

Chaque trimestre, Backblaze publie son bilan des pannes sur les dizaines de milliers de disques durs et les « quelques » SSD qui tournent dans ses datacenters. Des chiffres qui permettent d’avoir une idée de l’endurance de plusieurs modèles allant de 4 à 16 To.
Pour choisir un disque dur, il faut évidemment prendre en considération plusieurs paramètres : capacité de stockage, caractéristiques techniques (cache, débits, vitesse de rotation, etc.) et l’endurance. Sur ce dernier point, les fabricants promettent parfois monts et merveilles, mais il n’est pas facile de trier le bon grain de l’ivraie.
- Composition, technologies et fonctionnalités : on vous dit tout du disque dur moderne
- L’extraordinaire évolution du stockage
Plus de 190 000 HDD et près de 2 000 SSD
Avec 194 749 périphériques de stockage en fonctionnement au 30 septembre, Backblaze est un gros consommateur de disques durs et de SSD (dans une moindre mesure). L'entreprise a donc un point de vue intéressant sur le sujet.
Dans le lot, 3 537 périphériques permettent aux serveurs de démarrer – avec 1 557 HDD et 1 980 SSD – tandis que les 191 212 restants servent au stockage des données. Certains modèles utilisés pour des tests ou avec moins de 60 références en service sont exclus du périmètre de l'analyse livrée régulièrement par le service.
Pour rappel, sa méthode de calcul est un peu particulière, mais se veut plus « juste » : elle prend en compte la durée de fonctionnement des périphériques sur la période et parle ainsi d’un « taux de panne annualisé », ou AFR (Annualized Failure Rate). Elle se calcule avec la formule suivante :
100 * (nombre de pannes / (jours cumulés de fonctionnement / 366))
HGST s’en tire avec les honneurs…
Une seule référence n’a connu aucune panne sur le troisième trimestre : le disque dur HUH721212ALE600 de 12 To de chez HGST. Il y en avait 2 600 en service dans le datacenter d’Amsterdam de Backblaze, avec un âge moyen de deux ans. Cette gamme obtient donc l’AFR le plus faible : 0 %.
HGST est également sur la seconde marche du podium avec son HMS5C4040BLE640 de 4 To qui obtient 0,19 %. Il en est de même pour la troisième place avec le HUH721212ALE604 de 12 To. De manière générale, le fabricant s’en sort très bien avec un AFR de 0,51 % au maximum.
Chez WDC aussi les taux sont assez faibles avec 0,38 et 0,44 %, mais la société n’est présente qu’avec deux références de 14 et 16 To, pour un total de moins de 10 000 disques durs. Les pourcentages grimpent un peu avec Toshiba à 0,78 % pour le MG07ACA104TA de 14 To et à 2,11 % pour le MG08ACA16TE de 16 To :

… contrairement à Seagate
Enfin, chez Seagate, la situation est ce trimestre encore plus mitigée. Il y a d’un côté le ST6000DX000 de 6 To à 0,45 %, tandis que de l’autre on retrouve le ST12000NM0007 de 12 To à 5,06 % et même le ST14000NM0138 de 14 To avec 6,29 %. Ce sont les deux plus mauvais scores du trimestre.
Suite à un taux d’échec important, Backblaze avait annoncé en janvier 2020 que le modèle de 12 To devait disparaitre de ses datacenters l’année dernière, mais la crise sanitaire est venue jouer les trouble-fête. Tous les disques devraient désormais être remplacés pour le quatrième trimestre 2021.
Concernant les 14 To, ils sont fabriqués par Seagate, mais directement vendus dans des serveurs par Dell. Les trois protagonistes enquêtent donc pour essayer de comprendre ce qu’il se passe.
Backblaze en profite pour dire de nouveau « bravo aux disques durs Seagate de 6 To (âge moyen de 77,8 mois) et Toshiba de 4 To (âge moyen de 76,6 mois), car ils restent bons sur la durée ».
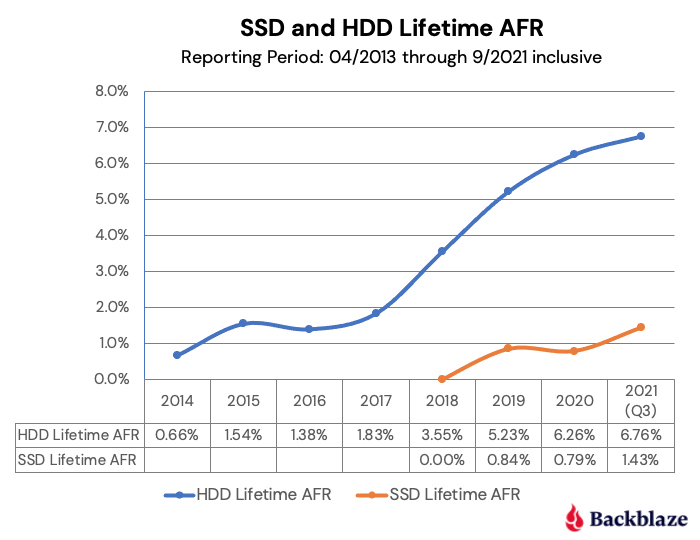
HDD vs SSD : fight !
Comme il utilise les deux types de solutions, l’hébergeur propose depuis peu une comparaison de l’endurance globale des disques durs et celle des SSD. Première analyse : la forme générale de la courbe entre les SSD et les HDD est plus ou moins la même, avec un taux de panne globalement plus bas pour les SSD.
« Compte tenu de ce que nous savons des pannes de disque au fil du temps, il est raisonnable de supposer que les taux de panne des SSD augmenteront à mesure qu'ils vieilliront ». La question est maintenant de savoir dans quelle proportion et si les SSD dépasseront les HDD… Réponse dans les prochains mois et années.





























Commentaires (31)
#1
Merci NXI.
Ces rapports sont toujours très intéressant.
J’avais été marqué il y a qq années suite à 4 HDD Seagate de mon NAS tombés en panne sur 3-4 mois.
C’est dans ces moments là qu’on regrette de ne pas avoir installer avec une tolérance sur 2 HDD
Depuis c’est Toshiba only et je suis satisfait.
Je constate que Seagate fait toujours de la “merde”.
#2
HGST encore et toujours les plus fiables, qu’il est loin le temps des desktar 75GXP !!!
Par contre seagate ils ont rien appris avec les ST3000DM001 d’il y a 10 ans on dirait…
Toujours intéressant ces stats
Juste dommage que le champ de tests ne soit pas plus large (il n’y a pas de disques SMR testés j’ai l’impression et il y a peu de WD testés dans l’absolu)
#3
C’est marrant comment le vécu et le “feeling” peuvent biaiser la réalité : tu trouvera des personnes ayant eu des problèmes avec toutes les marques et les blacklistent par “affect”, alors que globalement j’ai l’impression qu’elles se valent toutes plus ou moins sur le côté perf/qualité.
Personnellement, ayant eu des merdes sur du Seagate il y a 20ans, je suis passé sur WD et je n’ai jamais eu de souci.
Toshiba je crois que j’ai eu des soucis sur un laptop il y a une 15aine d’année mais je suis même pas sûr.. de toute façon j’ai (sans trop de raison) jamais eu de feeling avec la marque.
A côté de moi j’ai un collègue qui a eu un souci a eu un souci avec un WD il y a 10ans, depuis il ne jure que par Seagate…
Sans compter ceux qui n’ont jamais eu de souci avec une marque, et qui du coup n’essaient pas les autres
Comme quoi des fois le cœur a ses raisons que la raison ignore
#4
+1 sur les ressentis parfois contre toute logique.
Depuis que mon disque dur 40go WD a lâché, j’ai plus voulu acheter cette marque et pourtant les chiffres parlent d’eux même, ils ont des faibles taux de panne.
J’ai pratiquement plus que du samsung depuis, et je touche du bois, aucune panne depuis presque 10 ans pour le plus vieux disque.
Mais ce qu’on peut aussi voir, c’est que mauvaises séries mises à part, les disques durs sont quand même avec des taux de pannes extrêmement faibles.
Mais il ne faut pas oublier non plus que l’usage dans un serveur c’est pas l’usage dans un PC personnel.
Il y a sans doute beaucoup moins de variations thermiques par exemple. Dans le serveur le disque démarre, et il tourne ensuite 24⁄24 dans un environnement relativement constant.
Le nombre de cycles démarrage/arrêt n’est sans doute pas le même non plus. Même si pour des raisons d’économie d’énergie le disque se met en veille, on éteint pas le serveur le soir pour le rallumer au matin.
Mais HGST semble quand même dominer sur le critère de la fiabilité. Quelqu’un sait si ces disques sont bruyants à l’usage ? (c’est pour ma liste de noël )
#5
D’où l’importance du rapport de Blackblaze : nous ne sommes plus ici dans l’affect. Quand tu fais des stats sur 195000 disques, on en tire un enseignement quant à la fiabilité des différents modèles des différentes marques.
#6
Même constat il y a quelques années sur les Seagate (2 qui ont claqué à 2 semaines d’intervalle. J’ai eu plus de chance que toi…)
Depuis, je tourne avec des Western Digital, et j’en suis bien content.
Je tente de ne pas prendre des disques de même série pour une même grappe RAID (ça peut éviter le coup du “tous mes disques ont lâché en même temps” 😬 )
Et oui, pour Seagate, c’est triste de ne pas les voir revenir à leur gloire d’antan :/
#7
Oui, c’est toujours intéressant, après il existe des mauvaises séries aussi sur certains modèles. J’ai eu l’occasion de voir ça, avec un taux de panne de >30% sur les premières semaines d’usage en datacenter, plusieurs centaines de disques remplacés et les même disques/modèles qui étaient là a quelques semaines d’intervalle ont vécu >4ans de travail acharné avec un taux de panne “standard”. En moindre mesure, sur grand parc informatique, on a eu la même avec des SSD, qui suivant le firmware claquaient sans signe avant coureurs.
#8
Plutôt que de changer de marque, avec toujours le risque de tomber sur un défaut, je panache les marques de disques.
J’avais monté mon premier RAID avec les fameux IBM Deathstar et au bout de deux mois je ne pouvais plus reconstruire le disque. Depuis j’ai bannis les RAID homogènes. Cela fait plus de 20 ans et je n’ai plus jamais perdu de données à la fin de vie d’un disque.
#9
C’est pas faut :)
Et effectivement c’était des HDD 3TO acheté en même temps pour remplacer des 1TO.
N’empêche… ça fait râler et avec en plus la trouille de perdre tout le volume du NAS.
#10
Les seagate sont un peu moins chers et moins fiables que les autres, rien de nouveau sous le soleil finalement ça doit bien faire au moins 10 ans que c’est le cas.
#11
Il faut aussi appliquer une deuxième règle très importantes pour faire un RAID : mélanger les marques/modèles. Il n’est pas si rare d’avoir un défaut de fabrication sur une série entière et donc acheter X fois le même disque augmente énormément le risque de voir les DD mourir en même temps.
Mon dernier RAID est composé de DD acheté à gauche et à droite, c’est plus long mais j’ai la quasi certitude de ne pas les voir mourir ensemble (bon ça exclut les grosses pannes induites par le PC ofc).
#12
Oui mais Blackblaze utilisent ces disques dans un environement contrôlé. Ca donne des infos mais sur un environnement différent (même peut être ° de plu sou de moins) les résultats peuvent être différent.
Autrement pour les SSD ce serrait bien d’avoir la criticité de la panne. Un disque complètement mort avec impossibilité de récup les moindres données (RIP base bugzila) et un SSD où 10% seulement du disque est corrompu c’est pas la même histoire.
Surtout qu’a la reconstruction du RAID les anciens disques vont être particulièrement sollicités…augmentant d’autant plus la proba d’une panne.
#13
Dans un contexte d’entreprise, je ne pense pas que ça les intéresse. Quand un disque meurt partiellement ou complètement, il est dans un RAID, tu le jettes et tu le remplaces rapidement. Tu cherches pas forcément à comprendre la panne à moins que ça soit le 50ème du mois et du même modèle.
#14
C’est bien vrai. C’est sur 8 disques.
Depuis je remplace avec des 8To Toshiba à un rythme très lent.
Je changerais de marque à un moment peut être…
#15
Merci NXI pour cet article !
Je n’étais pas au courant non plus que Blackblaze faisait des bilans trimestriels de panne.
#16
Ça n’a rien à voir avec le sujet mais décidément, j’aurai tout vu passer avec les personal computers.

#17
Données toujours croustillantes :)
Je suis un peu aveuglément ce genre de stats quand j’achète des disques.
J’ai eu qu’un seul hdd WD Red sur 7 qui a merdé dès le départ en 8 ans. Un peu plus anciens, 2 seagates barracuda et 2 samsung f2 ecogreen avec des smart un peu mal en point. Et encore plus vieux 5 sasmung spinpoint f1 de 500go qui tournent toujours nickel. Je dois avoir un velociraptor encore…
#18
professionnellement, pour du NAS, j’ai eu plus souvent des soucis avant même l’intégration et une fois que c’est dedans cela roule. A part un WD 3 To qui a eu un petit souci de secteur défectueux au bout de 6 ans de bons et loyaux services et pourtant h24. J’avais fait un backup complet avant de changer le disque mais la reconstruction du raid s’est très bien passée. D’ailleurs un des 3 To commandés était complétement HS, testé à part avant l’intégration dans le NAS. Dans un autre NAS, c’était des 2 To qui avaient plus de 8 ans.
je ne sais pas si les nouvelles références sont plus ou moins fiables mais je trouve que ces références (1, 2, 3 et 4) tiennent quand même vraiment bien. Pas de recul sur les plus grosses tailles, un peu peur du temps de reconstruction et des risques de pertes.
Et personnellement, sur les différentes marques, je n’ai jamais vraiment eu de gros couacs (à part sur un modèle de Seagate) et pourtant, j’ai de très vieux coucous qui fonctionnent encore super bien (même en IDE), il faudra bien que je fasse du ménage un jour
#19
Non, bien sur, mais c’est juste pour dire que ce n’est pas parceque Backblaze a 0% sur le HUH721212ALE600 que dans une situation très peu différente ca va être la même. 1 seul petit degré pouvant, peut être faire changer les résultats.
#20
J’ai deux HGST de 12To (des HUH721212ALE064 extraits des disques externes WD XBOX Black achetés en Allemagne) et ils sont trèèès légèrement plus silencieux en veille. Si tu as un refroidissement par air, les ventilateurs feront globalement plus de bruit. En écriture linéaire/séquentielle, on entend pas les têtes sauf à être vraiment collé dessus.
En revanche, comme tous les disques, s’ils sont sollicités pour des écritures/lectures plus aléatoires, ça peut changer. Attention, rien ne garantit que tous les WD Black Xbox soient des HGST vu qu’on est quelques années après leur sortie maintenant.
#21
En général, dès que ça clignote tu changes le disque. Qu’il soit en panne à 1% ou 100% ne change rien.
Quand aux pannes de SSD, j’en ai vu 2, c’est mort subite
#22
Dans le NAS j’ai eu des pannes avec pratiquement toutes les marques. Du coup maintenant je panache au maximum.
Et comme une fois j’ai tout perdu car un deuxième disque est mort pendant la reconstruction je suis passé en tolérance 2 disques. Ça m’a valu de changer de NAS pour avoir plus de baie mais je dort mieux.
J’aime bien les rapport de blackblaze car ça permet d’avoir une idée sur la tendance. Du coup je m’en sert pour orienter mes achats de disque.
#23
Le coup de d’coeur c’est mieux que le coût de la panne.
J’en retire que plus la capacité relative grimpe plus la panne est probable.
#24
Les taux de pannes sont en général en octets lus/écrits, il est donc normal qu’un disque plus grand ai plus de risque d’erreurs.
Ce qu’il faut retenir c’est que surtout, la panne est plus impactante avec de grandes capacités.
#25
J’ai du Seagate, WD et Toshiba, et effectivement, mes dernières pannes, c’est sur Seagate. Un disque qui tombe en panne, échange standard en garantie. Un an plus tard, pouf, le même disque.
Je n’ai pas de RAID, mais par principe, quand j’achète un disque et son disque de sauvegarde, je panache les marques. Toujours.
#26
A voir le format des références WD, il ne fait aucun doute que se sont des HGST re-brandé
#27
pour moi, WD, c’est fini. 8 red 6To dans un NAS synology, 50% HS. deux en garantie, deux de ma poche.
#28
Tiens, dans mon ‘NAS’ j’ai un Seagate / Samsung Spinpoint M8 (1T 2 1⁄2) a 76339 heure de fonctionnement.
A 87660, je le met a la retraite !
#29
Impossible “de perdre tout le volume du NAS”, car comme tout le monde le sait, un raid n’est pas une sauvegarde. Et donc, tu a un (des) disque(s) externe(s) pour faire régulièrement la sauvegarde du raid. Perso raid + 2 sauvegardes externes.
#30
C’est là où c’est contradictoire : d’un côté il y a des erreurs d’écriture, de l’autre des pannes physiquement constituées.
Les premières rapportées aux secondes devraient “logiquement” prolonger la durée de vie du disque. Hors ! Le résultat final est invesement proportionel au nombre de corrections de L/E…
J’en conclus en fait que l’aveuglement des constructeurs n’est pas une vanne du coup de la panne : elle confirme leurs biais méthodologiques.
#31
C’est pas dans un NAS, mais j’ai aussi plusieurs samsung, soit dans un ordi de 2006 (démarré/arrêté quotidiennement depuis), soit dans des boitiers externes… Et je m’aperçois que autant j’ai eu des seagate/WD HS, autant (et malgré le nombre assez conséquent) les SAMSUNG de récup sont toujours actifs et sans panne rapportée.