

Après être passé des serveurs physiques aux machines virtuelles, les développeurs et administrateurs de services ont trouvé un nouvel allié dans le déploiement de « conteneurs », où Docker est roi. Si le sujet parait parfois compliqué, il peut être simple à expliquer. Voici quelques exemples pour tout comprendre.
Aux débuts du développement informatique moderne, à l'ère du PC personnel et de l'hébergement web, les choses étaient « simples ». Les utilisateurs disposaient de postes clients sur lesquels des applications étaient lancées, pouvant interagir avec des serveurs, des machines physiques distantes présentes sur le réseau local ou Internet.
Du serveur dédié à l'instance jetable
Puis vint la mutualisation et les offres d'hébergement accessibles à tous. À l'opposé d'un serveur dédié, loué par un seul et même client, on stocke et donne accès à des dizaines voire des centaines de sites depuis un unique serveur. Cela pouvait prendre la forme de comptes différents pour se connecter via FTP et mettre en ligne ses fichiers, ainsi que d'une configuration multi-sites du serveur web. Une approche où l'isolation d'un client à l'autre était faible.
Avec la montée en puissance des machines, des besoins, d'une volonté de renforcement de la sécurité, la virtualisation est arrivée au début des années 2000. Elle permettait en effet de « découper » un serveur en plusieurs machines virtuelles (VM) pouvant être louées individuellement. On parle alors de serveur privé virtuel (VPS).
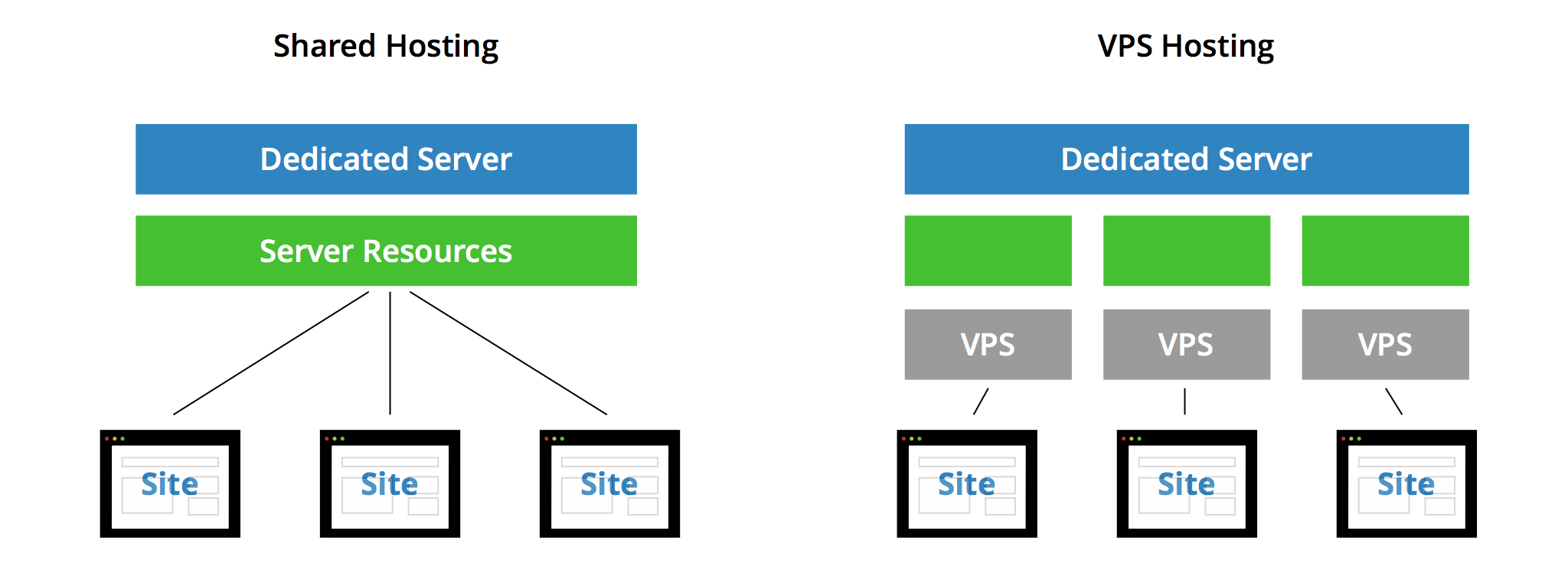
20 ans plus tard, nous sommes à l'heure du « Cloud » et de ses instances qui sont autant de VM que l'on peut créer et détruire en quelques secondes seulement. Au point qu'un système et ses dépendances peuvent être vus comme une simple commodité, servant aux besoins d'une application ou d'un service de manière temporaire.
Docker nous a fait entrer dans l'ère du conteneur
C'est de ce constat qu'est né Docker il y a une dizaine d'années. Créé par Solomon Hykes pour le français dotCloud (devenu Docker Inc en 2013, scindé en 2019), l'outil est rapidement devenu une référence dans le domaine de la conteneurisation (d'où son nom). Il permet en effet de lancer un système tiers de manière isolée, y déployer différents services et fichiers, y effectuer des opérations et tout supprimer lorsque ce n'est plus nécessaire.
Une solution parfois perçue comme complexe, mais qui ne l'est en réalité pas vraiment et peut changer en profondeur vos méthodes de travail. Pour vous le faire comprendre, nous avons décidé de vous montrer ce à quoi pouvait servir Docker par quelques exemples pratiques, simples à mettre en œuvre.
Notre dossier sur les conteneurs :
- Docker et la conteneurisation par l'exemple
- Comment déployer un site statique à la demande via Docker (CaaS) et votre propre image
- Linux Containers (LXC) dans Proxmox VE 7.0 : installez simplement des distributions et services
Nous ne reviendrons pas ici en détails sur ce qu'est un conteneur et sa différence avec la virtualisation « classique », que nous avons déjà évoquée lorsque nous avons traité des Linux Containers (LXC) dans Proxmox VE 7.0. Sachez seulement que la différence fondamentale est qu'un conteneur utilise le système hôte comme base pour son système invité. Il n'est ainsi pas possible de lancer un conteneur Windows sous Linux et inversement, à moins d'utiliser une solution de virtualisation intermédiaire, comme le sous-système Linux de Windows 10/11 (WSL).
L'avantage, c'est que les images et ressources utilisées sont bien plus légères, tout du moins en théorie (nous y reviendrons). Lors de nos essais avec LXC nous avions évoqué le cas d'une distribution pensée pour une utilisation dans des conteneurs, Alpine Linux, dont le template n'utilisait que 2,5 Mo. 8,8 Mo une fois le système déployé.

Conteneurs et orchestration, pour quoi faire ?
L'usage courant est ainsi le plus souvent de faire fonctionner des conteneurs de différentes distributions Linux comme invités depuis un système hôte également sous Linux. On peut ainsi y déployer une multitude de services exposés ou non sur le réseau via différents ports sans avoir à changer quoi que ce soit à l'OS principal.
Le tout est organisé via des mécaniques et fichiers répondant à des règles de déploiement, de manière à fonctionner de manière reproductible sur différents systèmes. C'est donc un avantage de poids à l'heure du multi-cloud. D'autant que des systèmes d'orchestration peuvent être mis en œuvre pour déployer différentes instances et les faire travailler ensemble, les reproduire par dizaines, centaines ou milliers pour assurer une forte disponibilité.
Des besoins qui sont au cœur du cahier des charges de services qui comptent de nombreux clients. Cela permet aussi d'adapter le nombre de serveurs et d'instances selon le besoin : tout peut être éteint ou presque lorsque les utilisateurs ne sont pas là hors des heures de bureau par exemple, ou au contraire on peut s'adapter automatiquement à des pics de charge pour éviter de voir son site tomber lorsqu'il « passe à la TV ».
C'est d'ailleurs sur ces promesses que certains se sont spécialisés dans le Platform-as-a-Service (PaaS), proposant aux entreprises de se focaliser sur le développement de leurs applications et services avec une facilité de déploiement, peu d'entretien (les serveurs/instances n'étant pas à gérer) et une adaptation à toute situation.
Un sujet sur lequel nous aurons l'occasion de revenir dans de prochains articles.
Une multitude de strates et d'outils
La première étape est bien entendu d'installer Docker, qui est en réalité un ensemble d'outils (open source), dont certains ne sont plus gérés directement par l'entreprise Docker Inc. C'est notamment le cas de son runtime containerd, libéré en 2017. Il s'agit de la brique gérant concrètement les conteneurs et qui fait le lien avec runc.

Comme on peut le voir sur l'image ci-dessus, Docker permet de décrire des images et de les construire (build) avec différents composants (système, stockage, réseau, etc.), de les déployer sous la forme de conteneurs, de les gérer et de les mettre à disposition via son registre Docker Hub. Mais comme le rappelait Kelsey Hightower (Google Cloud) l'année dernière, ce n'est qu'une suite d'outils parmi d'autres disponibles sur le marché.
Elle a néanmoins l'avantage d'être clé en main et bien documentée, avec un écosystème large et complet. D'où notre choix de l'utiliser pour commencer notre exploration. Nous l'utiliserons ici à travers un Raspberry Pi 4 doté de 4 Go de mémoire, mais vous pouvez faire de même avec un serveur physique ou virtuel.
Installer Docker
Docker peut être utilisé sous Linux mais aussi macOS ou Windows via sa version Desktop. Notez que dans le cas des Mac M1, la conversion de l'ensemble des binaires à ARM64 n'est pas encore finalisée. Vous pouvez d'ailleurs utiliser Lima (qui se base sur containerd) ou Multipass pour y déployer des conteneurs/VM simplement.
Les différents guides d'installation sont disponibles ici. Dans notre cas, nous avons opté pour Raspberry Pi OS qui nécessite de suivre une procédure spécifique (non recommandée pour un environnement de production) :
curl -fsSL https://get.docker.com -o get-docker.shsudo sh get-docker.sh
Pour d'autres distributions comme CentOS, Debian, Fedora, RHEL, SLES ou Ubuntu, vous pouvez ajouter le dépôt de la Community Edition de Docker afin de l'installer et procéder à des mises à jour ou télécharger un paquet adapté. Des binaires sont également disponibles pour une installation et un lancement manuels.
Une fois installé, Docker doit être utilisé avec les droits administrateurs (root). Mais si vous le désirez, vous pouvez aussi permettre à certains utilisateurs de le lancer directement. La procédure à suivre est décrite ici.
Vérifier que tout fonctionne, lancement d'une première image
Pour vérifier que Docker est installé et fonctionnel, commencez par le lancer pour afficher sa version :
sudo docker version
Vous pouvez également obtenir des informations sur les conteneurs, images et ses différents éléments :
sudo docker info
Mais aussi afficher l'aide, de manière générale ou pour une commande en particulier :
docker --help
docker image --help
Passage obligé de tout tutoriel Docker, le lancement de l'image hello-world :
$ docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
9b157615502d: Pull complete
Digest: sha256:cc15c5b292d8525effc0f89cb299f1804f3a725c8d05e158653a563f15e4f685
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
[...]
Comme on peut le voir dans le résultat reproduit ci-dessus, cette simple commande mène à une succession d'étapes. Tout d'abord, Docker vérifie si l'image demandée (hello-world) est présente localement. Si tel est le cas elle est directement lancée. Sinon, elle est récupérée (pull) depuis le registre Docker Hub, vérifiée et lancée.
Ainsi, on aurait aussi pu procéder par étapes et la télécharger pour lancer un conteneur nouvellement créé :
sudo docker pull hello-world
sudo docker create --name docker-hello hello-world
sudo docker start --attach docker-hello
Une fois le résultat affiché par le conteneur, son exécution est terminée. On peut le vérifier :
sudo docker ps
Cette commande montre les conteneurs en cours d'exécution et détaille leur identifiant, nom, image, commande, statut, etc. Si tout s'est déroulé comme prévu et que vous n'aviez lancé aucun autre conteneur, elle renvoie un tableau vide. Pour afficher l'ensemble des conteneurs, même ceux arrêtés tapez :
$ sudo docker ps --all
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
98cf5ed7c886 hello-world "/hello" 10 minutes ago Exited (0) reverent_beaver
L'image téléchargée par Docker est bien présente, prête à être lancée :
$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest 1ec996c686eb 7 weeks ago 4.85kB
Si vous n'en avez plus besoin, vous pouvez la supprimer, en commençant par son conteneur :
sudo docker rm reverent_beaver
sudo docker rmi hello-world
Utiliser la commande prune permet de supprimer tous les conteneurs stoppés et images inutilisées :
sudo docker container prune
sudo docker image prune
Pour faire le ménage et supprimer tous les conteneurs et images, utilisez l'affichage en liste « silencieuse » (-q) :
sudo docker rm $(sudo docker ps -a -q)
sudo docker rmi $(sudo docker images -a -q)
Notez que chaque conteneur peut être créé (create), démarré (start), stoppé (stop), tué (kill), renommé (rename) en utilisant son identifiant ou son nom. Vous pouvez également copier des fichiers depuis et vers un conteneur (cp), vérifier des changements effectués à ses fichiers (diff), les exporter sous la forme d'une archive (export).
Exécution de commande et tag : le cas Python
Pour chaque image, il peut exister différentes déclinaisons, présentées comme des « tags ». Par défaut, c'est la dernière version en date de l'image de base qui est téléchargée (latest). Mais vous pouvez en choisir une autre.
Cela peut être intéressant lorsque vous avez besoin d'une branche spécifique d'une distribution Linux ou d'une application. Prenons l'exemple de Python, actuellement en version 3.10. Mais la 3.11 qui est actuellement en phase de test peut également être utilisée. Docker permet de le faire sans modifier votre installation.
sudo docker pull python:3.11-rc-alpine
Ici, nous récupérons une image basée sur Alpine Linux et donc relativement compacte, où Python 3.11 est installé. Comment savoir qu'elle existe ? Elle est référencée dans la description de l'image de Python sur le Docker Hub. On peut désormais l'utiliser pour créer et lancer un conteneur par exemple pour afficher la version de Python :
$ sudo docker run --rm python:3.11-rc-alpine python --version
Python 3.11.0a2
Notez que nous utilisons ici le flag --rm qui permet de supprimer le conteneur dès qu'il a fini d'être exécuté. Cela évite de créer autant de conteneurs que nous exécutons de run ou de lancer un prune régulièrement.
On peut également tester la nouvelle commande math.cbrt() qui calcule la racine cubique d'un nombre :
$ sudo docker run python:3.11-rc-alpine python -c "import math; print(math.cbrt(74088));"
42.0
Accès au terminal d'un conteneur
Vous pouvez lancer le conteneur en mode interactif avec un accès terminal :
sudo docker run --rm -it python:3.11-rc-alpine
La commande par défaut de cette image consistant à lancer Python, vous arriverez directement dans son interpréteur. Vous pouvez là aussi préciser la commande de votre choix, par exemple pour accéder à un shell :
sudo docker run --rm -it python:3.11-rc-alpine /bin/sh
Cette méthode est utile dans une phase de debug, permettant de vérifier le contenu et l'emplacement des fichiers du conteneur, tester des commandes, etc. Ou simplement pour accéder au shell d'une distribution Linux tierce.
Par exemple si vous voulez vous essayer à la dernière version d'Ubuntu :
sudo docker run --rm -it ubuntu:21.10 /bin/bash
Notez que les images pour conteneurs des distributions sont en général allégées et ne contiennent pas autant d'applications préinstallées que les images classiques, pour serveur ou PC de bureau.
Dockerfile : construisez simplement votre première image
Télécharger des images clé en main, c'est une chose. Mais en construire qui correspondent à vos besoins en est une autre. Cela vous aidera aussi à comprendre comment celles que vous utilisez sont construites. Elles reposent toutes sur un même fichier décrivant leur fonctionnement, le Dockerfile. Sa documentation est disponible ici.
Il s'agit d'une simple suite d'instructions, qui sont traitées de manière séquentielles et serviront à construire les couches (layers) constituant votre image. Cette phase (build) est exécutée avec une mécanique de cache : lorsqu'une couche est modifiée, toutes les instructions correspondantes et les suivantes sont reconstituées.
Ainsi, il est en général recommandé de placer en premier les instructions qui évoluent peu, suivies de celles qui peuvent changer plus ou moins régulièrement, de manière ordonnée. Cela vous aidera à réduire les temps de build, ce qui peut avoir un impact lorsque vous aurez à passer par des outils de CI/CD tiers facturés au temps d'usage.
Pour cet exemple, nous allons créer un fichier nommé dockerfile :
nano dockerfile
Qui contient le contenu suivant :
# On se base sur la dernière version d'Ubuntu
FROM ubuntu:latest
# On met à jour les dépôts puis les paquets
# Les commandes RUN sont exécutées à la construction de l'image
# On utilise l'argument -y pour éviter les requêtes à l'utilisateur (root)
RUN apt update && apt full-upgrade -y && apt autoremove -y
# On installe wget et OpenSSL
RUN apt install -y wget openssl
# On lance un benchmark OpenSSL
# On utilise ici l'instruction CMD qui sera lancée à l'exécution du conteneur
# Une image ne doit contenir qu'une seule instruction CMD
CMD wget -qO- https://gist.githubusercontent.com/davlgd/d6902bae9bd6bfdd6464b437e15425ad/raw/e87a122bccd378bb0fc44a6e1e579c99040dac24/openssl.sh | bash
On l'enregistre (CTRL+X) puis on demande la création de l'image, nommée opensslbench, depuis le dossier courant :
sudo docker build -t opensslbench:latest .
On peut alors lancer l'image :
$ sudo docker run --rm opensslbench:latest
1T : 33.1 s/s | 2462.4 v/s
nT : 131.5 s/s | 9812.7 v/s
Pensez à prendre garde à différents aspects pour éviter des images posant problème et trop lourdes. Privilégiez des images de base officielles et régulièrement mises à jour (avec les correctifs de sécurité et optez pour une approche la plus minimaliste possible : n'installez que ce qui est nécessaire, avec une image de base légère si possible.
C'est pour cela que l'on recommande des distributions comme Alpine dans les conteneurs, ce qui permet d'éviter de construire des images inutilement lourdes, car on se retrouve parfois avec de véritables monstres de plusieurs centaines de Mo ou de plusieurs Go à récupérer avant de lancer la moindre opération.
Exposer un port, accès aux dossiers de l'hôte
Imaginons maintenant que nous voulions inscrire ce résultat dans un fichier qui sera diffusé sur le réseau via un serveur web, mais qui restera accessible sur la machine hôte à la fin du conteneur. Pour cela, nous allons changer d'image initiale pour celle proposée par nginx avec le tag alpine afin de disposer d'une image compacte :
# On se base sur la dernière version d'alpine avec nginx
FROM nginx:alpine
# On se place dans un dossier de travail
WORKDIR /home/
# On met à jour les dépôts puis les paquets
RUN apk update && apk upgrade
# On installe OpenSSL
RUN apk add openssl
# On expose le port 80 du conteneur
EXPOSE 80
# On récupère le script de test et on le rend exécutable
ADD https://gist.githubusercontent.com/davlgd/d6902bae9bd6bfdd6464b437e15425ad/raw/e87a122bccd378bb0fc44a6e1e579c99040dac24/openssl.sh /home/
RUN chmod +x openssl.sh
# On lance un benchmark OpenSSL et on lance le serveur web
CMD ./openssl.sh > /usr/share/nginx/html/results.txt && nginx -g "daemon off;"
On relance la création de l'image :
sudo docker build -t opensslbench:latest .
Pour que le fichier créé reste disponible après l'exécution du conteneur, il suffit de lui attribuer un dossier de la machine hôte. Nous allons ainsi le monter comme /usr/share/nginx/html/ où sont les fichiers distribués par nginx. On attribue également le port 8080 de la machine hôte au port 80 du conteneur :
mkdir results
sudo docker run --rm -v $PWD/results/:/usr/share/nginx/html/ -p 8080:80 opensslbench:latest
Pour stopper l'exécution, tapez les touches CTRL+C. Dans le dossier /results/ de l'hôte, results.txt sera présent.
Ajout de fichiers locaux, conteneur détaché
Notez que l'on peut opter pour une approche plus locale en ajoutant des fichiers à l'image afin qu'ils soient exploitables depuis le conteneur. Vous pouvez donc y créer votre propre script bench.sh :
sudo nano bench.sh
On lui ajoute le contenu suivant :
echo Tests en cours...
openssl speed rsa4096 2>/dev/null | grep 'rsa 4096 bits' | awk '{print "1T : "$6" s/s | "$7" v/s"}' > /usr/share/nginx/html/results.txt
openssl speed --multi $(nproc) rsa4096 2>/dev/null | grep 'rsa 4096 bits' | awk '{print "nT : "$6" s/s | "$7" v/s"}' >> /usr/share/nginx/html/results.txt
echo Tests terminés ✅
echo Lancement du serveur NGINX ✅
nginx -g "daemon off;"
On peut alors remplacer le contenu du dockerfile par le suivant :
# On se base sur la dernière version d'alpine avec nginx
FROM nginx:alpine
# On se place dans un dossier de travail
WORKDIR /home/
# On met à jour les dépôts puis les paquets
RUN apk update && apk upgrade
# On installe OpenSSL
RUN apk add openssl
# On expose le port 80 du conteneur
EXPOSE 80
# On ajoute le script et on le rend exécutable
COPY bench.sh /home/
RUN chmod +x bench.sh
# On lance le script
CMD ./bench.sh
On met à jour l'image et on lance le conteneur de manière détachée :
sudo docker build -t opensslbench:latest .
sudo docker run --rm -d -v $PWD/results/:/usr/share/nginx/html/ -p 8080:80 opensslbench:latest
Il est exécuté comme une tâche de fond, son identifiant sera affiché.
Pour demander à ce que le conteneur soit relancé automatiquement on utilise le flag --restart :
sudo docker update --restart unless-stopped nom_ou_id_du_conteneur
On peut suivre ses logs puis l'arrêter :
sudo docker logs nom_ou_id_du_conteneur
sudo docker stop nom_ou_id_du_conteneur
Pour afficher des statistiques de l'ensemble de vos conteneurs :
sudo docker stats
Pour revenir à un mode attaché :
sudo docker attach nom_ou_id_du_conteneur
Dans la suite de ce dossier, nous évoquerons Docker Compose et différentes méthodes de déploiement.



























Commentaires (33)
#1
J’ai découvert Docker en passant à l’auto-hébergement pour Nextcloud et Bitwarden aux côtés d’autres services. C’est magique ! Encore plus avec Portainer d’ailleurs.
#2
Je n’y connais pas grand chose en virtualisation ou conteneurisation, et je me posais un question. J’ai besoin d’utiliser professionellement un vieux soft proprio qui n’est supporté que sur une vieille version d’Ubuntu. J’ai essayé avec KVM, ça marche mais les perfs sont trop en deça du raisonnable. Un Docker ou “truc du genre” pourrait m’aider ou pas du tout ?
#2.1
Potentiellement, regarde sur dockerhub s’il y a la version d’ubuntu qui t’intéresses.
Normalement avec un container, tu vas gagner en perf niveau I/O.
Par contre si ton soft a une GUI “lourde”, ça doit être un poil plus compliqué, genre faire de l’export x11 ou un truc dans le genre
#2.2
Je vais regarder merci. La GUI est assez lourde en effet, je vais essayer.
#2.3
Regarde du côté de singularity
Ta un linux pratique qui traite du sujet
https://boutique.ed-diamond.com/en-kiosque/1604-linux-pratique-128.html
#3
Heeey, arrêtez de donner tous nos secrets de devops!
#4
Si avec KVM les perfs sont pas incroyables, j’essaierais d’abord de bien choisir les drivers utilisés pour le réseau et pour les disques. Si ça marche toujours pas, Docker ou LXC pourraient peut-être t’aider. Mais après, ça dépend aussi pas mal de ton appli. Convertir une appli en image docker c’est pas forcément instantané et faut en voir tous les impacts par exemple le logging, les dossiers où sont créés des fichiers, si t’as plusieurs process pour une seule appli, voire besoin d’orchestration.
#5
Pas du tout… Docker n’est pas du tout fait pour ça.
Par contre, c’est étonnant que tu aies des probs de perfs avec KVM. Normalement, une VM tourne avec des perfs quasi natives (sauf cas très particuliers).
As-tu bien activé les fonctions de Virtualisation dans le BIOS de la machine ? Sans ça, KVM ne fait pas de la virtualisation mais de l’émulation et les perfs sont catastrophiques…
#6
Autour de Docker, on a deux outils très pratique :
#7
Pour un dev, Docker c’est la vie.
Plus jamais je me fais chier à installer et paramétrer un environnement complet sur une machine. Et depuis que j’ai changé de pc je n’ai même pas réinstallé php apache et tout le toutim… à part dans un conteneur bien sur !
#7.1
Personnellement ma préférence va désormais vers
podman. Dispo en natif sur la famille Red Hat, son principal intérêt est qu’il est daemonless.De ce fait, un utilisateur non privilégié peut démarrer un container sans aucun prérequis supplémentaire (en dehors d’un
:Zpour le mapping de volumes pour SELinux). Et comme il a été conçu pour être entièrement compatible avec la CLI de Docker, il suffit de faire un aliasdocker=podman.C’est clairement l’un des grands intérêts de containers, la reproductibilité des environnements de travail.
#8
Article très utile, mais l’explication de
runpeut prêter à confusion. Surtout quandstartetcreatesont évoqués par la suite sans être expliqués.Contrairement à ce qui est dit dans l’article, la commande ). C’est un raccourci de :
). C’est un raccourci de :
runn’est pas un raccourci pourpulletrun(récursionpull: Si elle n’est pas déjà présente localement, récupération de l’imagecreate: S’il n’existe pas déjà, création d’un nouveau conteneur pour cette imagestart: Démarrage du conteneurrunn’est donc bien qu’un raccourci. Ce n’est en rien une commande essentielle. Beaucoup d’articles s’appuient systématiquement surrun. C’est très pratique pour la démohello-worldmais, pas au quotidien, ni pour la compréhension des bases essentielles. Si l’on ne montre que de ça, alors ça embrouille plus qu’autre chose.#8.1
Effectivement, my bad, c’est plus clair en détaillant ainsi tu as raison
#9
Ne jamais, jamais faire ça. Toujours vérifier le script entre les deux, au minimum.
Sinon David, cet article a comme un gout de IH…
Je me demande s’il serait pas opportun de réfléchir à faire de IH le côté “pro” et NXI le côté généraliste, malgré leurs noms.
Juste une idée :)
#9.1
Je précise que c’est une procédure spécifique à Raspberry Pi OS à ne pas faire en production. A faire : lire avant de commenter
#10
Il faut aussi préciser l’option –userns=keep-id dans podman pour maintenir les id utilisateur , c’est utile pour certains usages .
Il faut par contre faire attention que les données - TOUTE les données - soient stockées à l’extérieur du container - soit via le réseau soit via les volumes, sinon pertes de données assurés à la moindre mise à jour. Ca m’est arrivé :-/
#11
+pour podman
Je ne parierai pas fort sur l’avenir de “Docker” (le client et la marque) qui sont plutôt en “quête de marché” depuis la libération du runtime et du daemon (oci/runC et cri/containerd).
Kubernetes a d’ailleurs arrêté le support direct de Docker.
#12
Merci pour l’article, très intéressant !
Petite question : pourquoi “devoir” importer un OS (par exemple ici Alpine) si un container est supposé contenir juste l’application (et ses dependances) ?
#13
Personnellement je considère toujours qu’un container est jetable et destructible à volonté. En ayant ceci constamment en tête, ça évite justement de faire l’erreur de laisser des choses “précieuses” dedans.
La perte de données à l’arrêt du container (enfin, son retour à l’état nominal pour être plus précis ) est l’un des premiers points qui avaient été cités quand j’avais suivi la formation Docker Official il y a 3⁄4 ans
) est l’un des premiers points qui avaient été cités quand j’avais suivi la formation Docker Official il y a 3⁄4 ans  (mais je ne te cache pas qu’avant ça, je l’avais appris aussi à mes dépends)
(mais je ne te cache pas qu’avant ça, je l’avais appris aussi à mes dépends)
Dans les travaux de mon équipe qui impliquent l’utilisation de containers, c’est un des éléments essentiels qu’on considère pour éviter des catastrophes. D’ailleurs, quand on réfléchi dans le sens “création d’environnements d’exécution à la volée”, ça permet de penser son DRP en parallèle lors de la construction de l’application. Après, il faut évidemment que l’application soit elle-même développée pour de la conteneurisation. Faire du Docker pour faire du Docker, ça n’a aucun intérêt si derrière le MCO de l’appli est aussi monolithique que sur un serveur traditionnel… (hélas, on a des applis conçues comme ça dans notre périmètre )
)
Pareil, je trouve qu’ils sont en perte de vitesse. Il me semble justement que Microsoft Azure utilise aussi containerd et non plus Docker en moteur de conteneurisation pour ses AKS. GKE propose encore le choix entre les deux je crois.
#14
Pour simplifier brutalement : l’image de base (dans ton exemple : Alpine) c’est grosso merdo la couche GNU intégrée de la distrib qui vient s’interfacer avec le Kernel de l’hôte. Au moment de construire l’image, elle a besoin des outils de base proposés par GNU.
Pour construire ton image applicative avec ses dépendances, tu dois les installer dedans. Et pour ça tu utilises rien de plus que le gestionnaire de package de la distrib ou le constructeur de la techno de l’appli (genre npm, maven, pip, toussa).
Pour aller un peu plus loin, tu as le multistage pour la construction d’image. Comme chaque action dans la construction de l’image empile des couches telle un tas de pancakes, ça fait que l’image produite peut peser plusieurs GB sans soucis (ex : l’image Azure Cli fait à elle seule plus d’1GB).
L’astuce du multistage permet d’avoir une première action où tout l’environnement de compilation de l’appli est exécuté, puis le seconde stage récupère l’artefact produit (via la copie du layer concerné) dans une image plus légère qui ne contient que le runtime.
#14.1
Merci pour les explications, c’est plus clair maintenant !
#15
merci pour l’article
#16
Merci beaucoup pour cet article très bien fait. C’est ce genre d’article qui permet de bien saisir les enjeux et principes d’une solution ! Le tout agrémenté d’exemples bien choisis.
Bonne suite d’articles sur Docker !
#16.1
Et en plus on apprend à calculer des racines cubiques en Python
#17
Merci pour cet article, très clair. Maintenant il va falloir appliquer tout ça :)
#18
+1 pour podman, et je me suis mis depuis peu à utiliser le multi-stage comme décrit par SebGF, avec des images “distroless” ou “minimal” ça change la vie!
On crée une image intermédiaire qui embarque toute la toolchain, et une image finale réduite qui n’embarque que le résultat, tout ça au sein d’une même Dockerfile.
Et si alpine reste peut-être une référence concernant la taille de l’image, si on prend en compte d’autres paramètres comme la politique de support/backporting/sécurité d’autres images tirent leur épingle du jeu comme la ubi8-minimal de redhat ou les “distroless” chez gcr.io
#18.1
Pour ma part j’ai déjà constaté que si Alpine est généralement intéressante, parfois il est plus pertinent de partir d’une Debian ou équivalent car l’ajout de paquets sur Alpine peut s’avérer plus fastidieux.
Dernier exemple en date que j’ai en tête, on avait tenté une base Alpine pour un outil Python, mais des requirements nécessitaient de compiler des objets là où la base Debian les avait prêts à l’emploi dans le gestionnaire de paquets. La base Alpine s’est retrouvée avec 1GB de layer supplémentaire là où la base Debian n’a eu qu’une centaine de MB en plus.
Bref, des Lego avec lesquels s’amuser pour construire des trucs cools.
#18.2
Oui Alpine est pas mal pour certains besoins mais montre la limite de ses outils de compilations/libc spécifiques pour d’autres. Note que l’image Python a un tag debian “slim” pour ceux qui veulent une image compacte sur une base “classique”
#18.3
Yep tout à fait, et nous étions parti de la “slim” en l’occurrence.
#19
Merci de l’info. Je suis un noob complet de la question et je pensais docker / podman pas compatible suite à une tentative d’installer une instance bitwarden sur un RHEL avec podman qui se termina en échec.
#19.1
Le flag
--privilegedpermet aussi de résoudre différents soucis de blocages liés à la sécurité. Contrairement à ce que son nom indique, ce n’est pas un “sudo” (le container n’a aucun privilège supplémentaire), c’est juste un flag pour modifier le comportement du moteur vis à vis des couches de sécurité.https://www.redhat.com/sysadmin/privileged-flag-container-engines
#20
j’ai un commentaire somme toute ridicule mais je le fais tout de meme :
le graph infra VM vs infra conteneur me gène visuellement parlant, l’espacement entre les blocs verticaux ne sont pas identique et l’alignement “bas” des deux blocs “infrastrucuture” n’est pas non plus “bon”.
c’est tout con, mais mes yeux ont bloqués là dessus je sais pas pourquoi.
Sinon j’ai pas encore tout lut, mais c’est intéressant, merci :)
#21
Sur le sujet des images docker, c’est tout frais ça vient de sortir : http://jpetazzo.github.io/2021/11/30/docker-build-container-images-antipatterns/
“Anti-Patterns When Building Container Images” par @jpetazzo