

Log4shell (de son petit nom CVE-2021-44228) est un bel exemple de vulnérabilité qui maintient éveillé des équipes IT depuis plusieurs jours et dont on va parler un bon bout de temps. Au moins jusqu’à la prochaine alerte aussi sérieuse, dont personne n’est capable d’en prédire la nature ni la date de survenue.
Cela fait partie des charmes de l’informatique tout en contribuant au maintien d’un taux élevé d’ulcères chez les RSSI. Maintenant, bien qu’elle soit fondamentalement assez simple, il est intéressant de connaître les mécanismes de cette vulnérabilité, afin de comprendre pourquoi elle est aussi dangereuse.
Nous vous proposons donc un débrief complet, explications et schémas à la clé.
Log4J, c’est quoi ?
Il s’agit à la base d’une librairie bibliothèque écrite en Java pour des applications Java. Son rôle est de permettre une gestion unifiée et cohérente des logs applicatives, comme son nom l’indique (log4j signifiant « Log For Java »).
On voit donc que cela traite d’une fonction de base de toute application informatique, et cette librairie bibliothèque existe depuis un bon bout de temps, son implémentation ayant débuté en 1996. Rapidement intégrée par la fondation Apache avec une licence de type Apache Software License, elle est donc disponible en source ouverte et utilisable par n’importe quel projet informatique.
Tant et si bien qu’elle fut intégrée, au fil du temps, dans d’innombrables applications y compris par de très grands acteurs comme Google, Microsoft, Twitter, IBM, CloudFlare et bien d’autres
Version 1 et version 2
Cet utilitaire a ensuite vécu une histoire classique, avec l’apparition d’une version 2 à partir de 2012. L’équipe de développement a maintenu une branche 1.x en parallèle de la nouvelle, pour conserver une compatibilité ascendante, jusqu’en 2015 où il a été jugé que le maintien des deux versions devenait trop complexe.
La branche 1.x s’est arrêtée et n’a plus reçu aucune évolution, même pour corriger une faille de sécurité. D’ailleurs, une vulnérabilité (CVE-2019-17571) a été trouvée postérieurement à cet arrêt ; elle affectait les deux versions, mais n’a fait logiquement l’objet d’aucune correction sur la 1.x, et seule la branche 2.x a reçu un correctif.
Toute application utilisant encore aujourd’hui une version 1.x est potentiellement vulnérable à cette faille. Il s’agit d’un problème assez sérieux, du même genre que log4shell, mais avec des impacts légèrement moindres. Il n’affecte que les versions allant de 1.2 à 1.2.17.
JNDI et lookup
Java est très utilisé dans des architectures distribuées. Il est donc logique pour un composant Java d’en appeler un autre sur une machine distante. La JNDI (Java Naming and Directory Interface) permet d’aller récupérer un objet Java présent sur une machine distante, y compris très loin sur le réseau, comme le permet internet.
Il est donc légitime qu’un composant Java appelle un objet éloigné, qu’il retrouvera grâce à deux informations (constituant le contexte) :
- Son nom
- Le service d’annuaire où il est connu
Ce dernier peut être du type LDAP, RMI Registry ou même CORBA COS pour les plus téméraires. L’objet peut donc vivre sa vie, du moment qu’il signale son emplacement au service d’annuaire ; ainsi, un autre objet arrivera toujours à le retrouver avec son nom et l’annuaire approprié.
L’annuaire peut être situé n’importe où, du moment qu’il est accessible par le réseau. Une machine connectée à internet peut très bien aller chercher un objet Java en interrogeant un serveur LDAP placé en dehors de son réseau interne (si le réseau et le paramétrage le permettent) : gardez bien ce point à l’esprit pour comprendre log4shell. Un lookup est simplement la fonction qui permet de récupérer l’objet Java en utilisant son nom et le contexte adéquat.
Log4shell : LA faille (avant LES failles)
Des chercheurs en sécurité d’Alibaba Cloud ont découvert un comportement problématique de l'application log4j : par défaut, elle autorise JNDI et il était possible de faire un lookup en appelant un annuaire… externe !
On a vu que l’usage était légitime, mais depuis longtemps il est considéré comme prudent de se méfier de ce qui n’est pas sous contrôle et donc tout ce qui est en dehors du système informatique que vous gérez (il est même désormais de bon ton de ne faire confiance à personne, dans le cas d’une démarche Zero Trust).
Or, log4j n’avait pas pris de précaution particulière, ni établi de contrôle suffisant, tout en autorisant par défaut ces appels JNDI. Imaginons un vilain pirate qui se rend compte de la situation : il lui suffit d’envoyer un paquet de données (spécialement formé) que le serveur va loguer via log4j pour déclencher la vulnérabilité.
Voici comment :
- L’attaquant envoie le paquet préparé pour l’attaque (payload), par exemple dans le champ « nom d’utilisateur » d’un formulaire HTML, qu’on imagine aisément tracé sur les logs de l’application, mais toute information loguée ferait l’affaire (un entête HTTP peut suffire) ;
- Le serveur reçoit l’info et écrit, via log4j, dans les logs de l’application ;
- Le payload contient un appel JNDI (la syntaxe est basique) : log4j va alors réaliser ce lookup et aller chercher l’objet désigné qui sera injecté dans le processus du serveur cible.
Sous la forme d'un graphique, cela donne le résultat suivant :

Bien évidemment, le pirate a conçu son payload en demandant d’aller chercher un objet Java malveillant sur un annuaire qu’il contrôle. En clair, on dit presque directement au serveur d’aller chercher le malware sur internet…
Pourquoi c’est si grave
Les failles reçoivent souvent, en plus d’une identification, une indication de dangerosité : un score allant jusqu’à 10 permet de savoir s’il faut trembler devant la vulnérabilité ou pas. Pour log4shell, on trouve :
AV:N/AC:L/PR:N/UI:N/S:C/C:H/I:H/A:H
Traduction en clair : log4shell reçoit un 10/10, car la faille est à la fois facile à exploiter et ravageuse, les impacts pouvant être dramatiques. En effet, le charabia ci-dessus signifie que :
- Le vecteur d’accès est le réseau (toute machine accessible peut être touchée) ;
- La complexité de l’attaque est très faible (il suffit d’envoyer un paquet de données assez trivial pour déclencher l’attaque) ;
- Aucun privilège n’est nécessaire (inutile d’être identifié, authentifié, habilité) ;
- Aucune interaction utilisateur n’est nécessaire (pas de lien à cliquer, d’application à ouvrir)
- Les impacts sont énormes (on peut altérer la confidentialité des données, leur intégrité, leur disponibilité, donc en résumé on peut tout faire sur le serveur ciblé).
Ajoutez à cela la popularité de log4j et vous vous retrouvez avec la faille la plus dangereuse depuis un moment.
Et après ? Ça continue ?
Les développeurs de log4j ont agi très rapidement après avoir été contactés par les chercheurs d’Alibaba Cloud. Ils ont corrigé la vulnérabilité dans la version 2.15.0 qui a été publiée dans la foulée le 6 décembre. Malheureusement, la correction était incomplète dans certains cas de figure, ce qui a valu une autre CVE, nommée CVE-2021-45046.
Elle fut considérée moins grave mais suffisamment pour qu’une nouvelle version soit relivrée le 13 décembre, la 2.16.0. Le score de gravité n’était plus que de 3,7 sur 10, car l’attaque était complexe et n’aurait comme impact possible qu’un déni de service (c’est-à-dire qu'il se situe au niveau de la disponibilité du système touché).
Pas de chance, comme cette bibliothèque log4j est maintenant scrutée par des milliers d’yeux fébriles, une nouvelle vulnérabilité (CVE-2021-45105) a été découverte dans la version 2.16.0 et corrigée par les développeurs. Cette fois la gravité est de 7,5 sur 10 selon Apache (avec un impact principalement sur la disponibilité). Le résultat reste qu'à l'heure actuelle la version à mettre en place est bien la 2.17.0, même si on a déjà migré en 2.16.0 ou 2.15.0.
Pire encore, la faille précédente qu’on croyait moyennement grave a vu son score de dangerosité passer de 3,7 à 9,0 sur 10 ! Une partie des recommandations faites pour atténuer les attaques s’avère désormais insuffisantes !
Une faille puis des failles vite corrigées mais très vite exploitées
En raison de sa simplicité et de l’étendue des cibles possibles, cette faille a vite été activement exploitée. De nombreux signalements ont été émis dès le 13 décembre par KnowSec 404, AlienVault ou SecureList par exemple. Même de vieux rançongiciels se sont réactivés pour profiter de l’aubaine, autant sur Windows que sur Linux. Le CERT Suisse a produit une infographie illustrant son fonctionnement et les points d’atténuation possibles :

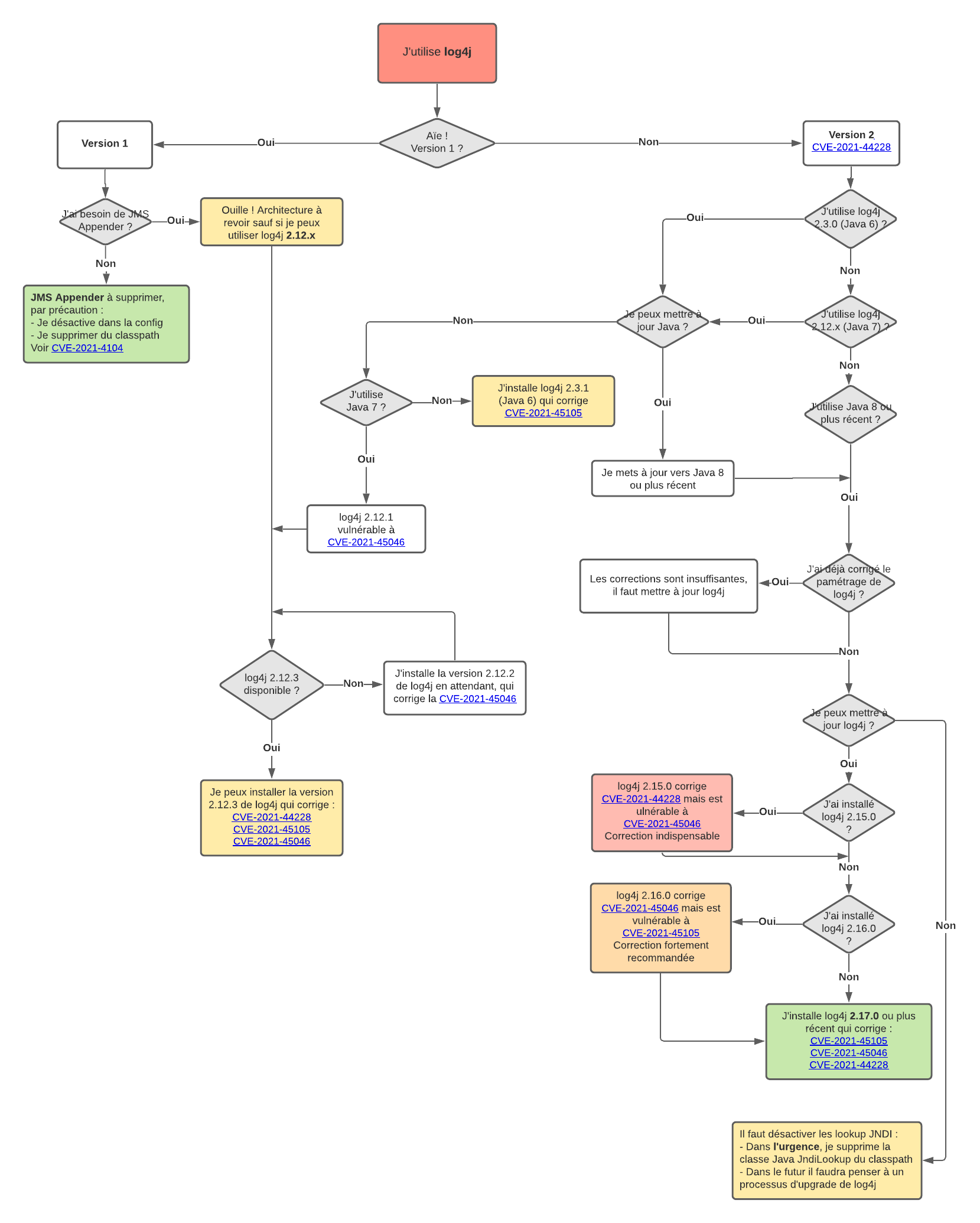
Quelles sont les versions touchées et quelles solutions ?
La meilleure solution reste la mise à jour vers la dernière version de log4j, en vérifiant également que la configuration ne permet pas le JNDI (ce qui est le comportement par défaut depuis la version 2.16.0). Les versions 2.15.0 et 2.16.0 ne corrigent pas tous les problèmes de sécurité, il est donc important de refaire l’update vers la 2.17.0 (au 20 décembre 2021).
Pour la branche 1.x, aucune correction n’est prévue. C’est donc par paramétrage qu’on peut agir, soit en désactivant le JMS Appender, ce qui est le comportement par défaut de la 1.x, soit en enlevant carrément JMSAppender du classpath Java (la classe réalisant les appels JNDI n’existera plus). Précaution supplémentaire : s’assurer que l’utilisateur système (niveau OS) faisant tourner l’application utilisant log4j n’a pas les droits de modifier le fichier de configuration. Il ne faudrait pas qu’un attaquant puisse réactiver le JNDI…
Pour la branche 2.x, la seule vraie bonne solution reste la mise-à-jour ou la suppression du JndiLookup dans le classpath Java (on est alors sûr qu’aucun lookup ne se fera).
Certaines des recommandations antérieures, rappelées ci-dessous, ne permettent qu’une atténuation partielle. Si vous les avez appliquées, sachez que vous êtes toujours vulnérable !
- De 2.7 à 2.10, il faut à chaque directive d’affichage ajouter un paramètre pour empêcher le lookup (ex : %m{nolookups});
- A partir de 2.10, il faut passer le paramètre de configuration formatMsgNoLookups à true;
- Pour pallier les risques d’exécution de code à distance, deux paramètres sont à passer à false :
- sun.jndi.rmi.object.trustURLCodebase
- sun.jndi.cosnaming.object.trustURLCodebase
Ces recommandations sont issues du papier des chercheurs d’Alibaba Cloud, mais ceux qui veulent suivre les évolutions de la situation doivent se conformer à l’avis très complet du CERT-FR, très régulièrement mis-à-jour :
D’autres solutions sont possibles, comme on le voit sur le schéma du CERT Suisse, comme l’utilisation d’un pare-feu applicatif ou d’un filtrage réseau, mais les attaquants modifient rapidement le payload afin de contourner les règles.
Par ailleurs, cette charge utile est tellement triviale qu’elle risque soit de passer au travers des filtres, soit d’obliger à mettre en place des règles qui vont bloquer des requêtes légitimes et créer de nombreux faux positifs. Et n’oubliez pas que les versions ultérieures à la 2.14 corrigent aussi d’autres problèmes de sécurité plus anciens, et que les contournements proposés pour log4shell ne suffiront pas forcément pour ces autres vulnérabilités.
On en a fini ?
Il reste un dernier problème : dans certains cas, il n’est pas possible de réaliser une mise à jour de log4j parce que le système est lié à une vieille version de Java. Cela explique qu’une version 2.12.1 de log4j traîne encore par endroits, car c’est la dernière version supportant encore Java 7.
Vous vous dites qu’il n’y a qu’à mettre Java à jour ? Hélas, ceux qui s'y sont frottés dans des environnements de production savent que toucher à Java peut avoir des effets indésirables catastrophiques, et que sans réaliser de minutieux tests de non-régression, on peut se retrouver avec un système instable ou carrément inopérant.
Un cas très simple pour comprendre : vous avez acheté une fortune un progiciel écrit en Java. Il est tellement cher que vous n’avez pas souscrit aux mises-à-jour et donc vous avez une vieille version qui marche très bien, qui fait ce qu’elle a à faire, mais en Java 7. Ce vieil applicatif ne peut donc loguer qu’avec la version 2.12.x de log4j avec votre vieux Java : si vous faites la mise-à-jour vers la 2.17.0 de log4j, votre applicatif va se planter au démarrage.
Apache a produit une version 2.12.2 le 14 décembre, pour les utilisateurs de Java 7, mais la correction s’avère incomplète et les corrections par paramétrage ne sont pas plus efficaces que sur les versions 2.15.0 et 2.16.0. Apache promet une version 2.12.3 à venir, qui permettra de mettre fin aux vulnérabilités sous Java 7. Le mal de crâne est garanti dans les grandes organisations où pullulent les versions hétérogènes de Java.
À ce jour, il n’y a plus de faille non corrigée, mais on a vu qu’agir vite pouvait avoir des effets indésirables, car l’urgence conduit parfois à proposer des solutions incomplètes ou contenant encore des problèmes. Cette vulnérabilité prend désormais la forme d’une saga (ou d’un cauchemar pour les services IT).
Pour terminer, la liste des produits touchés ne sera probablement jamais complète tellement elle est vaste. Des tentatives existent toutefois pour essayer de mesurer l’impact de cette vulnérabilité dans son système d’information, comme ici ou ici. Même des voitures Tesla ou des serveurs Minecraft sont touchés !

























Commentaires (139)
#1
“Un cas très simple pour comprendre : vous avez acheté une fortune un progiciel écrit en Java. Il est tellement cher que vous n’avez pas souscrit aux mises-à-jour et donc vous avez une vieille version qui marche très bien, qui fait ce qu’elle a à faire, mais en Java 7. Ce vieil applicatif ne peut donc loguer qu’avec la version 2.12.x de log4j avec votre vieux Java : si vous faites la mise-à-jour vers la 2.17.0 de log4j, votre applicatif va se planter au démarrage.”
Merci pour cette illustration si saillante et malheureusement courante du monde du propriétaire (je n’ose dire représentative, car après tout il y a aussi des brebis galeuses dans l’open source qui mettent la majorité des features en premium, mais je le pense néanmoins très fort xd).
Et surtout, MERCI pour l’article. J’avais entendu parler forcément (notamment ici) mais je m’étais pas renseigné plus que ça, c’est top d’avoir une explication pédagogique + une étude d’INpact.
#1.1
Le propriétaire, mais surtout le custom.
Les ESN travaillent majoritairement avec du Java comme backend d’API, pour créer des applications spécifiques aux besoins d’un client, qui n’existent nulle part ailleurs : pas possible bien souvent d’utiliser des composants sur étagère libres ou non, il faut passer par des développements custom.
#1.2
C’est même pire que ça.
Ca concerne également des systèmes embarqués, qui utiliserait du Java Embedded avec du Windows CE. Log4j peut avoir été embarqué et la GUI pourrait exposer des vecteurs d’exploitation.
Des bornes, des automates, des appliances pourraient présenter la vuln, juste par obsolescence (produit non supportés, non maintenus, constructeurs disparus…). Le problème va au-delà de la question du propriétaire.
D’ailleurs, si je reprends la citation:
“Un cas très simple pour comprendre : vous avez acheté une fortune un progiciel écrit en Java. Il est tellement cher que vous n’avez pas souscrit aux mises-à-jour et donc vous avez une vieille version qui marche très bien, qui fait ce qu’elle a à faire, mais en Java 7. Ce vieil applicatif ne peut donc loguer qu’avec la version 2.12.x de log4j avec votre vieux Java : si vous faites la mise-à-jour vers la 2.17.0 de log4j, votre applicatif va se planter au démarrage.”
90% des cas, l’acheteur n’a aucune idée de ce qu’il y a dans le progiciel. Ca m’est déjà arrivé en plein audit, que l’admin sys découvre avec nous qu’un progiciel, c’était un tomcat et postgresql derrière (ça s’affiche pourtant dans les processus). Alors parler de MAJ log4j, oubliez.
Par ailleurs, le progiciel pourrait être tellement vieux, que l’éditeur pourrait simplement ne plus le supporter. Même dans le libre, si log4j 1.x n’est même pas mis à jour, il en serait de même pour des logiciels Open en version non supportés (qui fera les tests?). Là est bien entendu la faute de l’utilisateur (logiciel obsolète).
Je ne sais pas pourquoi, ce que ce soit cet article, ou le précédent traitant du sujet, on retombe sur une saillie sur le propriétaire.
#1.3
+1 Rien à ajouter.
#2
Merci pour l’article :)
#3
Pour Log4j 1.2.x Debian/Ubuntu on fait un fix pour le CVE-2019-17571, cette même version n’as même pas JMSAppender (donc utilisation du CVE-2021-4104 impossible).
#3.1
Idem chez RHEL également
#4
J’ai toujours détesté le Java pour de bonnes raisons, ça en fait une de plus
#5
La meme et je l’ai toujours détesté pour ses problème de sécurité xD, et j’ai toujours détesté apache (open office, httpd, etc).
Perso pour réduire le problème j’ai fermé en sortie les ports relatif a ldap sur mon router/server (ils était déjà fermé en entrée), histoire de réduire la surface d’attaque (et que les attaque utilisent ldap).
#6
Rajoute le port 1389 (port utilisé dans des PoC) car la majorité des tentatives n’utilise pas le port LDAP (389) ou LDAPS (636).
#7
Ce qui me scie le plus dans cette histoire, c’est que la faille existe depuis presque 10 ans, rendant vulnérables les plus grosses boites de la tech, bancaires, les gouvernements etc. et malgré la simplicité de la faille et son exploitation, aucun audit de sécurité ne l’a repérée?
Je sais pas, j’imagine que rien qu’un nom de classe “JndiLookup” devrait allumer deux ou trois warnings chez les infosec, non?
#7.1
log4j est une lib déclarée en dépendance. Le code est donc compilée (.jar)
Le lookup est une feature builtin, cad qu’il n’y a pas besoin de l’invoquer lors de l’utilisation du logger. Juste l’utilisation de la lib suffit.
Aucune société n’audite les dépendances, elles sont nombreuses.
#7.2
Euhhh… auditer les dépendances c’est la base, y’a tellement de choses qui passent par là, les supply chain attacks notamment. J’aimerais savoir sur quoi tu t’appuies pour dire “aucune société n’audite les dépendances” ?
#7.3
Si on parle d’un progiciel : c’est déjà une gageure d’auditer le progiciel en lui-même. A moins de signer un NDA ou si c’est exigé par contrat (par ex, d’intégration), c’est peu probable que l’éditeur fournisse le code source, qui permettrais à l’utilisateur de “revendre” le progiciel (ou simplement, le cracker). D’autant qu’il a intérêt à obfusquer ses binaires (pour ralentir le reverse).
Donc en tant qu’acheteur final, difficile de budgéter une équipe de reverse pour juste valider la sécurité d’un logiciel.
De même qu’en tant qu’éditeur, on va juste s’assurer que les binaires de dépendances ont bien été fourni par le développeur (signature, hash, canal de téléchargement sûr). Même pour des dépendances open-source, quel budget et quels délais consacrer pour vérifier ces dépendances nombreuses?
Combien de vuln ont été reportées par des chercheurs en sécurité travaillant chez Google, IBM, etc etc??? Pas mal.
Combien de vuln ont été reportées par des ESN (très gros utilisateurs de dépendances dans leurs projets)? 0?
#7.4
Dans mon message auquel tu as répondu, je citais justement les big techs, les banques, etc. Évidemment c’est de leur part que je m’étonne de n’avoir pas, ou mal, audité une lib comme log4j. Pas de la petite PME du coin ;-)
Les grosses ESN, je sais pas comment ils approchent la sécurité, mais j’imagine qu’ils doivent pas faire trop à la légère non plus surtout lorsqu’ils sont sur du stratégique / défense etc.
#7.6
Je vois peu d’ESN qui vont aller faire ce genre de choses, excepter, peut être, éventuellement, celles qui en plus proposent des SOC au clients.
Mais très honnêtement, c’est beau l’espoir …
Quand tu vois que certaines ESN savent moins bien que leur client comment fonctionnent leurs progiciels …
#7.5
Faire un audit de sécurité ? Examiner un produit open source pour l’évaluer avant de l’utiliser ? Faire de la veille pour MAJ quand failles ? Nanmého t’es pas un peu fou ? On a pas le temps pour ces conneries…
X mois après… “CHEF C’est la CRRRIIIIIIISE”
Bah ouais, comme toujours quand on agit pas en professionnel, on se mange le retour de flamme…
#8
Auquel j’ajouterai à titre perso : tout port non utilisé doit être bloqué par défaut dans les deux sens.
#8.1
la base .. ce qui n’est pas explicitement autorisé est interdit.
#9
Ajouté merci du conseil. je me doute que certain essayeront de changer le port mais la majorité des “hackeur” de 13 ans qui utiliseront tel quel (qui comprennent meme pas la notion de port) seront bloqué.
Je me doute que c’est un pensement sur une fracture ouverte mais c’est mieux que rien.
#10
J’ai pu constater de mon côté qu’elle est activement exploitée, les logs de mon serveur web perso dégueulent de tentatives d’injection via l’URL (heureusement, aucun runtime derrière pour répondre).
#10.1
#10.2
Une faille non divulguée est effectivement du pain béni pour les attaquants, donc je pense que durant le temps où elle fut discrètement exploitée ça a certainement provoqué quelques belles brèches.
#10.3
Le vrais sujet a en tirer est la rapidité à une faille d’être appropriée par Internet et la nécessité d’être capable de redéployer des versions corrigées trés rapidement. Rien qu’en interne c’était le bordel; entre dsi qui ne voulait pas risquer un plantage applicatif (régression) et CDS de dev qui ne suivaient pas les consignes SSI et se limitaient aux quelques actions qu’ils avaient glané par eux même,(dans notre cas le fait d’utiliser la variable d’env nolookup qui n’etait finalement qu’un paliatif partiel)
Bref que du fun. En tout cas une chouette expérience de niveau de crise majeure. Tout un REX à faire en interne.
#11
J’ai meme vu aussi le cas ou j’avais un logiciel qui était édité par une boite qui n’avais plus le code source (après une vente) et que les deux dev qui l’avais fait son mort ou a la retraite et qu’aucune doc n’existe, donc il est purement impossible de modifié le logiciel, et ce logiciel est le point le plus important de la boite ou je l’ai vu, il leur est donc simplement impossible de le retirer et sont obligé de le gardé (au vu du prix investi).
La pour le coup je sais même pas si leur logiciel est vulnérable et ils ont refusé qu’on en recrée un (on propose toujours un pack avec les sources) pour qu’il puisse modifié le logiciel par un concurrent ou autre dev.
Je suis a peu près certaine que beaucoup de boite/logiciel sont dans le même cas.
#11.1
Et à ce genre d’histoire, d’un côté j’ai envie de lâcher un bon gros “CHEH” pour les incompétents qui ont osé planter pareille épine dans leur boîte, de l’autre je plains les employés de ladite boîte qui sont donc dirigés, au moins partiellement, par des incompétents avérés. Et je prie pour la survie des malheureux qu’on chargerait un jour de développer une solution de remplacement en reprenant les données (vu que bien souvent la solution propriétaire souhaitant te conserver les couilles dans l’étau ne prévoit aucun chemin de migration des données, voire même a développé son format bien propriétaire et verouillé sans specs ni api).
#12
Tu veux dire que des failles de sécurité qu’on retrouve partout (pas qu’en dans des bibliothèques écrites en Java) c’est une bonne raison ?
Dans ce cas là, autant arrêter l’informatique :o
#13
Disons que Java comme notre feu flash, a un nombre impressionnant de vulnérabilité critique et une plus que mauvaise image quand on parle de la sécurité.
En effet les autres language aussi ont ce problème j’en convient.
Mais java est plus lent que les language concurrent et n’apport rien (si on exclus le multiplateforme qui a l’époque était quasi impossible sans java).
#14
“qui maintient éveillé des équipes IT”
You don’t say! Depuis lundi dernier en tant que responsable indus agence je passe mon temps à glaner les infos de la centaine de projets, de leurs dépendances, à compiler tout ça, produire des guide de correction (quand on peut!), balancer des centaines de mails de rappel, et la moitié des gens est en congé…
De belles vacances en perspectives !
#15
Idem, et ce très rapidement après la sortie de la faille.
Par contre, au taf, on a pas mal d’appli qui étaient vulnérables… certaines ont purement et simplement été arrêtées.
Je me souviens d’un CRM Sage bâti sur du .net ET du Tomcat… (allez comprendre…), il y a de grandes chances qu’il soit vulnérable…
#16
Pareille chez nous les deux logiciel vulnérable (non facilement fixable) ont été arrêtée.
Car l’entreprise fait passé la mise a jours des clients (revenu) une fois les clients qui nous on contacté mis a jour (logique vous me direr) on verra ce qu’on fait de ces deux outils.
#17
“De nombreux signalements ont été émis dès le 13 décembre”
Dès le Vendredi 10 décembre à midi on a vu passer des tentatives d’exploitation (petit filtre jndi+ldap dans les logs de l’ensemble du parc)
#17.1
Je parlais des signalements publics, je n’ai pas (encore) accès aux logs de ta boîte Sérieusement, je n’ai pas (pour l’instant) vu passer de publications signalant des attaques plus tôt, mais on risque de faire encore pas mal de découvertes, la faille a très bien pu être exploitée par des équipes bien renseignées avant même la publication officielle. Et à partir du 9, c’est devenu open bar… Mais félicitations à la fois pour le filtre et pour avoir vu aussi vite des traces d’attaques !
Sérieusement, je n’ai pas (pour l’instant) vu passer de publications signalant des attaques plus tôt, mais on risque de faire encore pas mal de découvertes, la faille a très bien pu être exploitée par des équipes bien renseignées avant même la publication officielle. Et à partir du 9, c’est devenu open bar… Mais félicitations à la fois pour le filtre et pour avoir vu aussi vite des traces d’attaques !
#17.2
Disons que dans une certaine grande entreprise qui gère des trains on a –“quelques sites”– exposés. On est passé en gestion de crise dès les annonces et on a vu arriver quelque truc rapidement. On a même pu voir évoluer les tentatives en direct.
#18
Merci beaucoup pour cet article clair et aussi détaillé. Même en ayant fuit le java depuis 20 ans, j’ai réussi à comprendre :)
#19
yep, merci pour l’article :)
#20
C’est pareil que pour Windows et ses “failles” : plus qu’il y a d’utilisateurs, et plus on découvre des vulnérabilités (critiques ou pas). Cela ne veut pas dire qu’il n’y en a pas, et à mon avis, c’est plutôt la réactivité à corriger le problème. ça et la communication.
Quant aux lenteurs de Java, il serait temps de se mettre à jour hein. Java n’est pas plus lent qu’un autre langage, et y a que les langages types C/C++/Rust qui font mieux pour des raisons simples : pas besoin de charger une VM…
Tu trouveras différents benchmark ici : https://benchmarksgame-team.pages.debian.net/benchmarksgame/index.html Have fun à troller ton langage détecté favori.
Bon après j’imagine que ça ne t’empêchera pas de continuer à le penser… Les biais cognitifs, le ressenti, tout ça… :)
#21
Beaucoup de dev ont utilisé java il y a 20 ans par effet de mode, et une bonne grosse partie des software écrit en java sont bien plus lent qu’il n’aurais du l’être car il utilise un language qui n’est pas optimal pour leurs opération.
Enfin java a toujours été un nit a problème de sécurité car quand il a été développé il n’avais pas la sécurité a l’esprit, beaucoup de language souffre de cette tare et ce n’est pas un soucis qui est fixable via une update.
Java (et tout autre anciens language non conçu avec la sécurité a l’esprit ou reposant sur un système impossible a corriger simplement) pour moi doit être évité/remplacer dans “tous projet qui ne le requiers pas en vue de critère objectif” et doit être replacé par des languages “moderne conçu avec la sécurité a l’esprit” de manière progressive.
#22
Pour bosser dans une grosse ESN chez un client classifié Secret UE, c’est la même méthode qu’ailleurs, ils l’ont pas venu venir et vont devoir arrêter plein de logiciel stratégique qui pourrait même retarder des dossiers client a des millions d’euros…
Quand la team qui va devoir réparer ce joyeux bordel est venu me dire cela, pour nous prévenir que côté support utilisateur, va falloir être très pédagogue pour calmer la grogne a la rentrée ^^’
#23
Pour ma part des attaques dans les logs depuis le 10 mais presque aucun site utilise Java.
L’un d’eux sur un extranet était vulnérable mais j’avais mis un code d’accès au niveau du serveur web (un peu comme un htaccess mais au niveau du VirtualHost). Sans ce code pas de sollicitation du java qu’il y a derrière. N’empêche que j’étais bien content d’avoir mis cela en place même si cela fait régulièrement râler certains car deux codes (le code pour l’accès + leur login/pass pour l’appli).
Par contre autre soucis que j’ai eu : arriver à calmer certains qui paniquent et veulent tout couper alors que leur site est entièrement en PHP sans un gramme de java.
#24
Et ce qui me terrifie le plus c’est
Les devs qui implémentes des librairies sans savoir ce qu’elle sont, ni vérifié leur dernière update ou quoi puis oublie et, donc le nombre de logiciels vulnérable que le développeur lui même a oublier et qui répondra via blog que ces logiciels sont non vulnérable.
Les boites ouvertement touchée qui diront ne pas l’être pour ne pas devoir mettre a jours les logiciel client (qui eux ne verront rien et les croiront).
C’est ces deux points qui me terrifie le plus.
#24.1
Chez mon client, on m’as clairement expliqué que c’est le 1er point : la bibliothèque a été intégré dans la conf de projet java interne utilisé par défaut, donc présent dans plein de logiciel même s’il en avait pas besoin ^^’
Bon il y a probablement d’autre endroit où c’est mieux gérer mais c’est pas parce-que c’est (très) sensible que c’est forcément mieux gérer.
On va plus te faire chier juste pour pas que la merdé qui est faite ressorte trop vite.
Pas rassurant tout ça pour la suite, mais un vraie Eldorado pour les hackeurs.
#24.2
#25
Dans mon cas je milite dans la boite pour qu’on ai un suivi (via logiciel) des librairies externe utilisée, histoire en deux point : 1 relancé les clients en cas de mise a jours critique d’une librairie, 2 nous aider nous dev a suivre les updates des librairie externe, car c’est humainement impossible de suivre manuellement autant de librairie, entre les mise ajours de fonctionnalité / sécurité.
Suffi de se tourné coté linux (son coté code ouvert permet de le voir plus vite), (Ubuntu ou fedora) ou on voit qu’il y a 6 ou 7 version différentes de la même librairie car tel ou tel soft la requiert cela démontre un problème généralisé dans la gestion des lib tiers de tous le secteur (le mien y compris).
Il n’y a pas de réponse simple, mais simplement ignorer le problème ne le règlera pas.
#25.1
C’est le B-A-BA de la gestion de conf et de suivi de l’obsolescence.
Sauf que suivre, mettre à jour et tester, ça coute.
Quand t’as une lib qui sert à 6-7 projets simultanément, la mettre à jour implique une cascade de conséquences.
Si ça se faisait facilement, on le ferait déjà…
#25.2
Gros +1, en général, les libs obsolètes, on ne les traîne pas parce-que ça nous fait plaisir mais plutôt par manque de temps pour faire (et gérer) la mise à jour, surtout si elle n’apporte rien de visible.
Comme le fait de changer de langage… dans la plupart des projets existants, le langage est plus ou moins imposé par ce qui est connu dans la société, ce qui est disponible sur le marché, ce qui bénéficie d’un gros écosystème, ou d’un bon support. Dans ma (grosse) boîte, clairement, on trouve du Java, du .Net et du C pour ce qui est le plus critique. Un peu de Python par ci par là et quelque trucs plus exotiques, mais on ne va pas réécrire un soft qui a commencé sa vie en Java il y a 20 ans juste pour le plaisir de le réécrire (on galère déjà assez pour lui faire quitter Java8 !)
Et là, je ne parle que des dév internes. Quand tu as des comportements spécifiques en Java dans tes bases Oracle, pas sûr que tu sois motivé pour tout changer (un exemple parmi d’autres).
Après, je peux me tromper, mais une appli qui embarque une version vulnérable de log4j sans l’utiliser (cas présenté plus haut) est-elle vulnérable à cette faille ? Il me semble qu’il faut qu’un message compromis soit traité par le moteur de la librairie de logging - et que le serveur distant soit accessible, ce qui est peu fréquent dans un SI fait correctement.
#26
libraireest bien une bibliothèque, et leslogssont des journaux.#27
librairie et log, les français on beau avoir traduit les termes “Anglais” ne nous impose pas d’utilisé les version française.
Du cous nos librairy et nos logs, sont fix désormais.
#28
voui, voui, à une différence près : log est le terme anglais correct, alors que librairie est un anglicisme, d’usage incorrect. Soit on dit library, soit on dit bibliothèque. Je ne suis pas opposé à l’anglais, je suis opposé aux anglicismes. Nuance.

Moi aussi !!
!!
#29
Je suis curieux de savoir de quel(s) langage(s) (sans ‘u’, language c’est en anglais) tu parles ?
L’autre souci que j’ai c’est cette notion de conçu avec la sécurité à l’esprit : est-tu capable de définir des critères objectifs permettant de dire que “oui ce langage est pensé comme tel” ?
Par exemple, est-ce que forcer à l’initialisation d’une variable est un critère de sécurité ?
Java
C et C++
PHP
Javascript
Si oui, des 4 langages, seul Java remplit ce critère.
Sachant que là, il s’agit du langage. C’est-à-dire de ce qu’il considère comme erreur potentielle (une variable non initialisée en C peut facilement mener à une segfault, alors pourquoi ce n’est pas obligatoire ?)
Idem pour l’évaluation des branches : si ton langage ne t’impose pas de terminer toutes tes branches avec un
returnou son équivalent dans le langage, ça revient plus ou moins même problème que la variable non initialisé.Ce qui n’empéche pas de faire des erreurs de développement : bien sûr qu’il y a des failles dans Java, mais c’est le cas de tous les langages, même celui pensé avec la meilleure sécurité du monde.
Par exemple, tu peux faire du SQL dans pas mal de langages, … et tu retrouves malgré tout encore et toujours des injections SQL car non utilisation de
PreparedStatement(quand c’est disponible, ex: php 4 n’avait pas ça) ou tout simplement non vérification des paramètres d’entrée.Or pourtant, la validation des paramètres c’est plus ou moins la base de la sécurité dans les programmes : tu as un truc qui ressemble à un identifiant ? Assures toi que ça ait le bon format (nombre, etc).
Et assures toi que la personne connectée ait bien le droit d’y accéder (surtout avec le RGPD : encore pas mal de sites permettent juste de changer un identifiant pour accéder aux données personnelles du voisin).
Quelque soit la bibliothèque, quelque soit le langage, pour moi le plus important de respecter une bonne hygiène informatique :
Sachant que le premier point est plus dur à obtenir quand la bibliothèque est open source, faite sur du temps libre, et que les contributeurs sont différents : il est difficile de dire que tout contributeur ait le même niveau de compréhension du code existant/des problèmes de sécurité.
TL;DR: ce n’est pas Java le problème. Ou alors si: Java Util Logging (embarqué dans le JDK depuis assez longtemps), c’est quand même pas terrible donc les développeurs Java ne s’en servent pas
Quant à l’aspect performance, c’est comme les critères objectifs sur la sécurité inhérente à un langage : ça se mesure et ça dépend du cas d’utilisation.
#29.1
Globalement d’accord avec ça, la vision de Java comme un langage qui serait un nid de failles est imho une vision très éculée, ceci dit il y a quand même des langages réputés plus secure, comme rust (en fait je vois que lui mais sans doute y en a-t-il d’autres). Mais c’est beaucoup moins mainstream dans tous les cas. Dans les langages mainstream, je n’en vois pas qui saute aux yeux.
Gardons à l’esprit aussi que la majorité des CVE vient toujours de ce bon vieux buffer overflow, qui est plutôt l’appanage de c/c++.
#30
Tout à fait.
Encore faut-il vérifier que les dépendances elles-mêmes n’utilisent pas log4j. Dans tous les cas, si on l’a dans son classpath, mieux vaut la mettre à jour (une lib de log c’est pas le plus difficile à mettre à jour en général) ou virer la classe JndiLookup (ne serait-ce aussi que pour se prémunir des futurs usages)
#31
On dit bibliothèque quand c’est open source, et qu’on peut se servir gratuitement (en l’échange d’une carte, appelée LICENCE).
Et on dit librairie quand c’est payant.
Ce n’est pourtant pas compliqué !
Exemple : log4j2 est une bibliothèque Open Source, IBM WebSphere MQ est une librairie.
(sur ce, je sors)
#31.1
N’importe quoi. Ça vient juste de l’anglais “library”, souvent mal traduit en “librairie” en français, au lieu de “bibliothèque”. Aucune notion de payant/gratuit/libre là dedans…
#32
Pourquoi crois tu que je milite pour qu’une réponse logicielle soit développée en interne pour suivre les dépendances de manière automatisée ?
#33
Donc si je comprend ton point de vue flash n’aurais jamais du être abandonné ?
qui a pourtant été abandonné pour sa sécurité plus qu’exécrable.
Certain language sont plus vulnérable que d’autre c’est un FAIT.
Ma position de vouloir réduire leur utilisation au maximum est donc une position justifiée et justifiable, même si tu ne la partage pas.
Pour ton exemple du C/C++, fait intéressant elle est lourdement vulnérable au dépassement de mémoire, et c’est d’ailleur JUSTEMENT pour ca que plusieurs projet réécrive les lib en RUST.
#33.1
J’aimerais quand même bien savoir quels langages tu considères comme secure ou pas, autant pour rust je comprends, mais pour moi tous les autres (java, c, c++, c#, php, js, python…) sont à peu près dans le même sac. Donc la comparaison avec flash, comment dire… si on va dans ce sens, on jette tout aux orties et on ne garde que rust. C’est ça l’idée ? 🙂
#33.2
Oui enfin là, log4shell ce n’est pas une vulnérabilité du langage Java en soit, mais une mauvaise configuration par défaut dans un projet codé en Java.
#33.3
Certes, mais le bordel créé par Oracle autour de Java fait qu’on se retrouve avec du Java 7 qui date de 2011. Le problème de Java, c’est pas Java, c’est Oracle.
Quant aux problèmes de dépendances, je dirais que Java est mieux loti que Node, Python ou autre langages avec un SDK encore plus limité et qui dépend encore plus de contributions tiers.
Mais Java pâtit ici de son énorme part de marché.
#34
Tu ne réponds pas à ma question.
Flash est un logiciel propriétaire et dont l’utilité est devenue moindre avec le temps (comme les applets Java) vu que Javascript permet de faire beaucoup plus de choses maintenant. Y a même des émulateurs Nintendo 64 ou Flash en Javascript, c’est dire !
Vu que utilité moindre + cout de maintenance de l’éditeur + problème de sécurité lié au sandboxing plugin/navigateur/runtime, c’est pas étonnant que l’éditeur ait arrêté. On parle d’Adobe : si Javascript et CSS3 permettent de faire tout ce que permettait Flash, Flash n’a alors plus d’intérêt.
Et dire qu’un langage est plus vulnérable qu’un autre, ce n’est pas ce que je ne dis pas.
Je te demande de fournir un exemple de langage qui correspond à tes critères de sécurité.
J’imagine que si tu parles de langage, c’est que tu développes un tant soit peu ? que tu connais un minimum le sujet ?
Je dis ça car j’aimerai bien comprendre ce ressenti à mon sens absurde vis à vis de Java, sur l’aspect sécurité - les lenteurs, c’est encore un autre sujet (et hors sujet par rapport à l’article :)).
Surtout quand le langage même a des structures (mémoire via gc, évaluation des branches, etc) qui sécurise la machine virtuelle…
#35
Il me semble que pour la sécurité de Java, c’est surtout le plugin des navigateurs qui était critique.
Comme Flash (et d’autres), souvent laxiste sur la sécu, et sans possibilité pour le navigateur de contrôler ce qu’il faisait.
La faille principale étant souvent l’utilisateur qui lui donnait des trucs louche à faire tourner.
Ils ont compris, un peu tard, qu’un utilisateur lambda n’a pas à savoir faire la différence entre un gif animé et un programme Flash, ou Java, qui peut faire beaucoup plus de choses en plus de lui afficher une pub rigolote.
Je suis pas dev, mais j’ai cru comprendre que le pb n’est pas le “langage Java” en lui-même, mais globalement “Java” quand on essaye de lui faire faire des choses qu’il fait mal.
Dans le trillion de failles qui ont frappés Java, il y en peut-être sur le langage lui-même, mais l’essentiel doit être sur le plugin ou sur la JVM qui laissait faire des trucs qui n’étaient pas prévu par ses concepteurs.
#36
Le Java a eu beaucoup de vulnérabilités dues à la réflexion et à la serialization.
Il existe beaucoup de solutions qui scannent les dépendances et les comparent avec une liste de dépendances marquées comme vulnérables. Après, auditer les dépendances une à une… Si le projet utilise springboot, tu es parti pour auditer la moitié du repo maven.
Certains langages comme rust sont intéressants mais vas-y pour former une équipe de 5 bons développeurs. Si tu travailles sur un projet un peu costaud, il sera plus facile et moins cher de former une équipe de dev java. Aussi, l’écosystème autour de Java est bien avancé (CI/CD). Il n’y a pas que le langage dans un projet, mais toute la chaîne.
Finalement, les langage de programmation n’est qu’un outil qui dépend beaucoup de celui qui l’utilise. Par exemple, même avec les meilleurs outils de dentiste, vous n’allez pas vouloir que je vous soigne une carie
#37
d’ou ma phrase, remplacé progressivement, si on commence jamais a remplacé des composant, ou a engager des gens sur des languages plus moderne ca changera jamais.
J’ai jamais demandé qu’on remplace tous ni meme donné de vitesse de remplacement (c’est impossible de tous remplacé de toute facon) mais commencé par les composant les plus critiques, genre une librairie en C++ qui gère des trucs de sécurité qui pourrais être vulnérable a un dépassement de mémoire la réécrire en rust, mais si le code qui gère l’affichage du titre lui n’est jamais remplacé on s’en fous.
Enfin si une équipe de java (par exemple) avait un expert en rust, qui peut compilé du code critique en rust et faire tourné le reste du logiciel en java), ca amène la sécurité qu’implémente rust sans trop réduire l’efficacité de l’équipe.
Et au fur et a mesure des départs et engagement tu peut inversé la tendance et augmenté la proportion de language moderne.
Parfois j’ai l’impression que les dev oublie que rien n’empêche un language d’appeler des composant compilé par un autre langage, et qu’un logiciel compilé avec de multiple langage peut être plus rapide et sécurisé (si bien fait) qu’un language unique pour tout.
#38
Les macs sont (étaient ?) vulnérable simplement en scannant les wifi à proximité :
https://github.com/YfryTchsGD/Log4jAttackSurface/blob/master/pages/apple.md
Une borne wifi avec le nom qui va bien, un mac scanne les réseaux à proximité, le mouchard de télémétrie d’Apple se déclenche et mémorise le nom des bornes et la position du mac, pour “améliorer les données de localisation”.
Sauf que le mouchard Apple se base sur log4j :facepalm: …
#38.1
Suffisait de changer le nom de son iPhone avec la payload qui va bien pour hacker iCloud ;-)
#39
Il faut connaitre son langage et notamment son niveau d’abstraction :
Le Rust est un bon compromis sur ce point : tu as les perfs du C et la sécurité d’un modèle de mémoire infaillible. (bon faut réussir à capter le tas et la pile et compiler son code :) ) Mais le langage est difficile d’accès donc tu ne peux pas tout dev en Rust (sinon bonjour la maintenance quand personne ne connait le langage) il faut le réserver pour les endroits critiques (bibliothèques ou fonctions critiques) .
#39.1
Tu sais, on utilise encore du Cobol dans pleins d’endroits critique et surtout pour le backoffice jusqu’à maintenant.
#40
Je suis de bonne humeur ce matin alors je participe au troll Java et consort .
.
Pour info, 8ans de java et dans les équipe de support au dev. Je peut dire avec une grande certitude que le soucis se trouve entre la chaise et le clavier! Changer de langage ne changera pas les dev mais ajouterais beaucoup plus de failles dans les applications. J’en ai vu des belles et j’imagine pas ce que ça aurais été en C/C++/Rust, Java à l’avantage d’avoir la JVM qui optimise énormément le code de merde et qui nettoie les saleté.
Un exemple: on doit appeler la BDD, mais renvoyer le résultat uniquement si il y a moins de 100 entrées et en parallèle on met le resultat dans un fichier.
Avec Java au moins on a pas eu de fuite mémoire.
Comme tous les langages, Java a les problèmes que sa force amène: son universalité. Tu veut chercher des objets stockées dans un LDAP distant? On a la solution. Oui c’est débile, oui c’est dangereux mais certains en avaient besoin donc Java le permet.
J’ai lu a de multiples endroits que les dev logs4j avaient dit que le lookup était débile, mais ça à été demandé et voté donc ils l’ont fait (a prendre avec des pincettes, je suis pas remonté à la source, les mailing list c’est pas ma tasse de thé).
En ce qui concerne Rust, j’en fait en perso depuis 6mois pour des petits projets. J’adore le langage, et il ne remplacera pas Java. C’est pas sa cible tout simplement.
Et comme dit avant, les principales failles Java concernaient les applets, qui était une mauvaise idée, vendue comme une sandbox invulnérable et qui à été bien trop utilisé. Du coup même genre de faille que Docker, flatpak et autres sandbox.
tl;dr: On peut faire du caca avec tous les langages et certains Dev/Client s’en donnent à cœur joie. Le « soucis » et l’avantage de Java est qu’il permet de « tout » faire et certains en profitent pour « mal » faire.
#41
IBM WebSphere MQ est une bibliothèque.
Le mot français pour library est bibliothèque, que la licence de celle-ci soit gratuite ou payante. En néerlandais on dit bibliotheek, en espagnol biblioteca, en polonais biblioteka, en portugais biblioteca, en russe библиотека, etc. En allemand on dit Bibliothek ou Library, et en italien on dit biblioteca ou libreria.
Le mot anglais pour librairie est bookshop.
#42
Très bon article, merci Jean.
C’est impeccable parce qu’on peut envoyer ce genre d’article à des personnes qui n’ont pas forcément l’envie ou le temps de se documenter ailleurs.
Merci
#43
Ca c’st le vieux monde. Le nouveau monde c’est:
“Nous utilisons des technologies opensource mais nous sommes incapable d’installer notre soft, nous fournissons du SAAS ou des VM. Nous sommes incapables de patcher les couches basses car nous n’avons plus les (la) ressources qui ont créé la base du logiciel. Mais on est opensource!!!”
Après, le truc c’est que avec un peu de sécu (genre: aucun serveur ne peut initier une communication vers l’extérieur), on a un peu de temps pour patcher.
Tu n’es donc pas un programmeur.
La mauvaise image de Java vient:
Là où Java à imposé une vision plus moderne du dev:
Java a des défauts, mais alors dire qu’il est lent à l’époque Python, Javascript, et après la période PHP pré-7 (à partir du 7, les optimisations PHP sous la pression de FB ont permis de diminuer le nombre de serveurs, souvent en divisant par 2 leur nombre), c’est mal connaître l’outil.
Après, il reste LE problème: quand Java c’était SUN, on avait une certaine confiance dans son avenir gratuit, quand c’est devenu ORACLE, on l’a pas mal perdue…
#44
Du point de vue de l’administrateur système et réseau, le problème du java c’est que, trop souvent, on a juste un .jar, .war ou un truc java web start. Pas de source, pas de mise à jour (où hors de portée de nos moyens financiers), pour savoir les dépendances incluses, on peut toujours partir à la pêche, mais de toutes façons on ne pourra pas les mettre à jour. C’est souvent très dépendant de la version de java (voire de si on prend l’implémentation libre ou le binaire fourni par Oracle).
Oracle facture désormais très cher quand on a besoin d’une vieille version, et en plus ça engendre plein de failles de sécurité. Les applet java ont été abandonnées, puis le java web start, du coup on se retrouve sans vraie solution de secours.
Sans doute faute d’expérience en java, je trouve souvent plus simple de faire tourner de vieux binaires en reconstituant les librairies dépendantes que d’arriver à faire tourner de vieux logiciels java.
Bon, les applis en php qui passent mal d’une version à l’autre c’est aussi très courant, mais sauf obfuscation on arrive généralement à s’en tirer.
#45
Donc tu fais trois fois la même requête pour des usages différents qui peuvent tous exploiter le jeu de données de ta première requête ? Non seulement je ne vois pas le rapport avec une éventuelle fuite mémoire, mais je trouve que c’est au contraire l’exemple parfait de la contre-efficacité…
S’pas comme ça que tu vas lutter contre la réputation de lenteur de Java, à laquelle je souscris sans faille : les solutions logicielles Java que j’utilise, notamment Confluence et Jira pour pas les citer, demandent toutes des ressources minimales largement plus conséquentes par rapport à leur périmètre fonctionnel si on projette une réalisation similaire dans d’autres langages. Après c’est peut-être propre aux applications web. J’utilise peu de solutions “desktop” (à part LibreOffice, mais mon usage est tellement basique que pour le coup c’est bien fluide ^^).
#45.1
Il y a une grosse méprise donc je le répète. Je suis dans l’équipe qui fait, entre autre, le support des Dev. Je les aide quand ils arrivent pas à débug, quand ils comprennent pas les perf et pour tout ce qui tourne autour du dev (git, CI/CD, docker, IDE etc).
Le cas que je t’ai montré viens d’un ticket que je résumerais à « C’est trop lent, le client tombe en timeout, ça à commencé à la migration Docker, c’est de votre faute. ».
Et l’exemple que je donne est bien stupide, crade, tout ce que tu veut. Mais c’est un code que des Dev avaient pondu et livré en Prod.
Donc imaginer ces même dev faire du C/C++ -> fuite mémoire immédiate et « On a cas reboot toutes les X heures » (du vécu encore malheureusement).
Je le redit. Le soucis c’est pas le langage, c’est les Dev la plupart du temps.
Et le cas log4j le montre encore. Si les requêtes extérieures sont filtrés en mode whitelist, la faille est beaucoup moins flippante. Mais dans certains SI on ne filtre que ce qui rentre, « on vas pas ralentir les Dev en imposant une demande d’ouverture à chaque fois ».
#45.2
Je confirme aussi que (je boss en réseau), c’est TRES courant qu’on se fasse accuser d’avoir un réseau “lent” alors que 95% du temps, c’est l’appli qui est codé avec des palmes (voire pire) et qui, effectivement, fait des “DIZAINES DE MILLIERS” d’appels réseau pour télécharger quelques MO.
Les appels BDD étant particulièrement violents dans certaines applis, j’ai déjà vu en analyse une appli qui faisait une requête réseau par LIGNE de BDD. En gros plutôt que de télécharger la table (“array” il me semble ?), ça téléchargeait ligne à ligne. Et ca le faisait 3 fois de suite ! (une fois pour regarder, une fois pour “valider” ce qu’il faut prendre et une troisième fois pour “récupérer les bonnes entrées”. (en plus c’était IBM le dev…)
A un moment ils ont migrés dans le “cloud” et ils sont passés de ~10-15s de temps de réponse à plusieurs minutes entre un serveur “on prem” et un cloudeur (en plus on était bon côté réseau, il y avait qqchose comme 20ms de latence entre les deux) et qui on a accusé ? Des semaines de taskforce d’incidents à expliquer 40 fois la même chose au responsable applicatif qui ne comprenait rien, et bien sûr appli en prod et livré donc cacahuète pour modifier quoi que ce soit.
Je pense qu’en réseau, l’éloignement de la BDD avec le front/middle c’est le plus criant pour repérer une appli pourri, ça se ressent immédiatement niveau utilisateur.
#45.3
Les choix d’architecture n’indiquent pas si l’appli est pourrie.
Entre avoir 9 postgresql qui tournent à 10% chacun, , et 1 postgresql qui tourne à 90% (grosse approximation), le cout en terme d’investissement est totalement différent (hors sauvegarde, SLA, HA…) et les contraintes d’exploitation sont différents.
Pareil pour les processus. Entre implémenter des requêtes atomiques ou implémenter des processus généraux, tout dépends des besoins et usages pour indiquer quels concepts à implémenter.
Parce qu’à l’inverse, travailler avec des resultset de plusieurs millions de lignes pour en modifier que quelques-uns, est tout aussi aberrant (quelqu’un parlait d’optimisation de ressources?)
Des jointures pour filtrer la dite table est aussi couteux en perf de bdd.
C’est l’architecte logiciel qui doit identifier les impacts en performaces et proposer des solutions.
Si ça se trouve, dans le contexte de l’application, il aurait fallu avoir des To de ram pour stocker ces resultsets en mémoire… (multithreading, etc…)
Pas de règle général donc, même si dans l’absolu, je suis d’accord, la bdd ne doit pas être loin (plus facile pour isoler un SI d’un autre, moins de contraintes bout en bout dans le SI), mais des contraintes organisationnelles (au moins en termes d’investissement) peuvent être présentes.
#46
Suite à ce fiasco, j’ai exigé et obtenu le remboursement intégral de nos licences log4j
Ayant longtemps été dev C++, j’ai une appréciation positive de la sécurité en Java, étant donné que ça a enlevé la classe de problèmes les plus chiants du C++: la gestion de la mémoire (dépassements de tableaux, utilisation après libération…) qui non-seulement sont-pénibles à investiguer, mais un gros risque. Je préfère un dev peu consciencieux en Java qu’en C++.
Par chez moi, nos softs sont basés sur de l’opensource, et si on devait tout mettre à jour tout le temps il faudrait des gens dédiés à longueur d’année, donc on met à jour que pour la sécu ou les bugs visibles.
#47
Je vais devoir expliquer la blague : une bibliothèque, tu empruntes, une librairie tu achètes. :)
Je me demande quand même si pour Confluence, JIRA et Bamboo (histoire de compléter) ce n’est pas lié à une problématique de coûts : tu paies cela en fonction du nombre d’utilisateurs et ça ne m’étonnerai pas que tu paies aussi en fonction du nombre de processeurs/RAM/etc.
Aussi, j’imagine que ce sont des solutions installées manuellement et dont les configurations ne sont pas forcément mise en phase avec l’utilisation. Les nouvelles licences JIRA passent en mode Cloud si j’ai bien compris, et donc plus d’installation on premise. Pour le meilleur ou pour le pire, va savoir :)
Ceci étant dit, je pense que la partie front - en HTML + Javascript - est quand même bien bugguée et source des lenteurs : sur Firefox, pour éditer une page confluence, ça revenait à chaque fois en début de page. En passant à Edge/Chrome, pas le problème, mais par contre ça laggait sévère pour éditer le document.
J’ai fini par utiliser un éditeur texte.
A mon avis, ton problème c’est une différence entre avoir le code source (donc open source) et avoir un binaire (donc boite noire).
Tu prends PHP en exemple, mais je ne pense pas que tu te sois amusé à recompiler PHP, probablement une installation via ton système (
apt get php, etc). Sachant que tu n’as aucune garanties que le code binaire corresponde à son code source (*)A mon avis, le problème que tu as - de ne pas avoir le code source - c’est que tu ne peux pas lancer d’audit interne de sécurité.
(*) je sais qu’il existe https://reproducible-builds.org/ mais je ne sais pas si tu peux “marquer” un binaire pour le rattacher à son code source et son environnement de compilation.
#47.1
#47.2
Solutions Atlassian toujours utilisées en mode “serveur at home”. Ce qui a d’ailleurs bien dégoûté le Ministère où je travaillais qui ont acheté des licences pour plusieurs milliers d’utilisateurs avant d’apprendre le changement drastique de politique d’Atlassian en mode “allezzz, venez vous faire tenir par les couilles, promis notre étau n’est qu’en acier zyngué à pressoir automatique 10000 bars”.
(Ils étaient déjà assez loin de l’état d’esprit des premières années depuis qu’ils sont devenus les ténors du marché, mais ce tacle à la gorge qu’ils ont fait à toute leur communauté, m’est avis que ça va leur revenir dans la gueule vitesse grand v. Y’a aucun concurrent au niveau en mode “fonctionnalités sur étagère” mais entre payer plein pot en s’enfermant et partir sur une solution concurrente quitte à payer du dev interne/externe pour configurer et enrichir… Je pense vraiment que la majorité préfèrera la deuxième option)
#48
C’est justement ce que j’ai compris qu’il voulait montrer, vu qu’il parlait de code dégueu juste avant. Il a donné une exemple de code dégueu et inefficace à souhait, et a dit qu’au moins, le fait d’écrire une horreur pareille en Java ne provoque pas de fuite mémoire.
Car un développeur capable de produire ça et qui le ferait en C++ aurait certainement oublié de libérer la mémoire de 2 requêtes sur les 3. Après de toute façon un développeur C++ aussi peu rigoureux n’aurait aucune chance de survie, mais on peut trouver des cas moins extrêmes.
Sa conclusion est donc que la réputation de lenteur de Java vient du fait qu’on peut faire du code dégueu avec sans que ça plante, et donc qu’il y a forcément une plus grande proportion de code dégueu et lent en Java que dans d’autres langages. Surtout auparavant, car maintenant il y a d’autres langages encore plus simples pour faire des horreurs.
Après le Java reste lent par rapport au C/C++ et maintenant Rust, et face au C# dans une moindre mesure. Mais c’est sûr que vu la montée du Javascript, et encore pire, du Python, aujourd’hui on ne peut plus considérer Java comme lent globalement, pas parce qu’il serait devenu plus rapide, mais surtout parce que le reste autour est devenu (beaucoup !) plus lent.
#48.1
+1.
Et en ce qui concerne la lenteur et la consommation de Java. C’est un choix d’archi a faire au lancement du projet.
Payer un bon Dev C/C++ et valider que le code est clean est bien plus cher (le temps c’est de l’argent) que d’acheter un nouveau server à 10k€ à ajouter une bonne fois pour toute dans un DC.
Pour de l’embarqué Java c’est pas fait pour, oui je connais Javacard et non merci.
Pour du service, dans des boites qui ont leur propre DC. C’est moins cher, ça fonctionne bien, ça se monitor facilement.
Le conteneur docker minimal dans mon ancienne mission avais 1vCPU et 512mo de RAM. Pour un petit service c’est énorme, dans un SI avec 400+ applications en 2sites 2colonnes avec 20% des server un backup c’est une goutte d’eau.
#48.2
Aaaah ok je comprends mieux. Merci pour l’explication. Je trouve son exemple un peu capillo-tracté quand même, mais pour avoir connu un “développeur expert” qui faisait des trucs encore pire que moi je faisais en tant qu’amateur, je suis obligé de reconnaître que c’est du domaine du possible (j’hésite entre et
et  d’ailleurs)
d’ailleurs)
Au passage… “il y a forcément une plus grande proportion de code dégueu et lent en Java que dans d’autres langages.”
Ce qui peut aussi simplement s’expliquer par le plus grand “volume” de code et de développeurs sur ce langage overall, non ?
Je m’aventure peut-être, n’ayant aucune source à fournir sur ce sujet, mais c’est vaguement l’impression que ça donnait…
“C’est du code que les devs ont livré en prod”.
Eh beh… Mes condoléances, y’a des coups de pied du cul au crâne qui se perdent…
#49
Ah nan même pas spécialement les failles, juste le langage en lui-même que je trouve absolument atroce, sans parler de l’environnement de développement et des frameworks.
En tout cas avec tous mes softs en .Net Core (voire .Net 6) je dors sur mes deux oreilles
#50
Aucun de nos serveurs, que ce soit dev, qualif ou prod n’a accès à internet, et seul les ports apache tomcat et sgbs sont autorisés en entrée, après avoir fait une demande d’ouverture de flux, accordée automatiquement si le flux est sur liste blanche, sur autorisation pour les flux gris et refusé pour les flux noir.
Donc même avec la faille, impossible d’aller chercher une charge utile sur un serveur externe.
#51
Ne pas oublier que ce vecteur d’attaque est connu depuis plus de 5 ans… C’est juste la découverte de la mauvaise configuration de sécurité de base dans Log4j qui est récente.
https://www.youtube.com/watch?v=Y8a5nB-vy78
#52
Comment cela se présente-t-il concrètement ?
#53
C’est faux. Quand j’étais consultant en cybersec, il m’est arrivé chez des clients de bloquer des déploiements car les dépendances utilisées au sein de l’appli étaient obsolète, avec des vulnérabilités connues.
C’est marrant quand l’éditeur ne comprend même pas pourquoi le projet est bloqué…
#53.1
On ne parle pas de gérer l’obsolescence et le suivi de version/vuln connues, on parle de récupérer le code source des dépendances et de les auditer pour trouver des vulns.
Rien à voir.
#54
On fait une demande d’ouverture de flux via une appli, en précisant son utilisation, et c’est examiné par une équipe sécurité quand le flux est de type gris.
#55
Merci pour l’article.
Ni connaissant rien, c’est déjà un peu plus clair ☺️ Je comprends en tout cas le fonctionnement de la faille.
Mais ce que je me demande et que je n’ai pas trouvé, quel impact cela a sur un utilisateur lambda comme moi.
Est-ce que mes informations personnelles sur différents sites peuvent être récupérées ? Est-ce que cela craint pour des achats en lignes, ce genre de chose ?
En tout cas courage aux équipes qui doivent gérer ça. Ça a l’air d’être un gros bordel pas si simple a corriger !
#56
Ah bon…
As-tu des chiffres à l’appui concernant Java qui aurait particulièrement de problèmes de sécurité ?
Oui, et même d’avantage, si on prend des langages comme le C ou le C++ (moins de vérifications de bornes).
Plus lent, non. On n’est plus en 2000. Et pour avoir développé dans pas mal de langages (et commencé avec assembleur et C), j’ai trouvé que le développement en Java, quand on avait de l’expérience, était agréable et efficace, en particulier avec des outils comme Eclipse.
#56.1
pour le coup, Eclipse, les fois où j’y ai touché, c’était pas top, et la lourdeur de l’IDE était souvent reprochée à java (à tord ou à raison ça je peux pas dire)
(c’était juste pour illustrer les reproches faits à java)
la responsabilité du langage c’est de “masquer” les conneries des dev’ en fait, si à la compilation ou a l’exécution y’a un gros crash, tu sais que le dev’ à fait une bourde (et y’a peu de chance que ça parte en prod), si au contraire le langage “masque” tout ça et reporte le crash dans le temps, il arrive effectivement que ça finisse en “on reboote le serveur tous les … car sinon ça plante” et personne regarde et donc s’étonne qu’un service bouffe 10 go de ram alors qu’il manipule 200mo de données (exemple au pif, mais qui me semble plausible)
note : je suis dev’ php, sous phpstorm (du java parait-il, qui tourne mieux que les fois ou j’avais Eclipse comme ide php, mais y’a peut-être aussi le fait que la machine sur laquelle je bosse est bien plus puissante qu’à l’époque … difficile de vraiment comparer, d’autant plus que phpstorm est fait pour faire du php, Eclipse peut faire beaucoup de choses, dont du php, mais peut ne pas être configuré de manière optimale)
#57
Le lenteur est très relativement et surtout une histoire du passé. La consommation mémoire, ça y ressemble, c’était vu comme élevé dans les débuts, mais ça a changé avec l’augmentation des configurations.
J’ai débuté en Java en 2000 et à l’époque les serveurs n’avaient pas beaucoup de mémoire (j’en avais avec 128 ou 256 Mo me semble). Alors ça commence à être limite pour de l’embarqué mais c’est l’embarqué de maintenant facile :-) . Effectivement Java à l’époque c’était pas le meilleur pour l’embarqué, où on parlait de quantité en unités de Mo.
#57.1
Je suis d’accord avec toi en grande partie. J’aime toujours autant ce langage et je suis toujours admiratif concernant la capacité de la JVM à encaisser les code bien moisis.
J’ai bossé dans du bancaire avec des SLA de 200ms sur des petits server sans soucis. Puis pour de l’assurance sur de gros server (512mo pour un petit service, c’est pas mal) sans SLA, avec un timeout fixé à 60s par le reverse-proxy et que les Dev arrivaient encore à vouloir repousser.
Avec la disponibilité de la memoire et son prix, c’est généralement pas un soucis.
Pour tester Rust je m’étais fait un mini comparatif avec un CRUD Rest.
Java compilé avec GraalVM -> 90mo et 15-20ms de boot.
Rust -> 6mo et 3ms de boot, chargement de sqlite embarqué compris.
Il y a une différence, autant en temps de Dev (1h pour le faire en Java dur de faire mieux) qu’en consommation mémoire et perf au boot. Tout est une question de balance perf/prix, et Java reste bien plus compétitif à ce niveau la.
#57.2
J’avais plus ou moins réécrit un programme serveur en Java simple il y a quelques années. Dans le processus, j’étais allé voir mon chef pour lui proposer de le migrer sur Spring Boot, il m’avait demandé de vérifier les perfs.
Module Java simple : temps de démarrage immédiat.
Module Spring Boot : minimum 30s.
Non seulement on est restés sur du Java simple, mais j’ai plus tard fait un gros boulot de réduction des dépendances pour ne garder au final quasiment que le strict minimum : cryptographie et logging. Sur logback, si je ne m’abuse
Mon pire souvenir de code : quand j’avais dû faire évoluer un logiciel de gestion de bibliothèque écrit en Perl par quelqu’un qui estimait sans doute que la notion de “documentation” était absolument superflue… j’ai dû passer 2 à 3 semaines pour réussir à comprendre comment fonctionnait le bousin (j’étais plutôt néophyte en Perl, et si on me demande, je ne connais pas ce langage )
)
#58
Il y a une partie due à l’effet de mode, une partie due au support des constructeurs et éditeurs (Sun, IBM, autres), mais pour l’essentiel Java a eu du succès car il a été bien pensé en utilisant les acquis de l’époque, et a bénéficié rapidement de tout un ensemble de bibliothèques. Vers 1998 le Java était estimé 50 fois plus sûr que le C++, car on peut beaucoup plus facilement faire des erreurs avec le C++, qui permet beaucoup de choses (puissance expressive mais avec les risques associés).
Quant à la lenteur, ça ne veut rien dire ; dans beaucoup d’applications existantes, ce qui ralentit éventuellement les choses ce n’est pas l’exécution du code proprement dit mais le reste : réseau, base de données. Je ne connais pas l’état actuel des sites, mais de grands sites bien fréquentés ont été écrits en Java et ils n’étaient pas plus lents qu’un autre.
Java a été muni assez rapidement de mécanismes de compilation “JiT” (Just in time, à la volée) qui ont bien amélioré les performances.
“non conçu avec la sécurité à l’esprit”, ça sort d’où ça ?
Quels seraient les langages plus particulièrement conçus “pour la sécurité” et qui sont répandus ?
“un système impossible à corriger simplement” ?
#58.1
Si je ne me trompe pas, la compilation JiT, c’était un des apports majeurs de Java2. J’ai plus la date en tête, trop vieux !
Moi mon chef vérifiait systématiquement que mes boutons “Annuler”… ne faisaient effectivement rien. Il était potache
En même temps il utilise Eclipse, tout est dit
Sinon, d’un point de vue général, il ne faut pas oublier qu’il existe aussi des outils pour aider à auditer le code, typiquement une entrée utilisateur utilisée directement, avec des outils de contrôle de qualité de code dans le pipeline CI ça se repère bien.
À condition évidemment que l’outil soit au courant de la faille, je pense que pour le logging ce n’était pas forcément le cas, mais ça va sans doute venir.
#59
Je vais faire le en ajoutant que quand j’ai commencé à programmer des trucs simples dans les années 80, mon père m’avait dit “tu dois vérifier tout ce que l’utilisateur entre [ l’utilisateur c’était moi en premier ], afin entre autres d’éviter de planter bêtement le programme”, et on ne parle que d’un simple programme local.
en ajoutant que quand j’ai commencé à programmer des trucs simples dans les années 80, mon père m’avait dit “tu dois vérifier tout ce que l’utilisateur entre [ l’utilisateur c’était moi en premier ], afin entre autres d’éviter de planter bêtement le programme”, et on ne parle que d’un simple programme local.
#59.1
c’est bien ça le problème, avant une mauvaise donnée en entrée faisait planter
maintenant y’a quelques vérifications automatiques qui font que ça “plante plus”, cependant ça a été détourné et fau(drai)t vérifier que non seulement ça plante pas (relativement facile à faire) mais en plus que ça ne puisse pas être détourné pour faire quelque chose qui “fonctionne” (plante pas) mais qui est “illégal”, et là c’est plus compliqué à vérifier.
si on n’a jamais eu de crash car on n’a pas vérifié les données (au pif, saisir du texte dans un champ qui va être enregistré en int dans une base de données, mais qui se retrouve banalisé en “null” ou “0”, le dev’ peut ne rien voir, et du coup ne pas prendre l’habitude de faire les vérifications de base de ses données d’entrée …)
#60
Il faut rappeler que Flash s’est énormément répandu juste pour visualiser des vidéos ; chose que je n’ai jamais comprise d’ailleurs, il suffit que (comme depuis un bout de temps) le navigateur ait accès au codec de la vidéo.
Le Flash a également été utilisé pour faire des sites ou des parties de sites, alors c’était joli, mais pas terrible pour l’accessibilité et d’autres choses.
Disons qu’ils permettent plus facilement de faire des erreurs (C/C++ par exemple), mais de là à dire que le langage est vulnérable, ça ne veut rien dire.
#61
Sur la non-recompilation, je me rappelle avoir développé des applis en J2EE où tu peux juste recompiler une classe (prend quelques secondes à peine) et la déployer en temps réel sur le serveur (sans rien devoir relancer), c’est extra pour les mises au point rapides.
#62
Je confirme.
Joli
J’ai toujours halluciné de ce que certains développeurs arrivaient à faire comme code pourri. Parfois rien qu’en copiant 12 fois les mêmes 10 lignes avec juste une ou 2 valeurs qui changent à 2 endroits… Dès que je vois que je recopie plus de 3 fois, je mets les 10 lignes dans une fonction, et le code est drôlement plus clair à lire, en plus d’éviter les erreurs lors ces copier-coller-modifier.
Faut reconnaître que c’est “costaud” comme dev.
Si je ne dis pas de bêtises, tu peux regarder ce qu’il y a dans un jar/war (c’est une archive, en général au format zip), donc avoir les noms des bibliothèques incluses ; et sinon, dans la commande utilisée pour lancer l’application, s’il y a des dépendances externes, elles sont visibles ou déductibles via les “classpath” ajoutés.
#63
Historiquement, jusqu’à au moins Flash 5 (j’ai arrêté de dev du Flash à cette version), il était déjà très répendu, et ne savait pas lire de vidéo. Un fonctionnalité très réclammée par les developpeurs puisque justement, les navigateurs nu en était incapables aussi. Il fallait des plugins Quicktime, Real et autres pour faire ça.
#64
Pff jamais tu battras “mon” développeur “senior / expert Drupal” qui a quand même réussi, parmi les trucs tellement moisis que même les gens de mon équipe avec à peu près 0 culture de dev ont calculé que ça marchait pas ou servait à rien…
Je passe sur le fait que les problématiques de nommage de variable, de responsabilité limitée des fonctions pour privilégier l’orchestration ou encore la notion de tests unitaires lui passait complètement au-dessus de la tête…
Normal vous comprenez, les “cadors” n’ont nul besoin de se conformer à de soi-disant bonnes pratiques suivies par la plèbe…
#65
A vrai dire, je ne sais pas si ça ne plante plus (enfin, je pense que c’est plus rare qu’un site Web plante suite à une entrée utilisateur), mais il doit toujours y avoir moyen de faire un peu buguer le système en rentrant des valeurs fantaisistes, pour peu que le site ait été codé à l’arrache sans certaines vérifications basiques.
#65.1
alors je vais préciser mes termes :
exemples :
si le site est fait un minimum correctement, en cas de saisie foireuse dans un formulaire, on reste sur le formulaire avec un message qui indique les données invalides (ça plante pas, mais gestion d’erreur correcte)
si le site est ultra rigide, on a un plantage car il attendait un “int” et a récupéré un “varchar” et il n’y a pas de gestion d’erreur, donc on se retrouve avec un crash, mais ça se voit de suite et on peut relativement facilement corriger (ça plante, mais c’est positif car ça saute aux yeux assez vite)
si le site est mal fait, et qu’on a le malheur d’avoir une adresse mail avec 25 caractères alors que le champ en base ne peut en contenir que 16, ben on va pouvoir passer l’étape d’inscription (et être logué immédiatement du coup), mais impossible de se loguer à nouveau le lendemain (ben oui il trouve pas l’adresse de 25 caractères dans la base) et impossible aussi de se faire envoyer un nouveau mot de passe (ou lien de réinitialisation valable 5 minutes …) et là pour débugguer ça va être sportif … (ça plante pas, mais ça masque les erreurs)
#66
Chacun son point de vue, moi son exemple je le trouve gentillet par rapport à certains truc que j’ai pus voir (et corriger)
Edit:
Bon vue que ta donner un exemple je vais donner la version hyper short:
Le client se plaignait que le chargement d’une page prenais plusieurs minutes de temps en temps (et parfois timeout), je suis venu, j’ai fait un “select count(*) > 0 from unetable” et la page mettais maintenant moins de 5 secondes à charger (j’avais pas spécialement le temps de refaire tous, donc c’était déjà pas mal)
#67
Et visiblement tu regarde jamais la consommation hardware du java, c’est simple, en utilisant d’autre langage j’ai systématiquement moins de consommation ram/CPU avec d’autre language que java.
#67.1
“Lenteur” et “conso ram/cpu” ne sont pas la même chose, voire ça peut être opposé.
Exemple, tu veux mesurer ce que tes serveurs sont capables d’encaisser en throughput, tu peux avoir dans certains langages une conso mémoire/cpu relativement faible mais un throughput pas terrible, et dans d’autres une plus grande conso et un meilleur throughput (donc meilleures perfs) et c’est d’ailleurs là où java s’en tire parfois bien.
Ce qui compte c’est d’utiliser efficacement les ressources à disposition. Les optimisations de la JVM aident beaucoup à ça.
Exemple ici des benchs ou des frameworks java sont massivement représentés dans le top 20 sur des centaines de frameworks testés, même s’ils n’ont pas les toutes premières places : https://www.techempower.com/benchmarks/#section=data-r20&hw=ph&test=query
#68
Il y a pire que Java : NodeJS
#69
Aussi, mais c’est bien du au fait que le code dégueu crée moins de problèmes en Java qu’en C. Donc ceux qui le produisent, s’ils se sont essayé au C++ avant, ils en sont rapidement sortis à force de ne pas arriver à faire quelque chose qui marche, c’est pour ça qu’ils sont sur Java (enfin étaient, maintenant y a Javascript et Python pour ça).
Attention on peut faire plein d’horreurs en C aussi, mais pas autant qu’en Java, et bien moins qu’en Javascript ou Python, car ça plantera beaucoup plus vite.
C’est tout à fait vrai, et je n’ai rien contre Java, ni contre aucun choix de langage d’ailleurs. Par contre il y en a certains où il est hors de question que je touche au moindre code que je n’ai pas écrit moi-même, mais Java n’en fait pas partie.
Rooooooohhhhh… Ca ne se fait pas de tirer sur l’ambulance !
#70
J’ai connu l’époque des micro-ordinateurs avec 64 k alors tu sais…
On s’en fout que le Java consomme plus que du C, on a des Go de RAM (même en config de base) qui ne coûtent rien (même en config de base), et déjà il y a 20 ans on arrivait à faire tourner du Java sur des serveurs pas spécialement costauds.
Comme déjà dit par d’autres, l’avantage du Java c’est que le langage est mûr, avec des gens expérimentés et un écosystème riche, et permet du développement plutôt de qualité.
#70.1
Je sais pas où tu bosses mais sans vouloir être méchant, je plains ta boîte s’ils sont tous avec le même état d’esprit.
J’ai connu éditeur logiciel, prestataire de service et grosse administration, et si j’avais osé sortir pareil(le)
ânerieparti pris au mieux on m’aurait ri au nez en m’expliquant qu’il était temps que j’apprenne à être pro, au pire on m’aurait foutu ailleurs.Bah qu’est-ce que ça doit être C alors… (après je me moque mais je comprends les raisons - et avantages - de la verbosité de Java hein
(après je me moque mais je comprends les raisons - et avantages - de la verbosité de Java hein  )
)
#71
Au contraire, Java a directement été conçu pour une exécution sécurisée, voire distante. Il intègre un SecurityManager, et divers mécanismes d’intégrité. Même s’il y a eu quelques erreurs initiales d’implémentation (corrigées depuis longtemps), pour autant que je sache ces mécanismes ne sont pas remis en cause.
La conception initiale est bonne, par contre il y a pour moi un soucis, par défaut le SecurityManager est désactivé ce qui empêche une défense en profondeur. D’autres langages comme C# ont fait le choix inverse, le SecurityManager est actif et le développeur doit explicitement le désactiver sur son poste (sauf exception le SecurityManager sera actif sur tous les autres éléments de la CI et en prod).
Et surtout la faille log4j ne vient pas de Java (un langage sûr) mais de la librairie log4j qui fait voler en éclat toute cette sécurité car elle passe en interprété.
Quel que soit le langage, si une librairie folle ajoute une interprétation spécifique dans un programme, ce programme voit sa sécurité réduite à celle de l’interpréteur ajouté.
D’ailleurs, les plus grandes failles du monde java venaient souvent de là : l’interpréteur de la balise Applet, l’interpréteur catastrophique du type application/x-java-jnlp-file (java native launcher protocol)…
Ensuite, diverses possibilités de Java comme le classloading distant peuvent augmenter la sévérité d’une faille quand le SecurityManager n’est pas activé.
Avec un SecurityManager actif donc sans code distant (ou code distant de sources de confiance prédéclarées) voire d’autres restrictions, Java est sûr.
#72
C’est l’inverse, métriques à l’appui. Enfin, ça dépend de ce que tu appelles des horreurs.
L’avantage du Java c’est aussi que c’est du code plus concis.
Je ne connais pas assez les performances de Node.js (ou bien la fiabilité des développements qu’on peut faire avec), qu’en dis-tu ? J’ai vu qu’il y avait une certaine mode sur ce système en tous cas. Je crois qu’un des avantages c’est la facilité de faire des trucs asynchrones, en particulier.
Je reste toujours étonné de voir des gens sortir avec certitude des affirmations péremptoires et fausses.
Je vais réduire ma crédibilité un bon coup en disant que je ne sais pas ce qu’est ce “SecurityManager”… . Alors peut-être que j’ai pratiqué sans le savoir mais ça ne me dit rien.
. Alors peut-être que j’ai pratiqué sans le savoir mais ça ne me dit rien.
#73
De mémoire c’est vers 2001 ou 2002, effectivement c’est vieux.
J’ai régulièrement vu des gens critiquer Eclipse, mais à part que ça met du temps à lancer (aucune importance pour moi vu que je le lance une fois par jour au max), j’ai trouvé cet environnement de développement génial pour du Java, faisant gagner beaucoup de temps. En tous cas j’ai rarement eu le sentiment d’être aussi efficace et d’avoir autant de contrôle qu’en développant en Java sous Eclipse (dans mes premières années de Java j’utilisais de simples éditeurs de texte).
#73.1
(pour le coup, je trolle, de toute façon, le meilleur IDE, c’est celui avec lequel le dév se sent le plus à l’aise - que ce soit Eclipse, VSCode ou Emacs, liste non exhaustive, j’en oublie des dizaines volontairement)
#74
Par horreur dans ce contexte j’entends des trucs pas rigoureux et mal pensés où c’est le langage qui rattrape tes bêtises. Si tu les faisais en C tu mangerais une segfault rapidement ou tu exploserais la mémoire, donc tu ne les fais pas ou tu changes de langage.
Si par horreur toi tu entends dépassement de tableaux et autres trucs gérés par des langages plus haut niveau, alors oui tu as raison. Mais je ne parlais pas de celles-ci, et même sur des langages qui t’évitent ce genre d’erreurs, elles doivent rester exceptionnelles (réellement la dernière ligne de défense) et pas devenir quelque chose auxquelles on ne fait plus gaffe parce que c’est bon, le langage gère…
Le JS, en plus d’être lent de base, est justement un de ces langages à l’opposé de ce que j’ai décrit au-dessus. Il n’y a aucune rigueur obligatoire, tu peux accumuler plein de bêtises, bien plus qu’en Java, ça le fera quand-même jusqu’au jour où ça t’explosera à la gueule, en crash pendant l’exécution, en performances déplorables ou alors en immense plat de spaghetti devenu incompréhensible.
Après il est tout à fait possible de faire des trucs bien pensés en JS, comme partout, c’est juste que c’est beaucoup moins indispensable que dans d’autres langages, donc c’est moins pratiqué.
#74.1
Je pense qu’aujourd’hui, que que soit le langage, on pourra trouver un tooling mature autour qui va palier aux faiblesses du compilo. Les analyses statiques de code, linters et autres sont devenus incontournables (valgrind, eslint, sonar…). Donc pour peu qu’on prenne le temps de bien les configurer, oui en effet on peut faire du “propre”. Même en JS 😁
(Ceci dit, le premier rempart restera toujours le compilo)
#74.2
Je pousse le HS, mais pourrais-tu me donner quelques exemples ? Ça m’intéresse, étant en plein apprentissage du Javascript et assez peu désireux de “profiter” de la liberté de faire n’importe quoi pour… Faire n’importe quoi justement
Voilà bien un problème auxquels les sites web ne sont pas confrontés tousse, tousse (anecdote de la vraie vie : j’ai en ce moment une session d’à peu près 900 onglets - oui j’ai un peu poussé mes recherches tous azimuts en mode “pile à traiter plus tard” rassurez vous ça va vite fondre - dont environ 60 onglets réellement chargés en mémoire. Et tout va bien. Si je “m’amusais” à repartir d’une session toute propre, mais que je décidais, mettons, d’ouvrir à la chaîne une trentaine de news d’un grand média d’information français dont je citerais pas le nom… En une heure Firefox crashe. Vlà le site bien foutu…)
#74.3
Enfait le “problème” avec javascript, c’est que tout est accessible, et que tout peut être modifié comme tu le souhaite, pas de vérification de type, n’importe quoi peut aller dans n’importe quel variable sans erreurs. (exemple de joyeuseté made in Javacsript : JsFuck )
Si tu veux éviter de faire n’importe quoi en javascript, quelques conseils (très simplifiées) :
Et de manière général, un front javascript devrais faire uniquement de l’affichage et de l’envoie d’information, jamais de calcul qui seront enregistrer. Genre le total d’une facture.
Après pour du front, je pense que dans une grande majorité des cas tu va tomber sur des framework type Anguar, React, Vue, Next ect, qui eux impose un certain paradigme et pallie à pas mal de soucis de l’ancien javascript avec JQuery en terme de “je fais n’importe quoi, tant que ça fonctionne”
#74.4
En résumé : écris du Javascript comme si tu faisais du (bon) PHP
Troll (?) mis à part ça me rassure je coche déjà à peu près toutes les cases (THIS m’a mis une misère de dingue jusqu’à ce que j’aille lire la doc, comprendrai jamais comment ils ont pu décider que c’était une bonne idée de faire un truc aussi variable selon le contexte mais y’avait sans doute de vraies raisons ) vu que de toute façon me suis pas encore penché sur l’asynchrone, j’en suis encore aux bases “apprends à faire des trucs kikoolol d’interface pour l’utilisateur”.
) vu que de toute façon me suis pas encore penché sur l’asynchrone, j’en suis encore aux bases “apprends à faire des trucs kikoolol d’interface pour l’utilisateur”.
Bien noté pour Typescript (de toute façon les variables non typées protéiformes j’ai horreur de ça xd raison pour laquelle je comprends tout à fait le “utilise toujours l’égalité de valeur et de type” ;)) mais j’attends d’avoir un socle matériel + OS à jour pour m’y mettre, pour l’instant je suis sur un PC de transition la flemme d’installer toute la stack.
Bref en gros, “sois toujours sûr de la nature et de la portée de tes variables et limite les autant que possible de manière stricte et strictement nécessaire”.
(Edit: pas encore osé cliquer sur ton lien, rien que le titre est vachement intimidant )
)
(Edit2: j’ai cliqué j’ai rien compris c’est normal que ça n’ait aucun sens pour moi ? xd)
#75
oui enfin dans mon cas, une consommation moindre des apps est un des argument de vente, dans les réponses que je voit ici beaucoup trop de dev “se foutent” de la consommation pour leur petit confort, et grace a des mentalité pareille on trouve des lecteur d’image qui mette des dizaine de seconde pour s’initialisé, se lancé et affiché l’image (sans compté la consommation de ram et le poids de l’app), la ou switch sur un language conçu et optimisé pour la lecture de fichier et le fonctionnement rapide double voir triple la vitesse de démarrage et d’affichage de la meme image.
Donc pour moi oui construire un logiciel avec un unique language est une hérésie complete, créer des modules dans le language le plus performant pour la fonction que le module doit remplir, permet de distingué un logiciel banal d’un excellent logiciel.
Et surtout faut que les dev arrête de réservé de l’espace ram pour tout et n’importe quoi.
A cause de ces dev on se retrouve avec beaucoup de programme qui consomme plus de ram que les anciens programme (si on exclu l’augmentation due au passage 32 -> 64bits, et la consommation de la partie graphique elle même) et qui ne font pas la moitié de ce que faisait les vieux logiciel avec 100 fois moins de ram.
#75.1
Multiplier les langages dans un produit c’est possible, mais ça a aussi un coût qu’il faut mettre en balance avec les gains : complexité accrue (sur l’interfaçage moins aisé/parfois bancal comparé à des modules au sein d’un même language, sur les tests automatisé avec environnements multiples à setup, sur le déploiement…), ça veut dire plus de stacks techniques à maîtriser, recrutement plus difficile (ou alors les équipes travaillent en silo, chacun sur ce qu’il maîtrise, ce qui crée d’autres genre de problèmes), même chose au runtime niveau opération : plus d’environnements à maîtriser et à maintenir.
Bref je dis pas du tout que c’est une mauvaise chose forcément, mais il faut pas voir ça comme LA solution, il y a des contreparties.
#75.2
Je pense pas me tromper en disant que vous parlez de deux monde différents.
En gros tu dit que pour des application lourde client Java c’est pas terrible. Et je suis plutôt d’accord. Mais quand on voit les applications lourde en electron on nuance.
Et d’un autre côté on te parle surtout de Java en tant que langage server (les plus concernés par la faille ici). Ou ajouter de la RAM est moins cher que de faire du C/C++.
En gros faire du « bien » en Java coute moins cher que de faire du « genial » en C/C++ sur server.
Je schématise énormément, j’ai déjà fait du trés bon en Java, avec SLA de 200ms pour le front, batch qui englouti 4M lignes (50 champs CSV) avec dedup/validation croisée/enregistrement en BDD en moins de 10min le tout sur 2 server pas fou (1Go de ram dans mes souvenirs). Et c’était pas un projet pour un petit backoffice de magasin mais un projet gouvernemental ouvert au public.
Quand on à l’argent pour investir dans les Dev, ça marche fort.
Les soucis de Java que tu remonte viennent souvent de la politique du « vite et qui marche ». Et effectivement on peut developper rapidement un code bancal en Java qui vas marcher sans soucis avec une consommation abusive. Ça coute moins cher, donc c’est « trop » souvent fait. Mais c’est pas le langage le soucis, mais les ressources encore une fois.
Faut bien imaginer que si le langage était a jeter, on aurais pas autant de grand nom cité dans la faille. Ils ont le budget de bien faire avec les langage de bas niveau, c’est bien que Java leur apporte un plus.
Je sais c’est moche et on pourrais presque croire que j’invente
Mais bon un projet donné à un CDS sans SLA (il faut juste que la recette passe) ça donne souvent ce genre de résultat
En un coup d’œil on pouvais voir que c’était 3dev différents qui l’avais fait, donc chacun a refait son appel BDD pour respecter son ticket…
Je pense que c’est même pas le pire que j’ai vu. Être contacté par la prod pour nous demander si c’est normal qu’un appel au SI provoque ~600 appels BDD ça met le reste en perspective
#76
Je vais peut être dire une connerie mais je trouve qu’il y’a des notions d’architecture réseaux qui sont rarement prise en compte dans les remédiations.
De mon point de vue si les serveurs impactés par la faille ont une liste blanche des adresses qu’il peuvent contacté sur Internet et si le type de trafic est limité à certains services (genre HTTP / HTTPS ) il y’a quand même moyen de considérer cette faille comme uniquement exploitable en interne. C’est déjà pas mal mais ça réduit l’urgence à patcher.
#76.1
Dans l’absolue oui. Un serveur front n’a pas vocation à initier des communications vers internet de lui-même (y compris les MAJ, priorité aux miroirs internes)
En terme d’archi, il y a toujours un FW front-end (autrement, log4jshell ou pas, ya déjà un soucis) qui doit filtrer les connexions sortantes.
Mais tout dépends comment les politiques ont été configurées et quels sont les comportements des FW.
#77
Tu viens de résumé la cause de à peu près tous les soucis des projets de dev en général…
Effectivement, “tu bluffes Martoni” !
#78
Euh, à un moment, si quand même…
Tu veux un exemple parlant ?
Dans mon ancien projet, mon fameux “dev senior expert Drupal” avait jugé bon, en dépit de mes alertes et projections argumentées / sourcées, de gérer les “références croisées” des contenus (A contient un lien vers B DONC B est lié à A) sous la forme de Node, soit le système de stockage de contenu “de base” de Drupal où chaque métadonnée (champ) a sa propre table (ne jugez pas, pour certains cas d’usage c’est justifié et utile, ça l’était juste pas ici ^^).
Donc 10 tables pour 9 champs + infos de base.
En soi pas forcément bien grave.
Le problème venait de la volumétrie : stock d’ancien site environ 400 000, et entre 1000 à 2000 nouvelles entrées chaque jour. Avec en sus plusieurs dizaines de requêtes en lecture/écriture par minute sur cet ensemble en récupérant bien évidemment l’intégralité des champs même si pas nécessaire, sinon c’est pas drôle.
Je vous laisse vous faire une idée du volume de requêtage, rapporté à sa fréquence.
Résultat, même avec une infra plus que surdimensionnée (64Go de RAM, 300s de timeout!!!, 16 coeurs) le site était inexploitable avec moins de 10 personnes actives au lieu de 300…
Dès lors que la feature a été recodée selon mes indications (soit juste selon le bon sens de base, je n’ai aucun mérite pour le coup xd) c’est à dire UNE table + requêtage limité au besoin + mise en cache du rendu (listings des références dans chaque contenu) on est passés à moins d’1% de charge (toujours le cas même après avoir divisé par 2 l’infra, je pense qu’ils pourraient encore diviser par deux sans aucun risque).
Et le pire ? C’était absolument pas compliqué de bien faire dès le départ, car Drupal fournit un “squelette” / “process” à suivre (la preuve, j’ai pu le prototyper tout seul en quelques jours) pour créer sa propre “Entité”, idem pour la mise en cache. Juste, le mec savait pas faire ou pire il avait juste la flemme parce que ça demandait de coder au lieu de juste faire du clickodrome.
J’ai une demi-douzaine d’autres choix complètement aberrants qui ont complètement pourri l’appli et ont requis réécriture quasi-complète (donc plusieurs mois/hommes de gaspillés pendant que le mec était facturé 1500e/jour).
Donc oui, on peut jamais établir de règle générale pour juger de la qualité / pertinence d’une appli puisque tout dépend des objectifs fonctionnels et techniques et des contraintes, mais il y a quand même des “patterns” qui ne trompent pas…
@Ramaloke amen compagnon INpactien, nous avions la chance dans mon équipe d’avoir un OPS ex-DBA, et il nous a gentiment, mais fermement, enseigné les bonnes pratiques de base du requêtage, dont la règle n°1 : le moins de requêtes possibles. :)
#78.1
le moins de requêtes possibles c’est une chose, mais des fois vaut mieux faire 4 requêtes très ciblées qu’une seule avec des jointures complexes qui vont devoir jongler avec une volumétrie de lignes ahurissante (récemment je me suis retrouvé à refaire des appels, la quantité de jointures était conséquente (entre 5 (ça pourrait passer) et 15 de mémoire, selon les “if” dans lesquels on passait) sur des tables avec quelques centaines de milliers de lignes (peut-être même des millions pour certaines), d’une le code était pas vraiment lisible du coup, et de 2 en éclatant les requêtes chaque appel ne se concentrait que sur un nombre limité de lignes, malheureusement j’ai pas fait de bench pour comparer les temps des 2 solutions, je constate juste que ma version prend un temps ridicule :p )
#79
Tout a fait je me souviens d’une fonctionnalité qui faisait de l’agrégation. Quand on avait de la chance on avait un résultat au bout de 15 min sinon timeout. Les gars avaient fait un union de 2 requêtes avec 6 ou 9 group by conditionels. J’ai éclaté la requête en 4 et tous les comptages en Java. résultat affichage en 15s…
#80
J’ai eu la chance de commencer mon premier boulot en ESN dans une équipe de dev où exerçait un DBA expérimenté, qui m’a formé à SQL (je ne connaissais pas) et aux bonnes pratiques. Par la suite j’ai constaté que clairement certains (ailleurs) n’étaient pas formés, et pas conscient des choses inefficaces qu’ils faisaient (le truc de base du genre : faire un “select *” sans clause “where” et filtrer dans le code…).
Il y a des choses qui font des miracles, comme certains index, ainsi que le “connection pooling” (on ouvre une ou plusieurs connexions une fois pour toutes au démarrage du programme et ensuite on n’a plus qu’à chopper une connexion pour faire une requête et ça économise toutes les négociations). On apprend aussi à faire éventuellement des “select count(*)” avant de faire le vrai select, quand ça économise du temps et de la mémoire.
Et les bases de données où on peut utiliser le mot clé “LIMIT” pour faire du “‘paging” c’est magique (ou avec des curseurs mais faut connaître aussi).
Oui, et on a fait des progrès considérable dans les latences en passant au gigabit. Me souviens de ce qu’on disait quand on déportait la base de données sur une autre machine, en terme de perte de performance.
Il faut savoir qu’à une époque tout était sur le même serveur et ça marchait très bien, Apache et la base de données. Maintenant on sépare systématiquement, depuis longtemps.
#81
Tu m’as mal compris, il ne s’agit pas de gâcher de la RAM en codant comme un cochon. J’ai toujours eu à coeur l’optimisation à tous niveaux. Mais que Java consomme plus de mémoire que du C, c’est depuis le début et ça n’est pas vraiment un problème, tellement ça apporte de qualité de développement et de fiabilité, de ne pas à avoir à gérer les “free()” (et pas que).
Ben oui en C c’est difficile de bien coder, il faut de l’expérience, quelques années à mon avis. Quand j’ai commencé à coder j’avais déjà fait du C quand j’étais ado et étudiant, mais en passant à du vrai boulot, j’ai nettement amélioré mon niveau. En C on peut faire du code assez optimisé, mais il faut du temps pour éviter diverses erreurs ou risques. Et je peux dire que je produisais le code le plus fiable de toute mon équipe (au prix sans doute d’un développement un peu plus lent), car lors de la phase de maintenance je crois qu’on n’a jamais dû toucher à mon code (on était 8 dev sur le projet) pour des raisons de bug..
Java n’est pas verbeux, sauf si on parle des déclarations d’interface ou genre, mais ça tu le fais une fois et après tu copies-colles et tu t’en fous, tu ne fais même plus attention.
Justement, quand on a fait beaucoup de C, en Java le code est plus concis et lisible/compréhensible.
#82
900 onglets sur un navigateur ?
T’as combien de Go de RAM sur ton ordi ?
J’ouvre pas mal d’onglets à l’occasion, mais déjà 50 c’est beaucoup.
Par ailleurs je me demande si tu ne confonds pas la consommation mémoire côté serveur, et celle côté navigateur (pas forcément lié) quand il y a des DOM bien lourds et du JS en pagaille.
Ah OK donc t’as pas vraiment 900 onglets d’ouverts. Je me disais aussi…
Au bout d’un moment, ça finit par tout bouffer et faut quitter le navigateur et le rouvrir.
#83
Une BDD est faite pour traiter les jointures, ça dépend comment est conçue la base de prod et ses relations, mais j’ai déjà fait des requêtes avec des jointures sur plusieurs tables, et quand c’est correctement écrit (pas n’importe comment), c’est tout à fait rapide (et je parle d’un époque en 1997 sur du Ingres). Et heureusement sinon à quoi serviraient les BDD et le côté relationnel.
C’est plutôt que la requête est mal écrite ; et j’en ai vues, que j’ai réécrites et c’est fou le gain qu’on peut avoir (genre 30 s -> 0,1 s) en utilisant quelques bonnes pratiques, comme les critères les plus restrictifs en premier. Et la base n’était pas petite.
Les jointures sont faites pour être utilisées, et c’est aussi ça qui distingue un bon moteur de BDD. On peut aussi vérifier avec le “explain” le plan de “requêtage” de la base.
#83.1
alors oui, les jointures bien utilisées ça peut etre très bien
mais typiquement quand y’a 4 jointures sur la même table avec des critères différents, c’est pas génial, surtout quand ça oblige à faire des “group by” pour éliminer les doublons (ben oui, si y’a 3 lignes de la table “enfant” car 3 “left join” tu te retrouve avec 3 lignes “parent” donc faut les “compacter” en une seule (bien entendu chaque jointure à fait appel au même champ mais est nommé différemment dans le select, donc avec le “group by” on n’a plus qu’une seule ligne avec 3 champs différents provenant chacun d’une jointure sur la même table)
alors qu’en éclatant en 2 requêtes, une sur la table parent, et une seule sur la table enfant avec le critère commun, et des “ou” pour les critères différents, la base n’a plus à galérer avec une quantité faramineuse de lignes
et le traitement des données pour agréger correctement les deux résultat est au final super simple et donc rapide
alors oui, j’ai du mal à valider le fait de faire plusieurs jointures sur la même table et les soucis que ça engendre (je peux accepter que ça puisse se défendre, mais dans la situation en question j’y crois pas une seconde), mais cette table est peuplée par un autre prestataire et c’est pas gagné pour faire changer le process, y’aurait plein d’autres choses à faire pour améliorer la base en question, et j’aimerai beaucoup pouvoir tout mettre à plat et faire un truc largement plus propre maintenant (y’a eu plein d’évolutions au fur et à mesure qui se sont empilées et ont tenté de faire avec l’existant) mais c’est pas à l’ordre du jour :‘( …
#83.2
Là, ça ressemble clairement à un l’avais design des requêtes, ou plutôt peut-être à un système qui s’est construit petit à petit (tiens, j’ai juste un “if” à ajouter..
ah mais oui mais ça me renvoie 2 résultats, bon, “group by” et on n’en parle plus).
Dans une situation de ce type, c’est clair que si tu trouves le budget, c’est utile de se reposer et de tout reprendre. À condition que le sujet soit mené par quelqu’un qui comprend ce qu’il fait, donc dans l’idéal un dev avec de bonnes compétences en base de données - j’ai eu la chance de bosser avec une personne comme ça, c’est très formateur !
J’ai eu l’occasion de reprendre il y a 15 ans du code Java qui avait été codé par une personne habituée au C… Ça se voyait tout de suite, d’autant plus que c’était du code migré du C. Littéralement
#84
Bah Firefox doit quand même charger la session ! Mais il fait ça en à peine 3 secondes c’est assez impressionnant (surtout que mon vieux pc a encore un hdd traditionnel). ET j’ai que 8Go de RAM (qui doit d’ailleurs être de la DDR3 moyenne gamme vu qu’il date de 2012). ET j’ai quand même les services classiques de taff web en arrière-plan en sus (apache, sql).
Je peux garantir que Chrome ne démarre même pas dans ces conditions le pov’chou (testé et désapprouvé, il meurt à même pas 100 onglets, au temps pour sa réputation)…
Cela dit, une fois à mon ancien taff, à une période où j’étais dans le même type de recherches tous azimuts avec genre 10 sujets en parallèle, je me suis laissé aller à 999 onglets pour le délire. Puis quitter. Puis relancer. Puis… “Actualiser tous les onglets”.
Mon ordi a étonnamment tenu la charge pendant 1mn, mais j’ai coupé moi-même parce que j’avais littéralement fait sauter l’internet de toute la boîte (faut dire on était 20 sur une connexion “de particulier” ADSL 2+ donc y’avait pas un débit de fou à la base) et j’ai commencé à entendre tout le monde râler de ouf en mode “putain y’a encore des gens qui mattent du Youtube en plus de la réunion Skype” (in petto: “non non, c’est juste moi qui ai trouvé un moyen infaillible et instantané de troller 100% de mes collègues )
)
Et oui je parlais bien de la consommation côté client avec des scripts moisis dans tous les sens, mais ça rejoint l’idée du “projet codé avec les pieds” (voire pire, site malveillant conçu exprès pour utiliser ta machine). Phénomène qui de mon point de vue de simple utilisateur s’est largement aggravé depuis plusieurs années, je soupçonne que c’est au moins en partie à cause de l’usage toujours croissant de frameworks prêts à l’emploi même quand c’est largement surpuissant pour le fonctionnel requis + l’excuse de “on s’en fout les machines sont de plus en plus puissantes” (bah ouais connard, clairement ton site est le seul que les gens vont voir… Je veux dire, mon cas est clairement à part donc je le prends pas, mais même mon père qui consulte au max 10 onglets à la fois a parfois des ralentissements nets selon les sites consultés, c’est quand même inacceptable).