

Et si RTX Voice n'était pas réservé aux GeForce RTX et à leurs Tensor Cores ? En pratique, cela semble bien être le cas, la seule limitation mise en place étant au niveau du processus d'installation.
La semaine dernière, NVIDIA diffusait un petit outil simple, mais fort utile : RTX Voice. Il permet en effet de réduire les bruits ambiants dans n'importe quelle application, aussi bien au niveau du micro que du casque, en exploitant un modèle issu d'un réseau de neurones, appliqué en temps réel.
Ce n'est pas le premier du genre : Intel a déjà fait des démonstrations en ce sens, Discord vient d'annoncer l'intégration d'un outil tiers (Krisp.ai), etc. Mais RTX Voice semble déjà plutôt efficace et fonctionne sur différentes applications même si toutes ne le gèrent pas encore très bien (Skype pose quelques problèmes selon nos essais).
Surtout, on peut l'utiliser pour réduire les nuisances tant au niveau du micro que des enceintes ou des écouteurs, ce qui est un avantage non négligeable si le bruit vient de votre interlocuteur par exemple.
Comme son nom l'indique, cette fonctionnalité était réservée aux GeForce RTX et leurs Tensor Cores assurant l'accélération matérielle de tels calculs. Lors de l’annonce, nous regrettions qu'il soit impossible d'en profiter tout de même sur des GeForce GTX, quitte à disposer d'une expérience dégradée, surtout que la charge de travail ne doit pas être si importante rendant d'autant plus inutile une telle segmentation.
Depuis, certains ont remarqué que la limitation aux GeForce RTX n'était pas intégrée à l'outil lui-même mais seulement à son processus d'installation. Ainsi, il est tout à fait possible d'installer RTX Voice sur une machine ne disposant pas d'une telle carte graphique. Pour cela, il suffit de décompresser l'exécutable récupéré avec une application telle que 7-Zip. Puis, de modifier le fichier contenant les paramètres de l'installeur : NvAFX\RTXVoice.nvi.
Un simple éditeur de texte suffit. Il faut retirer les lignes suivantes :
<constraints>
<property name="Feature.RTXVoice" level="silent" text="${{InstallBlockedMessage}}"/>
</constraints>
Une fois que c'est fait, vous pourrez installer RTX Voice sur une machine équipée d'une GeForce, GTX ou RTX. Pour cela, rendez-vous à la racine du dossier et lancez setup.exe. Cela fonctionnera même si vous n'avez pas une une carte graphique NVIDIA, mais elle sera nécessaire pour l'activation du denoising.
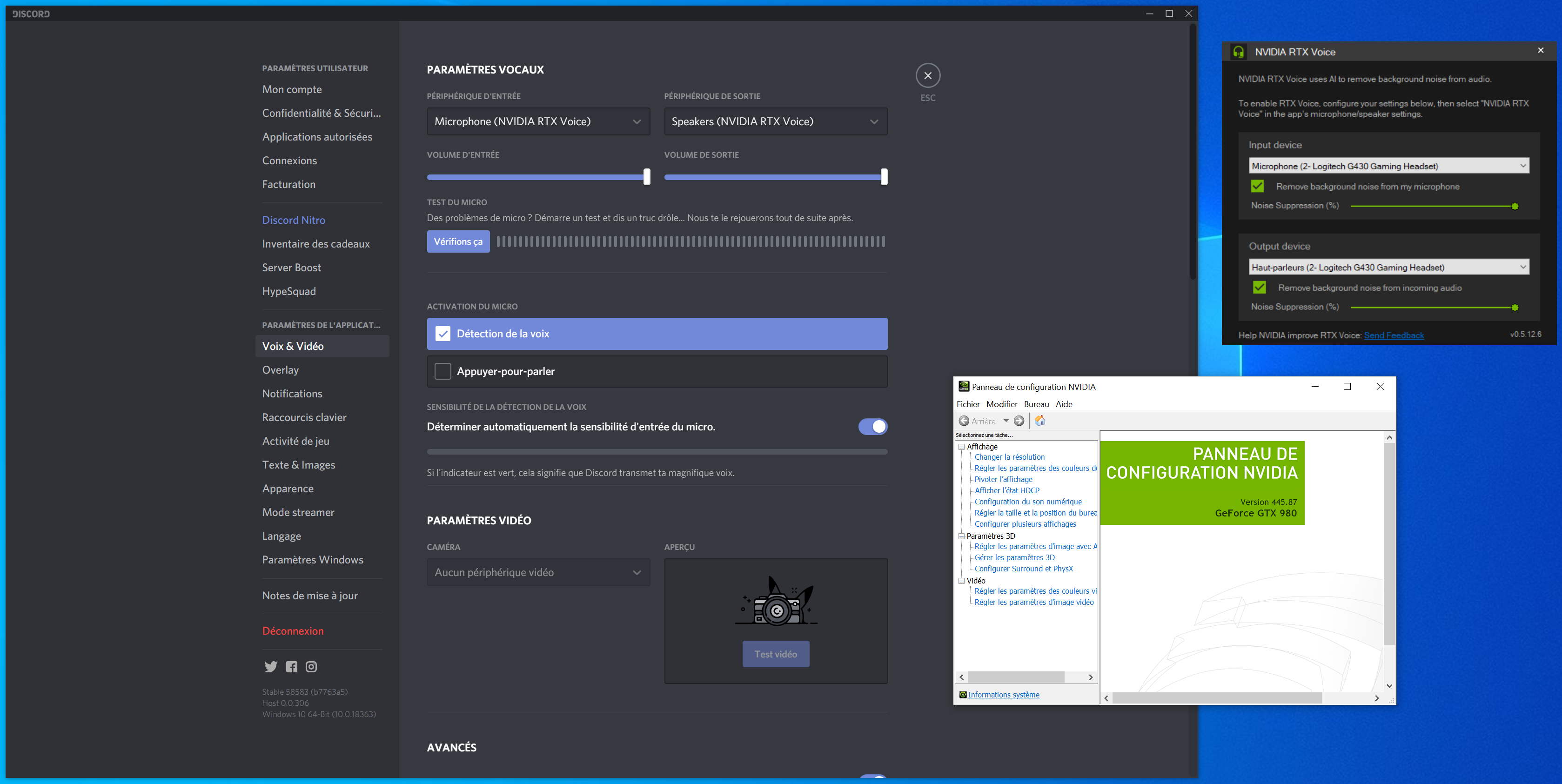
Pour vérifier le fonctionnement de cette méthode, nous avons effectué un test avec une GeForce GTX 980, 1660 Ti et 2060. Dans tous les cas, RTX Voice (0.5.12.6) semblait fonctionner correctement, modulo ses quelques bugs (compréhensibles pour une bêta). Nous n'avons pas encore pu effectuer de tests sur des modèles antérieurs.
N'hésitez pas à partager avec nous vos propres essais au sein des commentaires. Tout fonctionne correctement, avec une GTX ou une RTX. Est-ce à dire que les Tensor Cores ne sont pas utiles dans ce dispositif, ou pas utilisé ? Est-ce qu'une telle extension aux GTX était prévue ou sera-t-elle finalement bloquée de manière plus active ? Impossible à dire pour le moment. Interrogé, le constructeur ne semble pas encore vouloir s'exprimer en détail sur le sujet.
Il faudra donc suivre l'évolution de RTX Voice pendant cette phase de bêta, mais aussi de son processus d'installation. L'ensemble étant plutôt efficace pour le moment, on ne peut qu'espérer que NVIDIA fasse un pas vers un accès le plus large possible dans les semaines à venir.


























Commentaires (34)
#1
Un comparatif de l’utilisation GPU entre les cartes pourraient peut-être répondre à cette interrogation. Après si c’est juste un verrou logiciel il y a clairement tromperie sur le produit et son fonctionnement…
#2
Et bam ! Encore une fois…
#3
Vous pouvez essayer avec un GPU AMD juste pour voir ?
#4
Les RTX on une architecture composé de core générique (les cuda core) et de core spécialisée (les RT core pour le ray tracing et les Tensor Core pour des réseau de neurone principalement).
Les cuda core sont apparu avec les GTX 8800 il y a 12ans (avant ça, on avait des core spécialisé) et permettent aussi bien de faire de la 3D que du calcule sur GPU. En, soit il y a de grande chose que tout ce qui est possible de faire avec les core spécialisé, ce soit possible avec les core générique. Tout comme il est possible de faire ce qu’une carte graphique est capable de faire avec un CPU.
Il y a des chance que pour les RTX, l’inpact soit pratiquement nul car tout le calcul est effectué par les tensor core qui ne sont pour l’instant pratiquement pas utilisé (autre que dans le DLSS) là où sur les GTX tu vas devoir taper sur les cuda core et donc sur la puissance même de calcul graphique.
Vu que ce soit aussi simple de faire tourner sur les GTX, je ne serais pas étonné que ce soit un réseau développé avec Tensorflow (une bibliothèque pour ce genre d’utilisation qui peut faire tourner facilement le même code sur tout plein de matos sans modification majeur), ce qui veut dire qu’il y aurait surement moyen de le faire tourner sans carte graphique, directement sur le processeur.
Cependant, le modèle (le réseau de neurone) est très certainement optimisé pour exploiter les tensor core (sur tensor core, on va privilégier des float16 des int8 voir même des int4). Utiliser des cuda core à la place est un peu suboptimal.
#5
Du coup il faudrait installer cette “Disruption révolutionnaire du monde informatique” sur une Radeon et essayer aussi, non ?
#6
Lire l’actu en général, c’est un bon début avant de commenter ;)
PS : et si AMD veut faire la même chose en WinML accéléré sur leurs GPU, ils sont libres de le faire (ou d’attendre que quelqu’un le fasse à leur place). Intel a déjà fait une telle implémentation comme évoqué dans l’article, mais elle n’est pas publique pour autant que je sache.
#7
Du coup j’ai relu.
Je réitère (denoising ou pas).
#8
Le denoising c’est ce que fait RTX Voice. Comme dit dans le papier, on peut installer sur une machine équipée d’autre chose que d’une GeForce mais il est impossible d’activer la fonctionnalité.
#9
il y a aussi du libre qui fait plus ou moins le même chose https://people.xiph.org/~jm/demo/rnnoise/
#10
Difficile de mesuré l’impact sur les performance de ma gtx 1070 pour ma part. A peine 1% du gpu utilisé par RTX voice pendant son fonctionnement. Et je confirme c’est impressionnant comment ça supprime TOUS les bruits sans pour autant altérer la voix.
#11
EDIT : je be sais pas si c’est le cas sur les RTX, mais sur ma GTX, je note un petit délai ( ~150ms ) entre le moment ou je parle et le moment ou le son est produit par le périphérique “RTX Voice”
#12
Le résultat est bluffant !
C’est génial ce truc et tout est fait dans ~50ko de javascript, D’ailleurs on peu le faire tourner en local juste en enregistrant la page et ça mange quedalle de cpu
#13
Non, parce que c’est du denoising sur un fichier, pas sur des flux en temps réel ;) Après c’est surtout une démo sur ce qu’il est possible de faire qu’un produit fini en soi.
Oui ça marche plutôt bien, et comme dit dans le papier, mieux que le module intégré à Discord pour le moment selon nos essais. Après il faudra voir toutes les implications une fois le truc sorti de bêta (difficile de tirer des conclusions avant ça).
Euh… c’est un peu plus de 50 ko de JS le code du projet (mais dans tous les cas c’est le principe de l’inférence que d’être “léger” à mettre en oeuvre, même si des unités dédiés peuvent aider pour accélérer le processus ce qui peut être nécessaire dans le cadre d’un temps réel)
#14
Sacré deal breaker je trouve. À 150ms de délai + le reste du délai traditionnel, ça va gêner salement les communications, surtout dès qu’il y a plus de 2 personnes en communication. En pratique, ça entraîne des coupages de parole intempestifs.
#15
Il peut y avoir un délai “à l’allumage” de mémoire, sans doute le temps pour le modèle de se caler sur ce qu’il doit filtrer ou non, un peu comme quand il y a des mécaniques de détection de la voix pour ouvrir le micro. Mais dans une discussion courante je n’ai pas noté de délai particulier (mais c’est difficile à quantifier sans mettre en place un dispositif précis pour mesurer)
#16
De ce que je lis sur le site de demo, le délais a été mis artificiellement en place pour mieux entendre le retour donc je suppose donc qu’il supporte le “temps réel” aussi.
Je ne l’ai pas testé directement sur ma machine, je ne sais pas dire sil y a un gros délais ou non.
Mais ça a au moins l’avantage de ne pas dépend d’un matériel en particulier.
#17
Des personnes ont fait des test, ça réduisait les performances des benchmark de 10%. Donc, ça a un inpact certain. Je ne sais pas si tu mesure la bonne chose (si tu la consommation GPU dans le Gestionnaire des taches, ce n’est pas fiable, il ne regarde pas forcément au bon endroit, il y a plusieurs point de mesures en réalité.).
Ce n’est pas étonnant, ce n’est pas forcément dû à une lenteur du système mais du mécanisme même. D’un point de vue simplifié : il a peut-être besoin de connaitre un peu ce qui se passe après pour déterminer ce qui est finalement du bruit de fond et ce qui n’en est pas.
Pour être plus exact, c’est surement quelque chose que les équipe de NVidia ont testé, c’est de savoir quel est le décalage optimal, celui qui donne le meilleur résultat. Il est même imaginable d’avoir un décalage négatif, c’est a dire prédire en avance ce que tu vas dire dans quelque ms (ce n’est même pas une syllabe, ce n’est pas aberrant)
J’ai regardé rapidement, le code final est en C/binaire. Mais il est tout à fait possible de le faire en Javascript.
En gros, on voit clairement qu’il ont pris pour contrainte que le réseau de neurones soit très petit pour pouvoir le faire tourner sur le maximum d’appareil. Ceci se fait au prix de performance moindre. Au passage les Réseaux de neurones récurrent (RNN) ne sont pas forcément le point fort des GPU et finalement tourne très bien sur CPU lorsqu’il faut faire de la prédiction (c’est une plaie en apprentissage).
Un réseau de neurone, en soit c’est une sorte d’architecture (quels types de couches, leur tailles, comment elle sont connecté) et des valeurs de réglages (les poids) qui sont déterminés lors de la phase d’apprentissage.
Si tu connais l’architecture et que tu as les poids (donc tu as le réseau de neurone complet), tu peux ecrire un programme dans le langage que tu souhaite pour l’exécuter. Mais on va faire simple, la bibliothèque Tensorflow le fait très bien (Keras qui est utilisé ici passe par tensorflow).
Normalement il existe un format (ONNX) qui se veut universel pour enregistrer les réseaux de neurones, mais la plupart des bibliothèques de réseau de neurone utilisent leur propre format. La dernière fois que j’avais regardé, il n’y avais que le bibliothèque de Microsoft (Microsoft Cognitive Toolkit) qui l’utilisait.
Voici le code pour l’apprentissage : il créer le réseau de neurone (qui ici n’est composé que d’une couche GRU suivie d’une couche dense, ce qui n’est pas du tout ce qui est proposé dans l’article) lance l’apprentissage et savegarde tout le réseau (l’architecture et les poids).
Ici, ils ont écrit en C le code nécessaire pour charger et exécuter le réseau de neurone (ils ont réécrit le code pour les couches).
Mais tu souhaite réutiliser leur modèle et l’executer en javascript, c’est assez simple grace justement à Tensorflow qui possède une version Javascript de sa bibliothèque. Voici le tutos pour charger un model dans tensorflow.js. Malheureusement, les auteurs de l’article ne propose pas le modèle déjà appris dans leur git, il faudra le créer par toi même.
#18
Désolé du double post, mais je ne peux plus éditer mon précédent poste.
En effet, on peut tester sur la page en javascript, cependant ce n’est clairement pas ecrit en javacript à la base mais transcodé en javascript a partir du code C (asm.js).
#19
Re petit feesback.
J’ai effectivement été gentit avec les moins de 1% de conso. Dans mon cas on est plutot autour des 6⁄7% potentielleent ça commence à se voir.
Par contre le démai de traitement est en réalité moins elever que ça, dedans je comptais le traitement discord …. je n’ai pas fais de mesures précises mais aucune gêne pour des concersation sur discord, on est 3 à l’avoir installé ce truc est juste trop fou, c’est les streamers qui vont être content.
Dsl pour les fautes je suis sur mon tel.
#20
Justement, je l’ai lu avant de commenter. Je ne vois pas en quoi la question serait moins pertinente que de tester avec une GTX 980.
La question n’étant pas de savoir si AMD va sortir un équivalent mais plutôt de savoir si l’implémentation de NVIDIA est générique et peut tourner sur d’autres GPU.
La limitation est commerciale mais si on passe outre, est-ce que ça tourne aussi bien sur AMD ?
N’ayant qu’une GTX 1070, je ne peux pas tester.
#21
Quoi ?? Mais c’est idiot !! Quand on a un retour, on le veut au contraire avec le moins de délai possible, sinon c’est hyper déstabilisant de s’entendre en écho. Perso quand j’ai un retour micro je règle ma carte son pour avoir 2,66ms de délai (en dessous ça grésille). À 4ms ça passe encore et à 8ms je commence déjà à trouver ça limite.
Enfin perso je vois pas trop l’intérêt de ce genre de technos-gadgets, à part continuer à vendre des micros gamers de qualité absolument honteuse. On trouve des micros très directionnels et d’excellente qualité qui ne captent aucun bruit de fond pour une bouchée de pain. Mais pour une raison que j’ignore le matos estampillé “gamer” s’entête à être omnidirectionnel et avoir la qualité audio d’un téléphone des années 90…
#22
Non, parce que sinon tu aurais vu que l’on évoque le cas des machines sans GeForce ;)
Oui il faut bien éviter d’activer les fonctionnalités équivalentes de Discord, pour certaines mises en place par défaut (ce n’est pas le cas de Krisp.ai par contre).
Pourtant l’intérêt est évident. Surtout que les micros directionnels peuvent être utilisés, mais ne sont pas les seuls à l’être dans le cadre de conversation vocales, tout comme le gaming n’est pas le seul objectif de ces produits. Et in fine, ne pas seulement dépendre d’un traitement matériel forcément limité et avoir quelque chose de plus adaptatif est intéressant.
Après rien n’empêche de se reposer sur son micro seul et de ne pas utiliser ces fonctionnalités si ça ne convient pas. Dans tous les cas, que ça ne serve pas à certains ne devrait pas être un critère pour savoir si ça ne doit pas être proposé à tous, sous diverses formes (via une intégration navtive à Discord ou des apps du style de RTX Voice dans le cas présent)
#23
Pour la qualité des casques-micro “gaming” je ne peux qu’être d’accord avec toi. Tant pour la qualité des micros que du son produits par les casques d’ailleurs …
J’ai fini par trouver un truc très correcte : le cloud alpha d’hyperx, qui pour le coup à un micro directionnel vraiment très correcte qui ne prend que très peu les bruits ambiant en plus de reproduire la voix fidèlement. Alors oui, ça vaut pas un Rode ou autre micro de studio … En même temps c’est pas les mêmes térifs.
Mais, RTX Voice fait tout de même un excellent boulot en supplément : Je vapote, m’arrive de souffler avec mon gros nez sur le micro ce qui peut vite être insupportable sur toute une soirée sur Valorant :)
Ba RTX Voice supprime tout ça vraiment proprement, y’a vraiment que ma voix qui passe, qui ne semble pas altérée de ce que j’ai pu en écouter.
En conclusion je pense quand même que y’a pas mal de situation ou ce truc va être vraiment utile, rien que pour la prouesse technique je trouve ça cool, Alors oui, les denoiser ça existe depuis un moment, soit en matériel soit en logiciel, mais tout ce que j’ai pu tester/entendre, ça altère toujours ( plus ou moins ) la voix, ce qui ne semble pas être le cas ici.
#24
Pour faire simple : si tu veux faire du réseau de neurone, tu achètes NVidia, il n’y a même pas de discussion. AMD est rarement supporté par les bibliothèques. Mais du coup, à l’inverse, la plupart des bibliothèques ne fonctionne pas (facilement) avec AMD. Autrement dit, très peu de chance que les GPU AMD soit supporté avec une manipulation aussi simple.
En effet, les bibliothèque pour faire des réseau de neurone utilise CUDA et non OpenCL. Je n’ai pas les raisons, mais c’est très courant que les logiciels utilisant le calcule sur GPU soit fait avec CUDA. .
J’ai bien 2 potentielle raisons en tête :
NVidia sont les leader sur l’environnement des réseau de neurone et de manière général sur tout ce qui touche le CPGPU.
Pour expliquer ce qui se passe ici. Les Tensor core sont des core spécialisé pour quelques opérations bien spécifiques qui peuvent cependant entre aussi réalisé par les cuda core plus général. Cependant un Tensor core sont beaucoup plus efficaces pour ce genre d’opérations. A priori, le bibliothèque utilisé pour leur solution (je crois que c’est un comportement intétégré à CUDA) cherche en priorité à balancer le maximum d’opération sur les tensor core et à défaut, sur les cuda core. Si tu n’a pas de tensor core, alors tout est balancé sur les cuda core.
#25
Merci. Maintenant c’est clair.
#26
Testé sur une Nvidia GTX 960m, RTX Voice utilise 13% sur mon GPU Load et 10 % sur le Memory Controller, vérifié avec GPU-Z, avec un downclock de -135MHz sur le Core et -502MHz (les plus basses possibles) sur la mémoire avec Afterburner ça passe respectivement à 16% et 13%, et avec l’overclock maximal stable sur mon GPU (soit +135MHz sur le Core et +625MHz sur la mémoire) on se retrouve à 11% sur le GPU Load et 8% sur le Memory Controller
On reste sur une utilisation significative mais totalement gérable sur un si faible GPU qui n’as que 640 CUDA Cores
Mais surtout j’ai été réellement bluffé par à quel point ça fonctionne bien, j’ai martelé mon clavier à fond, tapé sur la table à côté, éclaté ma souris et claqué dans mes mains entre ma bouche et le micro (juste devant ce dernier) au point de ne plus m’entendre parler et d’avoir mal aux mains pendant plusieurs minutes, on n’entend rien d’autre que ma voix (pour les plus gros clap, on entend qu’il y a un trouble et très légèrement au fond un très faible clap quasi imperceptible)
#27
Et ensuite testé sur une conversation Discord (sans Krispr évidemment) pendant 4 heures avec en moyenne 17 personnes puis pendant 2 heures à 8, et je n’ai senti, ni moi ni mes interlocuteurs, de délais notable (et on jouait à des jeux sur navigateur, donc où la réactivité est de mise mais où je ne pouvais pas tester l’impact sur les pertes de performances)
Par contre, étant constamment en tâche de fond, cela fait que mon GPU est constamment en fonctionnement et a ses fréquences maximales au lieu de se mettre en veille habituellement, étant sur un Laptop avec un iGPU
Désolé du double post, je ne peux plus éditer mon message précédent
#28
Du coup, j’ai testé sur ma 2070, malheureusement difficile d’avoir l’information plus détaillé :
Malheureusement, je ne peux pas savoir ce qu’il y a derrière GPU load et ce qui est réellement utilisé (si par exemple c’est les tensor core, on peut considérer ça comme anecdotique pour l’instant). Peut-être que je pourrais avoir acces à ca avec nsight compute mais il faut que j’installe ça, et que je regarde comment le faire fonctionner.
Effectivement, tu peux faire du flamenco à coté, frapper dans tes mains comme un malade, pas un son ne passe. J’avais vu une vidéo avec un mecs qui allume sont sèche cheveux, c’est bluffant. Autre exemple, même la télé en fond, tu ne l’entend pas.
#29
David_L a écrit:
“Il peut y avoir un délai “à l’allumage” de mémoire, sans doute le temps pour le modèle de se caler sur ce qu’il doit filtrer ou non, un peu comme quand il y a des mécaniques de détection de la voix pour ouvrir le micro. Mais dans une discussion courante je n’ai pas noté de délai particulier (mais c’est difficile à quantifier sans mettre en place un dispositif précis pour mesurer)”
Pour ma part j’ai constaté un ajout de latence considérable dû au rtx voice.
Aucun matériel de mesure n’a été nécessaire pour le confirmer, il a suffi que ma compagne parle dans mon micro sur mon ordi et que je l’écoute via son ordinateur sur discord.
En basculant du pilote rtx au pilote de mon casque dans discord, j’ai pu facilement constater une augmentation de la latence largement perceptible à l’oreille seule (que dire d’une visio-conférence alors….).
Vous répondez à liam que l’intérét d’une telle technologie est évident et qu’elle peut être utilisée sur des micros directionnelles.
Je suis d’accord que l’intérét de supprimer les bruits de fond est évident, moi même j’attends depuis des années une techno qui me permette de chatter en utilisant mes enceintes sans que mes amis me disent “baisses la musique” ou “je m’entends dans ton micro” et à ce niveau le pari est remporté haut la main.
Ca doit aussi être génial pour les personnes travaillant dans des environnements bruyant.
Cela dit ces problèmes touchent pour ma part (quel est votre ressenti là-dessus?) plus au problème de l’inconfort que de l’inintelligibilité.
Ce qui pour moi rend une conversation inintelligible est le délai, c’est en effet ce qui fait la différence entre une conversation réelle (ou au bon vieux téléphone analogique) et une conversation en talkie-walkie.
En effet, lorsque nous chattons nous attendons toujours un temps aprés que l’interlocuteur aie parlé, ou lorsqu’on fini soi-même une phrase, pour enfin reparler, et ce afin d’être sûr d’être entendu.
Cela montre bien que nous avons tous conscience de ce décalage et que cela ne facilite vraiment pas nos conversations.
L’ajout de filtres numériques visant à supprimer les bruits de fond n’aide bien sûr en rien le délai, et ce dernier rtx voice en rajoute encore une couche.
Ce n’est pas génant pour dire “à couvert” ou “chope le loot” dans une partie de gaming mais pour une conversation profonde en apéro sur what’s app avec plusieurs personnes je demande à voir.
Ce qui rend aussi une conversation inintelligible est la compression extreme pratiquée sur le flux audio.
Je serais curieux de savoir ce que dirait un ingé son si on lui demandait d’enregistrer une chanteuse en 96 kbps (le max de discord) et qu’on lui soutenait que ça va être aussi intelligible qu’en l’enregistrant en qualité cd à 1440 kbps…..
Bref, il me semble que cette technologie fait de grandes avancées sur un paramètre relativement important tout en faisant un grand pas en arrière sur le fond du problème, la latence et en ne faisant aucun progrès sur l’autre bête noir, le bitrate, ce qui en fait non pas une technologie invalide, mais une technologie prématurée en devenir (décidément les “RTX”…) qu’il faut encenser parcimonieusement.
A mon sens, un codec lossless 16 bits - 44,1 kHz , une amélioration de la latence sont les paramètres les plus important pour communiquer, et là dessus on arrête pas de revenir en arrière.
Une fois ces problèmes évacués, on pourra effectivement se pencher sur un micro dont la qualité et la directivité ne seront pas systématiquement réduit à néant par cette flopée d’algorithmes, quit à se passer de ceux-ci.
Est-ce cela que tu voulais exprimer liam?
#30
je tiens quand même à insister sur l’efficacité coté réduction de bruit, c’est quand même une sacré performance, on peut par exemple jouer avec un micro etout en écoutant de la musique et ses interlocuteurs sur ces enceintes sans que ceux-ci ne perçoivent le retour des dites enceintes, je ne peux pas tout dénigrer, et éspérons que ça s’améliore lors de la sortie officielle.
Avec la 1080 gtx et un i7 4930k je constate un bon ajout de latence, est ce que quelqu’un a obtenu des meilleurs résultat avec une rtx?
#31
Quasi pareil sur une 2070s
#32
J’ai testé en m’enregistrant sur audacity. J’ai créer une piste avec un métronome toutes les 2s et je me suis enregistré alors que j’essayais de dire “tic” au moment au le curseur passé devant le metronome.
J’ai testé sur l’input de mon micro, sur RTX voice avec les filtres desactivé et RTX voice avec filtre activé.
Sinon, j’ai une RTX2070 et un vieux i5-4670K, j’ai utilisé le micro de mon casque G933 avec les drivers Logitech.
Je considère que l’output du micro comme référence.
Oui, il y aurait bien un décalage d’environ 0.10-0.15s (0.15 en prenant mes pire cas) en plus, mais majoritairement dû à l’input RTX voice lui même plus que le filtre. En effet l’activation du filtre ne provoque qu’un décalage inférieur à 0.05s (0.02-0.03).
ps : j’ai a peu prêt 0.10s de décalage entre le tic du métronome et le moment ou j’attaque vraiment le tic en temps normal. Ca peut être dû à la latence, mais aussi à mon propre décalage (je ne suis pas bon en rythmique)
#33
Je n’ai pas testé encore (sur GTX), et donc je ne me prononce pas sur le délai.
Je partage en revanche ton avis sur l’importance de celui-ci pour rendre une conversation intelligible et fluide comme peut l’être une conversation naturelle physique. C’est super de limiter les bruits environnants mais ça laisse toujours cette impossibilité pour deux personnes de parler en même temps ou du moins sans délai entre 2 interventions.
Je suis plus sceptique pour le bitrate élevé, qui, malgré l’intérêt évident sur la qualité globale, doit rester limité sur une conversation pour restreindre le débit utilisé (tant que les interlocuteurs ne sont pas tous sur une connexion haut débit) et aussi limiter l’impact sur le calcul nécessaire au décodage d’un flux audio haut débit pour garder un semblant de temps réel. Je ne suis pas expert, mais je pense que les ingés télécoms notamment ont du faire face à ce problème. Et on constate depuis la 3G une amélioration nette de la qualité audio car plus de débit mais faut y aller par étape à ce sujet.
#34
Je n’ai pas testé encore (sur GTX), et donc je ne me prononce pas sur le délai.
Je partage en revanche ton avis sur l’importance de celui-ci pour rendre une conversation intelligible et fluide comme peut l’être une conversation naturelle physique. C’est super de limiter les bruits environnants mais ça laisse toujours cette impossibilité pour deux personnes de parler en même temps ou du moins sans délai entre 2 interventions.
Je suis plus sceptique pour le bitrate élevé, qui, malgré l’intérêt évident sur la qualité globale, doit rester limité sur une conversation pour restreindre le débit utilisé (tant que les interlocuteurs ne sont pas tous sur une connexion haut débit) et aussi limiter l’impact sur le calcul nécessaire au décodage d’un flux audio haut débit pour garder un semblant de temps réel. Je ne suis pas expert, mais je pense que les ingés télécoms notamment ont du faire face à ce problème. Et on constate depuis la 3G une amélioration nette de la qualité audio car plus de débit mais faut y aller par étape à ce sujet.