

Avec la montée en puissance du « Cloud », on entend régulièrement parler d'Object Storage. Une notion qui vient s'opposer à des solutions plus classiques que sont Block et File Storage, exploitable via des DAS, NAS ou SAN. Mais dans la pratique, à quoi ça correspond ? On vous explique tout.
Dans le domaine du stockage, on est habitué à certaines notions techniques et autres types de produits : les disques durs (HDD) et SSD, les normes Serial-ATA, PCI Express et SFF-xxxx, les formats 2,5"/3,5" et M.2, les protocoles AHCI et NVMe. On peut même aller plus loin avec les types de Flash NAND (SLC, MLC, TLC, QLC, PLC, 3D ou non), les technologies exploitées dans les HDD comme le CMR, PMR, SMR, MAMR/HAMR, etc.
- L’extraordinaire évolution du stockage
- SATA Express, U.2, Mini-SAS HD, SFF-TA-1002 : ces autres connecteurs pour le stockage de données
Vous pensiez que c'est compliqué ? Ce n'est pourtant qu'une partie des notions importantes à connaître. Car en vous intéressant à tout cela, vous ne vous êtes focalisé que sur un élément de la chaîne : le périphérique de stockage, où les données seront physiquement présentes.
Il ne constitue pourtant qu'un premier maillon autour duquel viennent se greffer bien d'autres solutions. Nous vous proposons aujourd'hui d'y voir un peu plus clair en revenant sur d'autres concepts comme celui des DAS/NAS/SAN et les différents types de stockage : en blocs, fichiers ou objets.
DAS, NAS, SAN : une question de lien
Commençons par une notion assez simple à comprendre : le DAS, ou Direct-Attached Storage. Cela désigne tout simplement le cas où un périphérique de stockage est relié directement à une machine. C'est le type d'accès le plus rapide, tant en termes de débit que de latence, mais il implique que chaque machine dispose de son propre stockage.
Une solution acceptable et gérable pour un particulier, mais un peu plus complexe pour une entreprise qui doit assurer la maintenance, la sauvegarde, etc. Un DAS peut ainsi être un HDD/SSD Serial ATA, PCIe mais aussi un périphérique externe ou une baie d'extension reliés via USB ou Thunderbolt.
Ce n'est par contre pas le cas lorsque la liaison passe par un réseau local, puisque le lien n'est alors plus direct, mais dépend d'autres équipements, comme le routeur et ses services, des switchs, etc. L'accès ne se fait plus alors forcément depuis une machine en particulier, mais n'importe laquelle présente sur le réseau.
Dans ce second cas, on parle plutôt de NAS (Network-Attached Storage) ou de SAN (Storage Area Network). Le premier est très connu du grand public, contrairement au second que l'on retrouve surtout dans des solutions professionnelles. Pourtant, la différence entre les deux est bien plus subtile qu'on ne le pense.
Le NAS est en effet considéré comme un stockage de type Fichiers (File Storage), le second de type Blocs (Block Storage). Et pour ne rien simplifier, les produits vendus comme des serveurs NAS dans le commerce peuvent aussi être utilisés comme des SAN. C'est simple non ?

Ici un NAS de QNAP pouvant être utilisé comme SAN via iSCSI, auquel on relie une baie d'extension (DAS) en USB
Block Storage et File Storage
Une solution de type Block Storage accède en données par blocs, d'où son nom. Cela recouvre une grande diversité de produits, comme les DAS et les SAN.
Ainsi, le HDD/SSD de votre machine est une solution de Block Storage. Vous disposez en effet d'un volume de données où l'on écrit et lit des données via des blocs de taille définie (via un système de fichiers, nous y reviendrons). Pour les SAN, on passe par des protocoles réseau comme iSCSI, Fibre Channel, NVMe Over Fabrics (NVMeOF).
Ils sont le plus souvent mis en œuvre dans des datacenters, avec redondance et switchs dédiés, donnant accès à des portions de données à tel ou tel serveur alors que le stockage est centralisé. C'est le cas pour des hébergeurs Cloud comme Scaleway, OVH, ou encore Amazon avec EBS (Elastic Block Store).
Lorsque l'on formate ces volumes de données avec un système de fichiers ou FS (ext4, btrfs, FAT, NTFS, etc.) on passe du Block Storage au File Storage. Ainsi, l'utilisateur a accès à des fichiers, regroupés en répertoires, en partitions, etc. C'est l'accès le plus courant dans nos PC du quotidien.
Le système de fichiers gère la conversion de ces tâches en accès par blocs de données pour le HDD/SSD. On parle donc de File Storage lorsque vous utilisez l'explorateur de fichiers de votre système d'exploitation.
Une question de simplicité et de performances
Dans les solutions réseau, on considère ainsi que le Block Storage est plus performant car le lien sert uniquement à faire transiter les commandes entre le client et le serveur.
Avec du File Storage, tout est géré par le serveur, à qui l'on ajoute une surcouche avec l'un des protocoles de partage que sont Samba (SMB/CIFS), NFS (Network File System) ou encore AFP (Apple Filing Protocol). C'est donc moins efficace, mais le plus simple pour mettre en place un espace de stockage partagé.
Ainsi, la différence entre SAN et NAS, comme celle entre Block et File Storage est simple à comprendre : dans le premier cas vous avez accès à un volume qui sera à formater. Dans le second, vous pouvez lire et écrire des répertoires/fichiers directement. Prenons un exemple :
 À gauche, un LUN iSCSI accessible et vu comme un disque local formaté. À droite, un lecteur réseau partagé via SMB
À gauche, un LUN iSCSI accessible et vu comme un disque local formaté. À droite, un lecteur réseau partagé via SMBVous utilisez un serveur qui fera office de NAS, y placez des disques durs regroupés sous la forme d'une grappe RAID pour assurer une redondance. Ils sont formatés, vous y créez des dossiers que vous partagez sur le réseau via Samba, tout cela depuis l'interface du NAS. Des utilisateurs y accèdent via leur explorateur de fichiers (voir ci-dessus).
Passons maintenant à un ensemble de type SAN via iSCSI. Vous y placez également des disques durs regroupés sous la forme d'une grappe RAID pour assurer une redondance. Mais cette fois, vous créez un LUN (Logical Unit Number) qui sera vu par l'utilisateur comme un volume à formater avec un système de fichier depuis sa machine.
Il sera donc le seul à pouvoir y accéder pour y placer des répertoires et fichiers comme il le ferait avec n'importe quel autre périphérique de stockage (voir ci-dessus). Le SAN est ainsi une manière de déporter un espace de stockage sur un serveur, alors que le NAS permet de partager des données du serveur avec plusieurs clients.
Object Storage : révolutions
Dans les cas que nous venons d'évoquer, il y a un lien direct entre là où les données sont stockées et la manière d'y accéder. Cela peut être de manière locale ou distante, le formatage étant géré au niveau du client ou du serveur, mais on se retrouve au final dans des situations et des méthodes assez classiques.
C'est efficace et peut être très performant, avec la possibilité d'un certain niveau de redondance. Mais ce n'est pas très adapté à des besoins plus spécifiques comme le stockage de masse, exploitable facilement depuis des applications. On imagine en effet assez mal les développeurs tout gérer à coups de protocoles SMB/CIFS ou iSCSI.
Surtout que des milliers ou des millions de personnes peuvent devoir accéder à des données en simultanée. Il faut donc constituer des clusters regroupant des centaines ou des milliers de serveurs, fonctionnant ensemble. Le tout en offrant une intégration simple aux développeurs. C'est ainsi qu'est né l'Object Storage.
Son premier objectif est sa principale différence avec les Block et File Storage : il y a une décorrélation complète entre l'accès aux données et là où elles sont situées. Il n'est plus question de fichiers, de dossiers, de volumes, de partitions de HDD/SSD, etc. Tout est objet ! On parle alors de données non structurées.
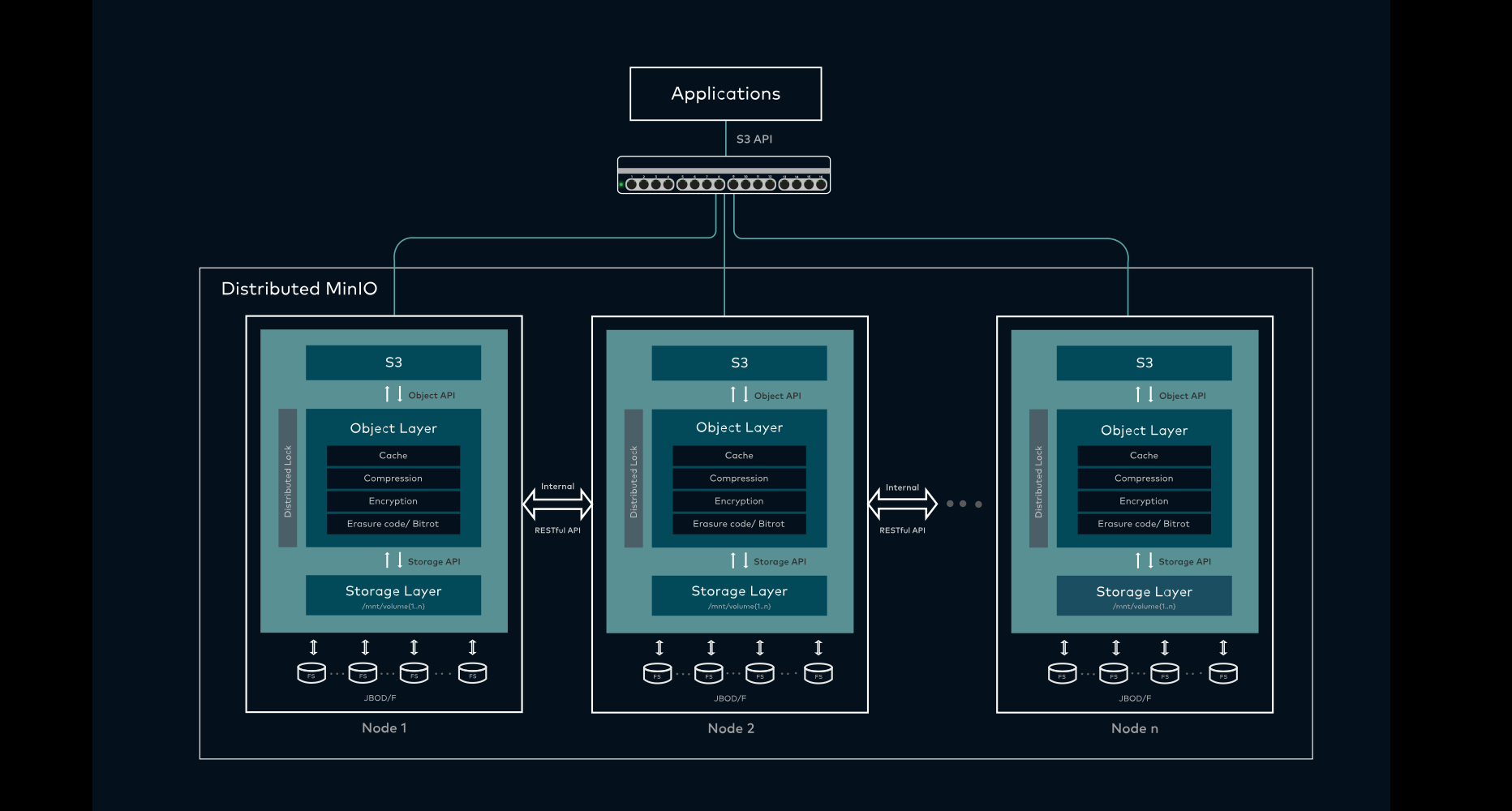
Une architecture distribuée et redondante : trois serveurs MinIO, chacun contenant de nombreux disques
Le développeur n'a pas à savoir où sont exactement les données pour y accéder
Elles peuvent être stockées sur un serveur ou des centaines, entières ou par portions, avec ou sans réplication, cela ne change rien à la manière d'y accéder qui est l'autre différence fondamentale : cela ne se fait pas via un protocole local ou réseau mais... des requêtes HTTP et une API.
Ainsi, n'importe quel appareil peut simplement recevoir ou envoyer des données. Cela peut être effectué par de petits outils tels que cURL ou des clients spécifiques suivant un standard. Amazon S3 en est rapidement devenu un de fait, de nombreux serveurs et clients de stockage objet s'étant adaptés pour être compatibles avec ses requêtes et formats de données. Mais on trouve d'autres solutions, et des serveurs que chacun peut installer.
Il y a par exemple Ceph, notamment utilisé par le français OVH (qui est lui aussi compatible S3). Autre français très actif sur ce terrain : OpenIO, qui organisait il y a quelques mois son « Tbps Challenge » avec Criteo, grimpant à 1,372 Tb/s sur 350 serveurs de production. Mais aussi le très agile MinIO.
Ces serveurs sont configurés de manière à créer des infrastructures flexibles et redondantes. On peut ainsi ajouter ou retirer du stockage comme si de rien n'était. L'utilisateur, lui, ne voit que des buckets, sorte de boîtes contenant les données qui prennent la forme d'objets (nxibucketchallenge dans l'exemple ci-dessous).
Ils sont associés à un identifiant unique (la clé) qui se compose d'une suite de caractères pouvant reproduire une structure hiérarchique classique grâce au délimiteur (/) et à la notion de préfixe.
Ainsi, plutôt que des fichiers organisés de la sorte :
- Répertoire/
- Sous-répertoire 1/
- Fichier 1.txt
- Fichier 2.txt
- Sous-répertoire 2/
- Fichier 3.txt
On dispose de trois objets dont les clés sont les suivantes :
Répertoire/Sous-répertoire 1/Fichier 1.txt
Répertoire/Sous-répertoire 1/Fichier 2.txt
Répertoire/Sous-répertoire 2/Fichier 3.txt
Malgré une différence fondamentale dans la constitution des données, les interfaces de gestion peuvent avoir une même représentation visuelle. Simplement, vous ne pouvez pas agir sur ce qui apparaît comme des (sous-)répertoires, car ils n'existent pas concrètement, il s'agit d'objets avec un même préfixe.

L'interface graphique de Scaleway reproduit un explorateur de fichier avec des dossiers, mais tout n'est qu'objet
Des métadonnées sont aussi associées à chaque objet. Certaines sont définies par le standard (date et heure, longueur, type, empreinte/hash, classe de stockage, chiffrement ou non, etc.), d'autres peuvent être ajoutées par l'utilisateur. Elles sont dans tous les cas sous la forme d'une clé associée à une valeur.
Cela peut être utile pour retrouver des objets correspondant à un même lieu, une même personne, etc. On peut directement placer des informations dans les métadonnées de l'objet plutôt que dans une base de données. Ce sera au choix du développeur et de ses besoins, notamment en termes de performances.
Même si ce n'est pas la plus efficace en termes de latence, l'accès par API est dans tous les cas une solution très simple pour mettre rapidement en place des intégrations diverses à des outils tiers. Mais aussi créer des solutions de sauvegarde ou de partage de données faciles à prendre en main.
- Utilisez l'Object Storage pour stocker des fichiers et les partager simplement en ligne
- Stockage en ligne, compatible S3, archivage : quel prix pour la conservation de vos données ?























Commentaires (13)
#1
Excellent article, merci ! Impatient de lire les autres articles de la serie !
#2
Super article, merci !
#3
Super intéressant, ça met à plat les notions de stockages, je ne connaissais pas la notion d’object storage, alors que concrètement je l’utilise déjà ;)
#4
Oui c’est souvent le cas en fait, aussi pour ça qu’on a voulu publier ce papier avant de parler d’OS de manière plus détailée ensuite
#5
Oui, ça demande d’autres articles, car là il ne s’agit que de contenant, l’important restant de gérer le contenu.
#6
Merci pour cet article
#7
“Ainsi, la différence entre SAN et NAS, comme celle entre Block et File Storage est simple à comprendre : dans le premier cas vous avez accès à un volume qui sera à formater. Dans le second, vous pouvez lire et écrire des répertoires/fichiers directement.”
J’ajouterai une différence importante à ce niveau : la conséquence de ce mode d’accès différent c’est que sur un NAS, plusieurs clients peuvent avoir accès à un même espace (le système de fichier étant géré par le NAS), alors que sur un SAN, chaque espace est dédié à un client (et chaque client gère le système de fichiers sur son espace). Le NAS est donc avant tout un moyen de partager des données, tandis que le but du SAN est de déporter le stockage.
#8
Oui c’est une point que j’avais oublié de préciser, un rajout a été fait dans ce sens merci
#9
Un peu extrême de dire ça. Rien n’empêche à plusieurs “clients” d’accéder aux mêmes blocs. Et y a des FS distribués qui gèrent plus ou moins bien ça. L’ajouter dans l’article prête à confusion.
Vaudrait mieux le formuler ainsi dans l’article en indiquant effectivement le but premier de chaque solution.
#10
Pas forcement d’accord sur ce coup là, tu prends par exemple VMware, la VMFS a des mécanismes qui permettent justement de gérer un accès concurrent au même bloc-device depuis plusieurs compute node.
On peut aussi prendre comme exemple Oracle, a qui on présent des LUNs directement à tous les nodes, l’applicatif gérant les accès concurrent au bloc-device partagé.
#11
merci pour l’article, j’aime quand vous m’apprenez des trucs comme ça :)
#12
Superbe article. Merci
#13
Super intéressant ! Entre ça et l’article correspondant sur NI, je viens de découvrir des trucs :-)