

Ampere Computing semble peu à peu réussir son pari. La jeune société crée par Renée James après son départ d'Intel multiplie les annonces, partenariats et étend son empreinte dans le domaine visé : celui du cloud computing. Mais une fois passé le temps des promesses, vient celui des tests.
Il y a peu, Oracle Cloud lançait de nouvelles instances basées sur les processeurs Altra d'Ampere Computing : A1 Compute. Une petite révolution dans le domaine de l'hébergement cloud puisqu'ils intègrent pas moins de 80 cœurs ARM v8.2+ cadencés à une fréquence fixe (3 GHz ici), avec huit canaux de DDR4 et 128 lignes PCIe 4.0.
De quoi permettre un très bon niveau de densité, avec des performances du même niveau que ses concurrents de chez AMD ou Intel promet la société. Oracle Cloud y a vu une opportunité et mise fort sur une telle solution qui lui permet de se démarquer tout en proposant une alternative aux Graviton d'AWS à un prix raisonnable.
Mais dans la pratique, que peut-on attendre de ces instances ? Nous les avons testées pour le savoir.

Création du compte Oracle Cloud et gratuité
Avant de gérer des instances au sein d'Oracle Cloud il faut disposer d'un compte. Pour cela, il faut choisir un email et un mot de passe, mais pas seulement. En effet, vos nom, prénom, adresse et numéro de téléphone seront également demandés. Il faudra aussi fournir un moyen de paiement (Amex, Mastercard ou VISA, hors prépayé).
Un prélèvement de 1 euro est effectué pour vérifier son bon fonctionnement, il vous sera ensuite reversé. La procédure est contraignante, mais il y a une raison : la création d'un compte donne droit à différents niveaux de gratuité. Par défaut, il est d'ailleurs en mode « Toujours gratuit » vous assurant de ne jamais être facturé.
Vous avez ainsi accès à de nombreux services, dont la création d'instances, sans limite de durée. Les quotas sont bas sans être trop restrictifs. Vous pouvez par exemple créer une instance A1 avec 4 cœurs et 24 Go de mémoire. Les 30 premiers jours, vous avez également accès à 250 euros de crédits offerts, ce qui vous permet de dépasser les quotas sans risques de facturation. Nous avons ainsi pu créer une A1 à 16 cœurs et 96 Go de mémoire pour nos tests.





C'est donc pour éviter les abus que des vérifications sont faites. Sortir du niveau gratuit pour lever les restrictions, et par exemple pouvoir utiliser les 80 cœurs d'une instance A1 est un acte volontaire. Si vous le demandez, vous devrez à nouveau indiquer une carte bancaire qui sera cette fois utilisée pour vos futures facturations.
Une FAQ est disponible par ici. Notez que nous avons effectué nos tests depuis la zone d'Amsterdam, où il n'y a pas de problème d'approvisionnement en A1 (du fait de la demande importante). Aucun datacenter n'est présent à Paris.
Création de votre première instance
L'interface est par défaut affichée en anglais, mais elle est disponible en français. Elle donne accès à l'ensemble des services proposés par Oracle Cloud, dont la création d'instances. Vous pouvez leur donner un nom, les regrouper par « compartiment », préciser si vous voulez une instance à la demande, à capacité réservée, préemptive, etc.


Plusieurs images sont proposées, Oracle Linux étant celle par défaut. Par souci de simplicité et de comparaison, nous avons opté pour Ubuntu 20.04 LTS qui existe dans une version adaptée aux Altra d'Ampere Computing.
Indiquez une clé SSH, d'éventuels paramètres avancés (script cloud-init, chiffrement, tags, etc.) puis lancez la création. Vous obtiendrez alors une adresse IP publique, le compte à utiliser étant « ubuntu » dans le cas de la distribution de canonical. Pour Oracle Linux, c'est « ocp ». Pour rappel, la commande de connexion est la suivante :
ssh -i clé_privée.key ubuntu@adresse_ip
Altra vs Zen 3
Pour le moment, notre compte ne permet pas d'obtenir plus que 16 cœurs et 96 Go de mémoire. Nous avons demandé à avoir accès à la machine entière et ses 160 cœurs, ou au moins à un SoC entier avec 80 cœurs, mais cela prendra sans doute quelques jours avant d'être validé et que nos tests soient bouclés.
Nous avons donc effectué une première série d'essais nous permettant de positionner ces puces par rapport à l'un des processeurs pour serveur les plus performants du moment : l'EPYC 7313 (Zen 3). Pour cela, nous avons effectué des tests similaires sur notre HPE DL365 sous Ubuntu 20.04 LTS, avec 1 à 16 threads.
Attention, pour rappel, un processeur EPYC 7313 dispose de 64 cœurs physiques avec multi-threading, ce serveur peut donc gérer jusqu'à 2x 128 threads. 16 threads peuvent correspondre à 16 cœurs physiques ou 8 cœurs physiques et 8 cœurs logiques, ou un mix des deux. Dans tous les cas, nous avons laissé l'application testée et l'OS avec leurs paramètres par défaut et relevé les performances pour voir quels étaient les résultats obtenus.
Nous effectuerons des séries de tests complémentaires sur différentes instances et chez différents fournisseurs de services cloud dans le cadre d'un prochain article, une fois que nous pourrons exploiter plus de cœurs sur l'A1 d'Oracle.
Blender et rendu 3D
Commençons par l'un de nos tests habituels, qui s'adapte très bien aux processeurs avec un très grand nombre de cœurs : Blender. Nous utilisons ici la version des dépôts d'Ubuntu avec la scène Classroom. En effet, bmw_27 est trop légère lorsqu'il s'agit d'utiliser de très gros serveurs, montrant rapidement ses limites.
La commande utilisée est la suivante :
blender -b classroom.blend -E CYCLES -t $(nproc) -f 1
Voici les résultats obtenus :
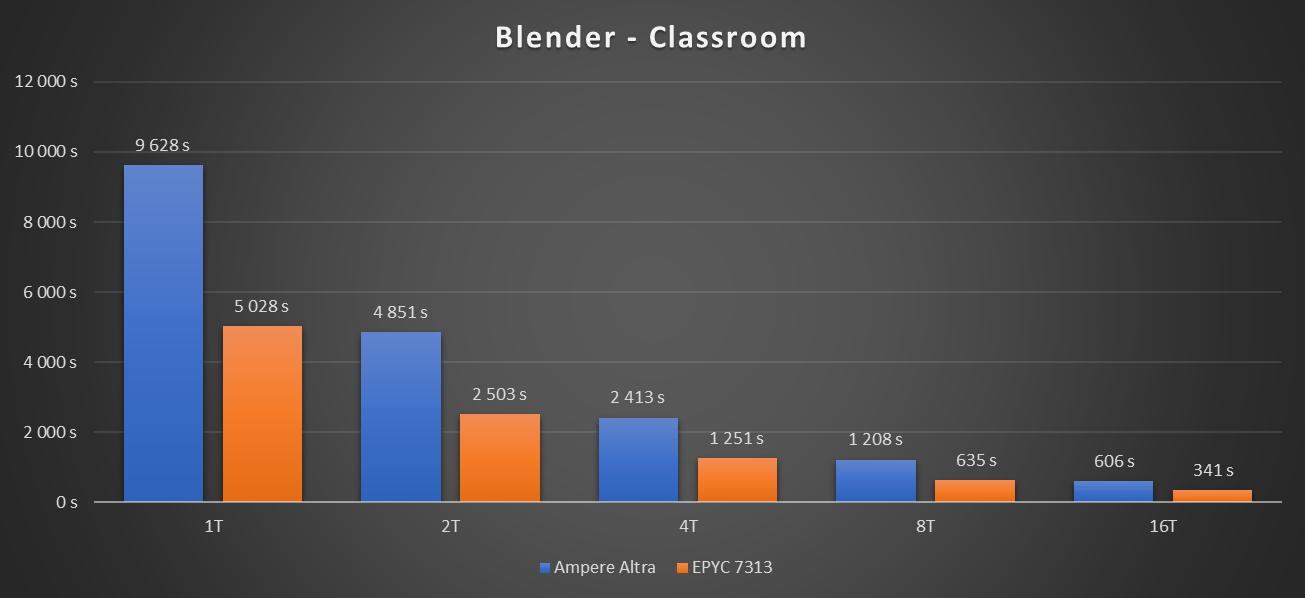
Sur un thread, le résultat est sans appel : l'EPYC 7313 est deux fois plus rapide que l'Altra-80. C'est tout de même un score honorable pour un tel processeur à l'architecture ARM misant principalement sur la densité. D'autant plus, qu'avec la montée en nombre de threads, l'écart s'amenuise.
Ici, l'Altra profite de sa fréquence fixe. Le temps de rendu avec 16 threads est 15,9x moins élevé que celui sur un thread. De son côté, l'EPYC 7313 voit sa fréquence baisser pour contenir son TDP, ainsi le ratio est de 14,7x.
(Dé)compression via 7-Zip
Passons à 7-Zip. Cette fois nous utilisons le benchmark intégré avec la commande suivante :
7za b 5 -mmt$(nproc)
Voici les résultats obtenus :
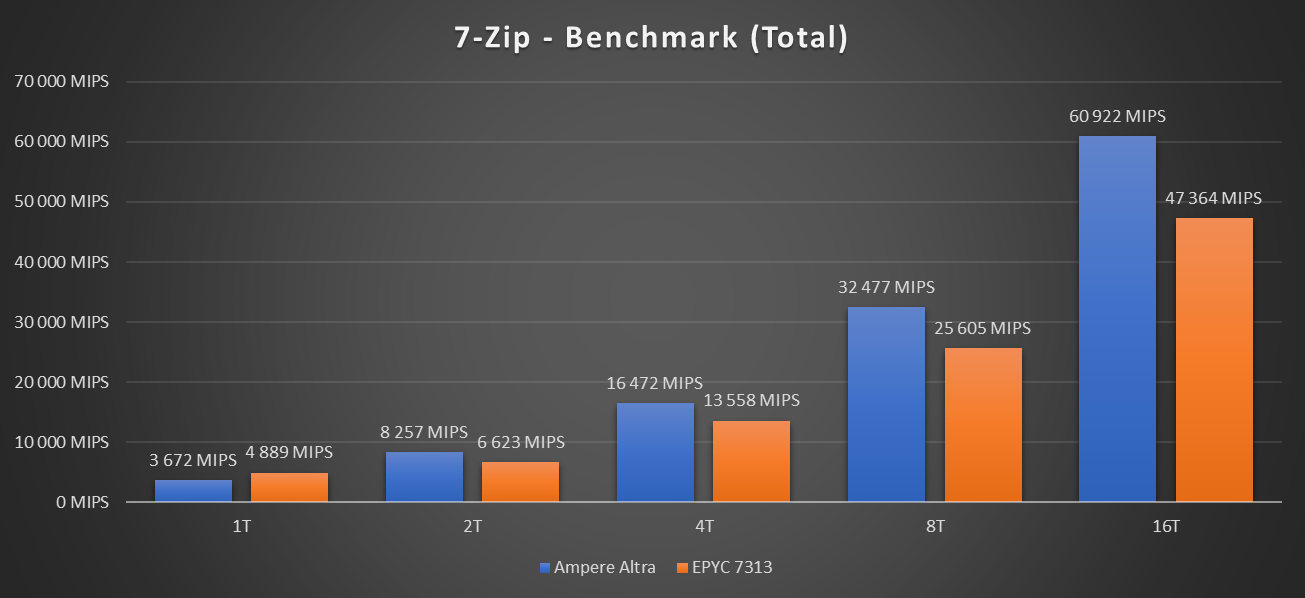
Cette fois, la tendance s'inverse, l'Ampere Altra semblant intégrer des unités de calcul profitant à plein dans une telle application. Tant en compression qu'en décompression le score est supérieur, et de beaucoup. Attention tout de même, il ne faut pas oublier que dans une telle situation, 16 cœurs physiques de l'EPYC 7313 ne sont pas forcément monopolisés, il sera intéressant de comparer les performances des processeurs utilisés à plein régime.
OpenSSL : une question de (dé)chiffrement
Au tour d'OpenSSL. Nous relevons le nombre de signatures par seconde (RSA 4096 bits) :
openssl speed --multi $(nproc) rsa4096
Voici les résultats obtenus :

Cette fois, l'Ampere Altra ne semble pas à l'aise. Cela peut venir d'un déficit d'accélération matérielle ou du fait d'une version compilée et utilisée dans les dépôts d'Ubuntu qui ne profitent pas à plein de son potentiel. Néanmoins, l'écart constaté est relativement important, indiquant qu'un problème est sans doute présent.
x264 : qui est le roi de la compression 4K ?
Finissons par une compression de vidéo via x264, ce qui était l'un des usages mis en avant par Oracle Cloud. Pour cela, nous avons utilisé ffmpeg avec la vidéo de Tears of Steel (4K, 6.9 Go) afin d'obtenir une version 1080p :
time ffmpeg -i tearsofsteel_4k.mov -c:v libx264 -vf scale=1920:1080 -y -stats bench.mkv
Voici les résultats obtenus :
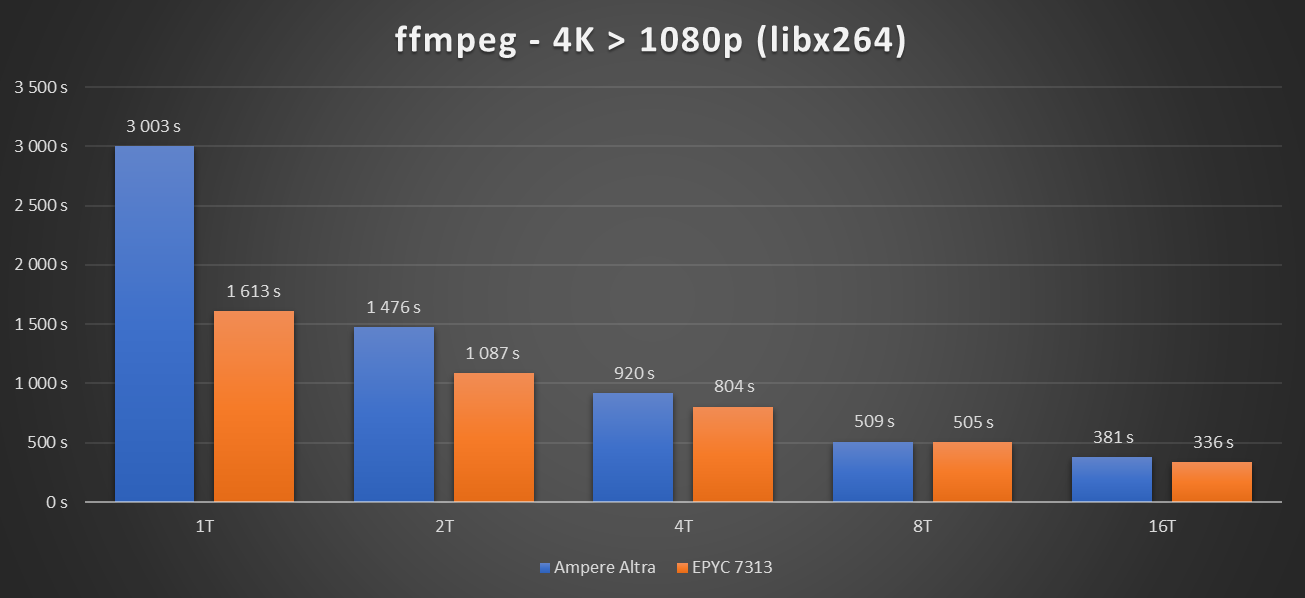
Tout d'abord, il faut noter que la compression vidéo est un type de calcul qui ne « scale » pas bien. On ne profite en général pas du plein potentiel des cœurs, certaines étapes n'occupant que peu d'entre eux. C'est un cas d'autant plus intéressant qu'il permet de tester les processeurs dans des conditions intermédiaires.
On peut aussi regarder quel est le potentiel d'une machine complète, de son CPU à sa mémoire en passant par le stockage, avec la compression de plusieurs flux en simultanées. Par exemple, sur notre machine HPE, on peut en effectuer six en seulement trois minutes, sans presque perdre de temps par rapport à la compression d'un flux unique.
Ici, nous avons au départ un résultat similaire à Blender : l'EPYC 7313 est deux fois plus rapide sur un thread que l'Ampere Altra. Mais au fil du temps, ils se rejoignent peu à peu, et à 16 threads, leurs performances sont presque similaires. Comme précédemment, il faudra tester le CPU complet pour se faire un avis plus précis.
Ampere Altra : déjà un très bon potentiel
Ces quelques tests montrent néanmoins que l'Ampere Altra semble déjà « ready for prime time » pour bien des usages et conviendra sans problème à ceux qui veulent simplement l'utiliser pour de l'hébergement, même si sa gestion d'OpenSSL semble ici à améliorer. Nous ferons des essais complémentaires pour éclaircir ce point.
Quoi qu'il en soit, les performances de cette puce sont plutôt bonnes, parfois à la hauteur d'un EPYC 7313. Certes, cela se fait avec un nombre de cœurs physiques supérieur, mais sa densité est aussi meilleure : 80 par socket contre 64 pour AMD, avec une fréquence non soumise à une mécanique de boost/turbo.
Autant dire que nous avons hâte de mettre la main sur un serveur complet avec deux CPU pour aller plus loin.
























Commentaires (12)
#1
Merci pour cet article super intéressant!
En revanche sur l’interprétation de ces résultats préliminaires je me permets de commenter vos analyses:
Blender
Il est vrai qu’en augmentant le nombre de threads l’écart se réduit, mais pas autant que ce que vous semblez entendre, en effet voilà les ratios en fonction du nombre de threads:
1T:1,9x; 2T:1,9x; 4T:1,9x; 8T:1,9x; 16T:1,8x.
x264
La tendance est en fait assez différente de ce qu’on voit pour Blender, voilà les ratios en fonction du nombre de threads:
1T:1,9x; 2T:1,4x; 4T:1,1x; 8T:1x; 16T:1,1x.
En traçant l’ensemble sur un graph, on voit bien que si l’écart à 16T est plus faible que l’écart à 1T dans les deux cas, dans le cas Blender on a en fait pas de tendance de 1T à 8T puis une chute en passant à 16T alors que sur le test x264 on a une chute rapide de 1T à 8T puis une remontée à 16T (quasi aussi importante que la chute entre 8T et 16T du test Blender).
J’ai tracé le tout vite fait et en comparant ces ratios ça saute aux yeux.
Encore merci pour ces mesures, et on est bien d’accord que ce sont des résultats préliminaires et je ne conclue rien non plus de définitif avec, mais je trouve juste que les résultats sont un poil différents d’une partie du texte associé je me permets donc d’y aller de mon commentaire
#2
Je ne sais pas ce que tu calcule comme ratio exactement (Altra/EPYC ?) mais je dis simplement que l’écart s’amenuise, ce qui est le cas. Ton calcul le montre d’ailleurs :)
De toutes façons, l’important à regarder c’est le rapport entre l’évolution du nombre de threads et les perfs. Globalement sur Altra le ratio suit le nombre de threads (il est conçu pour ça). Sur EPYC dans le cas de la machine testée c’est la même chose jusqu’à 8 ensuite ça se réduit, d’où le ration final à 14,7x contre 15,9x pour Altra (et ça empire avec la montée jusqu’à 256 #Spoiler)
Oui c’est exactement ce que je dis : au fil du temps les scores se rejoignent (mais comme on le voit sur le graphique ce n’est pas linéaire). Je ne comprends du coup pourquoi tu dis “en fait c’est assez différent de Blender” puisque je ne dis pas que c’est similaire, mais tout l’inverse.
C’est assez logique puisqu’une charge de compression libx264 n’étant pas //sable, le temps de compression se tasse avec la montée en threads. Les deux CPU ne le font pas au même rythme sans doute parce que pour l’un 1C=1T et pas l’autre comme expliqué.
#3
Je calcule le temps Altra / Epyc pour chaque nombre de threads affichés dans les histogrammes Blender et x264, pour savoir combien de fois Epyc va plus vite qu’Altra. De ton côté tu dis (corrige moi si je me trompe j’ai un doute) qu’Altra est 15,9x plus performant à 16T qu’à 1T tandis que pour Epyc c’est 14,7x, ce qui tend à démontrer qu’Altra scale mieux. De mon côté j’ai fait la comparaison pour chaque nombre de threads présentés d’un processeur par rapport à l’autre.
Ensuite tu dis que l’écart s’amenuise, je ne dis pas le contraire mais je dis juste que ce n’est pas probant avec l’échantillon mesuré indiqué dans l’article, car il stagne de 1T à 8T dans le cas de Blender (avec même une légère remontée à 2T si j’enlève l’arrondi à une décimale) puis une chute de 1,9x à 1,8x entre 8T et 16T. Je pense juste que pour voir l’effet du scaling de façon notable il faudrait effectivement des résultats avec plus de threads, là statistiquement, on ne voit rien du tout (mais tu le sous-entends déjà à la fin, mon intention n’est pas la critique).
Pour l’interprétation que j’ai faite du paragraphe concernant le la similarité x264 vs Blender, toutes mes excuses, j’ai bien relu et j’avais mal interprété: nous disons effectivement la même chose :)
EDIT: et réflexion qui vient de me venir: c’est assez contre-intuitif pour moi de voir qu’Epyc a justement “plus de mal” à maintenir l’écart (et de loin) en x264 qu’avec Blender. Une hypothèse ?
Sinon pour, et c’est tout à fait perso, je préfère le graph type “nuage de points” dans Excel pour représenter des données si on veut montrer la présence ou l’absence de tendance ==> les lignes aident visuellement (mais je dis ça juste pour discuter, n’y vois pas une critique du tout)
#4
Je dis que l’écart s’amenuise lorsque l’on monte en threads et effectivement il est plus faible à 16T qu’à 1T (et c’est normal puisque les CPU ont des conceptions/fonctionnements qui vont dans ce sens). Ce que je comprends, c’est que de ton point de vue la baisse n’est pas progressive.
Pou les graphiques en barre, c’est une habitude (puis on voit tout de même bien la tendance se dessiner), le nuage de points sur de telles données ça fait plus “vide”
Pour x264, comme dit, ça peut venir de la façon dont il gère les threads. Il suffit que certains soient des cœurs logiques sur EPYC ou que ça se ballade de cœurs physiques en cœurs logiques pour que ça ait un impact direct. C’est aussi pour ça que ce serait intéressant de comparer les CPU à plein (mais en fait comme c’est une machine physique je dois aussi pouvoir désactiver le MT pour vérifier).
Sinon, c’est aussi que la part non //isable du calcul prend une part croissante du temps de compression par rapport au reste avec la montée en threads. Tu arrives donc à un minimum qu’il est difficile de dépasser. Pour le comprendre il faudra attendre de voir le comportement à partir de 16T sur l’Altra. Sur l’EPYC on réduit le temps de compression jusqu’à 64T à peu près, est-ce que ce sera aussi le cas sur Altra ?
#5
Pour tester les capacités de traitement et la scalabilité des processeurs multicores. Je verse ce script de mon ami Zentoo qui traîne ici aussi.
https://framagit.org/Wax/zenbench
#6
Donc à part en comparant du point de vue énergétique, mais ce ne sont pas des machines pour fermes de rendu 3D…
D’un autre côté, ce sont des machines qu’on attend surtout côté BDD et web, sur des charges qui impliquent du réseau, du disque et un peu de CPU.
On sature peu des Xeon avec un serveur ou de la BDD:
Le moyen le plus facile de réduire l’impact des context switch étant d’ajouter des CPU, je pense que les machines ARM de ce type ont une place de choix dans les serveurs Web et d’entreprise du moment qu’elles assurent côté nombre d’IO/s.
L’autre intérêt du bench: on voit bien que le parallélisme de l’ARM est bien plus réussi que celui sur Intel: sur 16 sur Intel, on a souvent 10-14x la perf, plutôt 15x-16x sur l’ARM.
C’est extrêmement net 7zip qui s’écrase sur le x64 mis est presque linéaire sur l’ARM.
-> Cette linéarité est impressionnante, et d’extrêmement bonne augure: on peut se fier à la montée en charge CPU sur ARM, là où sur x64, une charge supérieur à 75⁄80% risque de faire un effet boule de neige et s’écrouler.
#7
HTTP 502
Attention quand même, certaines optimisations sont utilisées sans forcément être très mises en avant, même dans des usages classiques (de mémoire les derniers Xeon ont quelques optimisations compression & co qui devraient être exploitées pour Gzip par exemple).
Après comme dit, ces machines sont surtout appréciées pour leur densité (160 cœurs physiques par serveur 2S), tous avec le même niveau de performance qqsoit la charge du CPU. Mais il ne faut pas oublier qu’un cœur Altra ne sera pas équivalent à un cœur EPYC/Xeon ou autre.
Attention aussi à ne pas tirer de fausse conclusion (surtout quand c’est explicité dans l’article, lire avant de commenter sur la base des seuls graphiques peut être utile). La baisse de performance côté Zen (parce que je ne teste pas d’Intel ici), c’est principalement du au Turbo, pas à un problème de gestion des threads. Idem pour 7Zip ou comme expliqué, cela peut aussi venir de la manière dont les threads sont répartis sur les cœurs physiques/logiques pas d’une mauvaise gestion du //isme.
La solution utilisée par ARM est intéressante de ce point de vue, mais elle peut être aussi mise en place côté x86 (en désactivant le Turbo et le Multi-threading). On verra sur une machine complète comment Altra scale et gère la problématique de l’échauffement.
#8
Je viens de réessayer, ça fonctionne pourtant.
#9
Framagit était en maintenance de 8h15 a 8h28
https://framapiaf.org/@FramasoftStatus/106373690742670512
#10
Je souligne surtout que la machine ARM est “prédictible”: sur tous les graphs, on est très proche du rapport de 1 à 16 pour ARM, contre entre 1 à 15 et 1 à 10 (7zip) pour l’intel.
En gros, si sur x64 multiplier les core par 2 c’est augementer les perfs de 80% en moyenne, il est bon de le savoir.
#11
Oui, comme dit dans l’article ;) (sauf libx264 qui montre ses limites rapidement)
#12
C’est très encourageant pour ARM en effet, mais je crois que pour beaucoup ce qui va faire pencher la balance c’est le rapport performance/prix.