
Dans les années 70, le C était sans doute vu comme on nous vend le “no code” aujourd’hui puisqu’avec l’aide du compilateur il génère du code machine de bas niveau (moins de vocabulaire, plus d’instructions). Et qu’on pourrait même aller plus loin, quand on fait de l’informatique théorique, on peut démontrer que tout algorithme actuel tournant sur n’importe quelle machine numérique (en dehors peut-être des ordinateurs quantique) peut s’écrire avec des “+1” et “recommence”.
On pourrait bien entendu approfondir en vérifiant que les langages de plus ou moins haut niveau sont Turing Complet.
Pour pousser sur Scratch, je rappelle qu’il est algorithmiquement aussi Turing Complet que n’importe quel langage professionnel. Il propose juste un environnement de développement avec de nombreux outils accessibles pour gérer des choses qu’il faudrait programmer soi-même dans d’autres environnements, mais finalement cela reste le même principe que d’utiliser une librairie Pygames pour les programmer en Python. Quel développeur professionnel reprogramme lui-même ses fonctions de tri de liste ?
#32.1
Tout à fait d’accord/
Ceux qui pensent que Scratch est du no-code se trompent : on écrit clairement des algos dans un paradigme impératif. C’est juste que l’interface de saisie n’est pas le clavier mais la souris. Mais il faut maîtriser les structures de développement bien au-delà que le simple design d’un diagramme.
De façon générale, même les outils de RAD comme on a pu avoir (de VB6 au Delphi en passant par tous ces outils très à la mode entre la fin des années 90 et le début des années 2000) ne sont que des outils facilitateurs permettant de s’affranchir de tâches pénibles, dans la continuité des éditeurs de ressources qu’on avait dans les suites de développement de Borland dès le début des années 90, mais aussi déjà bien avant avec INTERFACE, l’éditeur de fichiers RSC sur Atari - et on avait l’équivalent sur les autres plateformes). On nous a aussi vendu la même chose côté bases de données (Access est ce qui est le plus connu pour le grand public, mais on a aussi Forms & Reports chez Oracle, etc.).
Enfin, même les outils qui se targuent de permettre de concevoir des applications avec des workflows complexes (comme par exemple ProcessMaker) ou les outils d’ETL comme Talend nécessitent à un moment donné de mettre les mains dans le cambouis en rédigeant des portions de code dès qu’on a besoin de faire du traitement de données un peu spécifique, qu’on doit utiliser une API ou un service distant exotique [et l’exotique est plus commun que le générique]).
Le souci de ces “monstres” est qu’ils finissent par manquer de souplesse et que dès qu’on doit faire face à une situation un peu complexe, il faut soit faire rentrer la réalité dans le cadre contraint par la techno, soit avoir des contorsions de la réalité en-dehors de l’application. À tel point que je connais plus d’une application qui, après avoir cherché pendant des années à entrer (en vain) dans un moule proposé par un environnement (SAP pour ne pas le nommer), ont fini par jeter l’éponge et fait le choix de solutions ad hoc plus adaptées à leurs besoins.
#33
Cela m’est arrivé pour optimiser un gros algo très consommateur de listes
#34
Ah, tiens, HyperCard et Authorware. C’est vrai qu’un domaine où l’on utilise ce genre d’outils, c’est en pédagogie. Et plus particulièrement le numérique en éducation, où des (futurs) profs voudraient utiliser le numérique en classe et créer des choses sans être forcément devs.
Dans l’université où je bosse, avant Internet, ils utilisaient beaucoup ces deux logiciels. Maintenant, c’est + orienté web, évidemment. On utilise aussi PowerApps, enfin plutôt via Power Virtual Agent, pour les chat bots. Et des trucs qui s’éloignent un peu de ce qu’étaient HyperCard et Authorware, comme Genially et Kotobee Author (pour les syllabus interactifs et e-books).
#35
Concrètement comment “sécuriser” du code informatique dans des solutions qui l’abstraient autant que possible ?
Ou alors la sécurité dans ce domaine passe par d’autres vecteurs ?
#36
Sinon ça arrive que les équipes utilisent pour des landings pages web en front et c’est assez efficace surtout pour du “jetable” (landing promotionnelle, offres temporaires, etc.)