

Git est perçu comme un outil de barbu (bien que son inventeur Linus Torvalds soit rasé de près), de défenseur du logiciel libre, développeur chevronné, ne jurant que par la ligne de commandes. Il peut pourtant vous aider dans des tâches diverses comme pour les mises à jour d'un simple texte.
Utiliser un outil de gestion de versions tel que Git peut effrayer, à raison. Il s'agit en effet d'un outil ultra-complet, pensé pour les amateurs d'interpréteurs de commandes et les développeurs, avec ses complexités.
Git pour tous et pas uniquement pour le code source
Pour autant, il est aisé de le prendre en main pour des besoins basiques et donc de tenter l'expérience. Surtout que de nombreux éditeurs le gèrent nativement avec la plupart des fonctionnalités accessibles via une interface graphique. Sans parler des clients dédiés comme GitHub Desktop, GitExtensions, GitKraken, SourceTree, etc.
En outre, la gestion de versions n'est pas utile qu'à ceux qui produisent du code source. Les documents texte, rédigés avec des langages de balisage simples comme le Markdown, sont aussi dans ses cordes. C'est d'ailleurs en faisant des recherches sur le sujet que l'idée de ce tutoriel est née.
Ne vous attendez donc pas à un cours exhaustif sur le fonctionnement de Git, l'outil demandant des années de pratique pour être pleinement maîtrisé. Mais il faut bien commencer un jour. Dans cette entrée en matière, nous vous expliquerons ses bases pour la création et l'édition d'un document, jusqu'à sa diffusion.
Pour cela, nous utiliserons plusieurs outils, tout d'abord en ligne de commandes pour bien comprendre les mécaniques de Git et son vocabulaire, avant de passer à des outils plus simples pour le quotidien.
Notre dossier sur la maîtrise de Git et de ses plateformes :
- Open source, libre et communs : contribuer ne nécessite pas de développer
- Apprenez à utiliser Git : les bases pour l'évolution d'un document
- Git remote : comment héberger vos documents et codes source sur un serveur
- Git : comment travailler avec plusieurs remotes
- Fork et pull request : la participation open source par l'exemple
- GitHub CLI 1.0 est disponible : comment l'installer et l'utiliser
Installer Git, initialiser un premier dépôt local
Tout d'abord, il faut installer Git. Sous Linux ou dans le sous-système Linux de Windows (WSL), il est le plus souvent présent. Sous macOS ou Windows, il faudra le télécharger et l'installer. La plupart des gestionnaires de paquets l'ont dans leurs dépôts de base. C'est notamment le cas des plus populaires comme Brew, Chocolatey ou winget.
Pendant une installation classique sous Windows, plusieurs questions vous seront posées. Vous pouvez laisser les paramètres par défaut, mais certains sont utiles à activer comme la vérification de nouvelle version et la modification de l'éditeur utilisé, tel qu'Atom, Notepad++ ou Visual Studio Code.

Une documentation complète est disponible en français, ainsi que d'autres ressources pouvant être utiles comme une cheat sheet listant les principales commandes ou des vidéos (en anglais) pour comprendre les bases. Une liste des principaux clients en interface graphique (GUI), gratuits/open source ou non, est aussi proposée par ici.
Une fois l'installation terminée, ouvrez un terminal et créez un dossier à l'emplacement de votre choix. Placez-vous à sa racine. Nous allons l'initialiser pour en faire ce que l'on nomme un dépôt Git (repository) local, qui sera utilisé comme tel et où aura lieu le suivi des versions. Pour cela, une simple commande suffit :
git init
Pour vérifier que tout fonctionne, tapez la commande suivante :
git status
Si tout se passe bien vous devriez obtenir le message suivant :
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)
Pour faire simple, Git indique que vous êtes sur la branche principale (master), en attente de modifications.


Création d'un fichier et ajout à l'index
Nous allons créer un premier fichier et l'ouvrir avec un éditeur gérant nativement Git, Visual Studio Code dans notre cas. Le fonctionnement sera similaire dans les autres.
code .
Cette commande lance Visual Studio Code dans le dossier courant. Nous créons un fichier nommé README.md via l'interface. Nous y écrivons une simple ligne de texte sous forme d'un titre au format Markdown :
# Hello, world !
Une fois le fichier enregistré (CTRL+S), tapez à nouveau git status dans votre terminal. Cette fois, vous obtiendrez un message différent vous indiquant que le fichier README.MD est untracked. Comprendre qu'il existe, mais qu'il n'a pas été demandé à Git de le suivre. Cela se fait en une commande :
git add README.MD
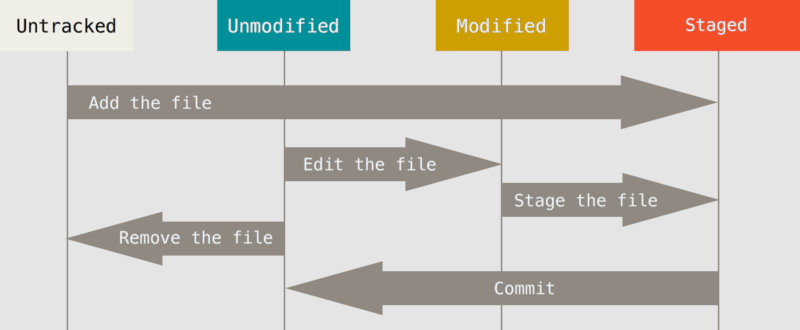
Notez que cette étape est « 2-en-1 » puisqu'elle ajoute le fichier à l'index, en attente de validation (staged). Par la suite, il pourra avoir deux autres états et être considéré comme modifié ou non. Pour qu'un fichier ne soit plus suivi, il faudra le demander explicitement (remove), mais ce ne sera pas nécessaire en général.
Vérifiez à nouveau le statut de votre dépôt (git status). Cette fois le fichier sera bien affiché en vert avec un message indiquant qu'il contient des modifications devant être validées, une étape que l'on nomme commit. Vous avez alors deux possibilités : effectuer votre commit depuis le terminal ou l'interface graphique de votre éditeur.
Notez que la première fois, il vous sera parfois demandé de configurer des identifiants. En effet, chaque commit est unique, associé à une empreinte (hash) et à un nom/pseudo et un email. Si Git trouve ces informations dans votre compte utilisateur il va les utiliser. Mais vous pouvez aussi les préciser :
git config --global user.email "[email protected]"
git config --global user.name "votre nom ou pseudo"
Ces commandes effectuent une modification globale, considérée comme identique au sein de la machine. Vous pouvez retirer cet argument pour qu'elle soit limitée au compte utilisateur actuel.
Attention, si vous partagez votre code sur des plateformes en ligne, ces informations seront publiques. Veillez donc à utiliser des éléments diffusables à tous. Notez que certains services utilisent un email sur leur domaine faisant office de filtre. Cela peut être une solution. À vous de voir ce qui vous convient le mieux.
Revenons à notre commit tel qu'il doit être formulé en ligne de commandes :
git commit -m "Ceci est un premier essai"
L'argument « -m » permet d'ajouter une description. Elle n'est pas nécessaire, mais c'est une habitude à prendre car elle peut s'avérer utile pour assurer un bon suivi des modifications sur le long terme. Dans un client graphique, la procédure est similaire : dans la zone de l'interface dédiée à la gestion des versions, on voit la liste des fichiers en attente avec la possibilité d'ajouter une description puis d'effectuer le commit.


Vous pouvez voir la modification effectuée avec diverses commandes comme git log ou git show qui sera plus complète. git log --oneline affiche à l'inverse une version plus courte, notamment de l'empreinte. Cette dernière pourra être utile dans certains cas, comme pour revenir en arrière ou analyser un commit particulier.
Si vous avez un doute sur le fonctionnement d'une commande, il suffit d'ajouter l'argument --help à la fin de celle-ci pour obtenir son aide détaillée, en ligne ou dans le terminal selon les cas. Par exemple :
git commit --help
Nouvelle modification, validée en une commande
Effectuons une nouvelle modification à notre fichier en remplaçant son contenu par le suivant :
# Titre 1
## Sous-titre 1
Ceci est un simple texte
# Titre 2
Ceci est un autre texte, mais cette fois on ajoute une citation :
> Cogito ergo sum
On sauvegarde le fichier. L'interface de votre éditeur de texte doit normalement vous signaler que des modifications ont été détectées et vous permettre de les visualiser. Une commande existe aussi pour cela :
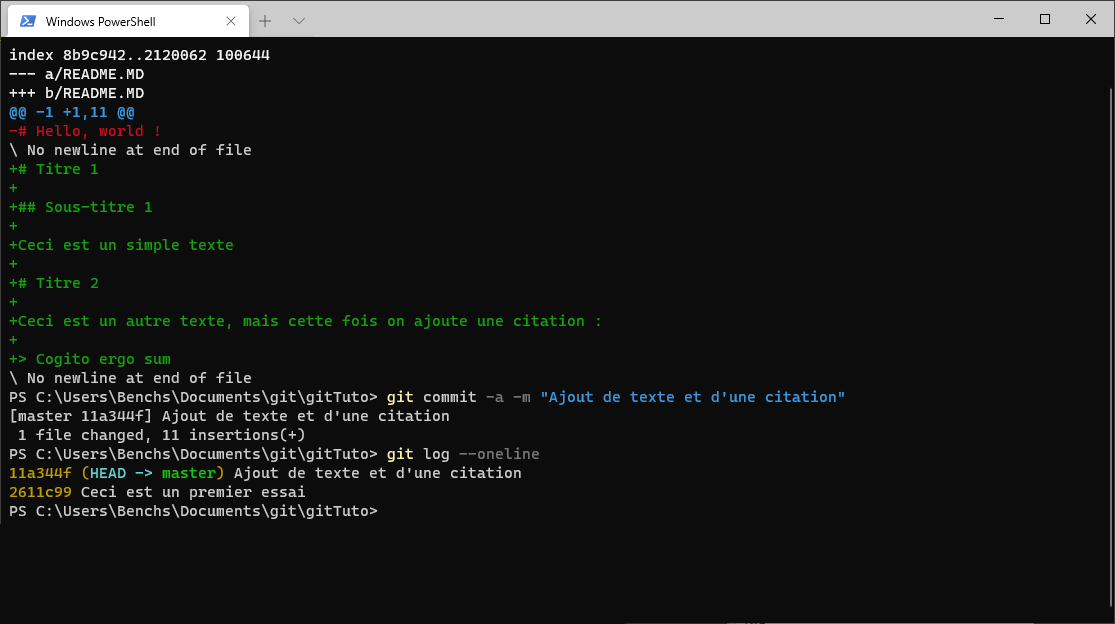
git diff
Les ajouts sont indiqués en vert avec un « + », les suppressions en rouge avec un « - ». Cette fois, nous allons effectuer l'ajout du fichier à l'index et la validation des modifications en une seule commande :
git commit -a -m "Ajout de texte et d'une citation"
Ici, le « -a » (ou --all) indique que tous les fichiers modifiés doivent être staged, en attente d'un commit.
Branches et fusion : des modifications plus sereines
Imaginez maintenant que vous souhaitiez effectuer des modifications à votre texte, mais sans prendre le risque de perdre le travail que vous avez effectué jusque-là si vous décidez de revenir en arrière.
Pour cela, les outils de gestion de versions (dont Git) disposent d'un principe : les branches. Comme nous l'avons évoqué plus haut, vous êtes par défaut sur la branche master. Imaginons maintenant que vous ajoutiez des listes à votre texte pour voir le résultat sans prendre de risque. L'une des solutions est de créer une branche « Liste », d'y faire vos modifications, puis de les valider dans votre branche master si le résultat vous convient.
Cette solution est couramment utilisée dans le développement logiciel pour travailler sur l'ajout d'une fonctionnalité spécifique, notamment lorsque l'on intervient à plusieurs sur un même code. Des fonctionnalités multiples peuvent ainsi être préparées dans différentes branches avant que l'on ne les réconcilie par la suite.
Ce workflow est souvent représenté sous forme d'un graphique (voir ci-dessous). Pour la réconciliation, deux approches s'opposent : la fusion (merge) et rebase. Nous n'étudierons ici que la première, la seconde consistant à réécrire l'historique des commits selon l'évolution de la branche. Chacune a ses avantages et inconvénients.
Il est surtout important d'utiliser celle qui vous conviendra le mieux selon vos projets et besoins, et de vous adapter aux pratiques des projets tiers sur lesquels vous aurez à travailler. Même si certains en sont persuadés, retenez qu'aucune approche n'est meilleure. Il s'agit de gestions différentes de l'historique d'un projet.
Si le sujet vous intéresse, vous pouvez lire ce guide de la documentation d'Atlassian BitBucket.
 L'évolution des commits suite à l'ajout de fonctionnalités dans une branche puis une fusion (merge)
L'évolution des commits suite à l'ajout de fonctionnalités dans une branche puis une fusion (merge)
Pour comprendre comment fonctionnent les branches, nous allons en créer une, puis y effectuer une modification et la fusionner avec le texte de départ. Commençons par la création :
git branch Liste
On demande à Git de nous passer sur la branche Liste :
git switch Liste
Dans notre éditeur, on ajoute le texte suivant, on enregistre la modification et on commit :
# Différents types de listes
## Liste des jours
* Lundi
* Mardi
* Mercredi
* Jeudi
* Vendredi
* Samedi
* Dimanche
## Liste des mois
1. Janvier
2. Février
3. Mars
4. Avril
5. Mai
6. Juin
7. Juillet
8. Août
9. Septembre
10. Octobre
11. Novembre
12. Décembre
On se retrouve alors avec une branche master qui contient le texte de départ et une branche Liste contenant un commit et donc une version différente du texte. Notez que passer d'une branche à l'autre modifie les fichiers accessibles localement, donc ce qui est affiché dans l'éditeur. C'est l'un des avantages de cette méthode.
On peut visualiser le tout sous la forme d'un petit graphique avec des outils spécifiques. Il existe toutefois une commande pour obtenir un résultat visuel similaire depuis le terminal :
git log --oneline --graph --all
Passons à la fusion (merge). Il faut retourner dans la branche master et fusionner les branches. Cela consiste à créer un commit répercutant les différences constatées entre la branche courante et celle à fusionner. Vous pouvez le faire pour plusieurs branches à la fois, mais c'est déconseillé. En effet, il faudrait en passer par une procédure de résolution de conflits depuis l'éditeur, ce que l'on cherche à éviter.
Voici la procédure à suivre :
git switch master
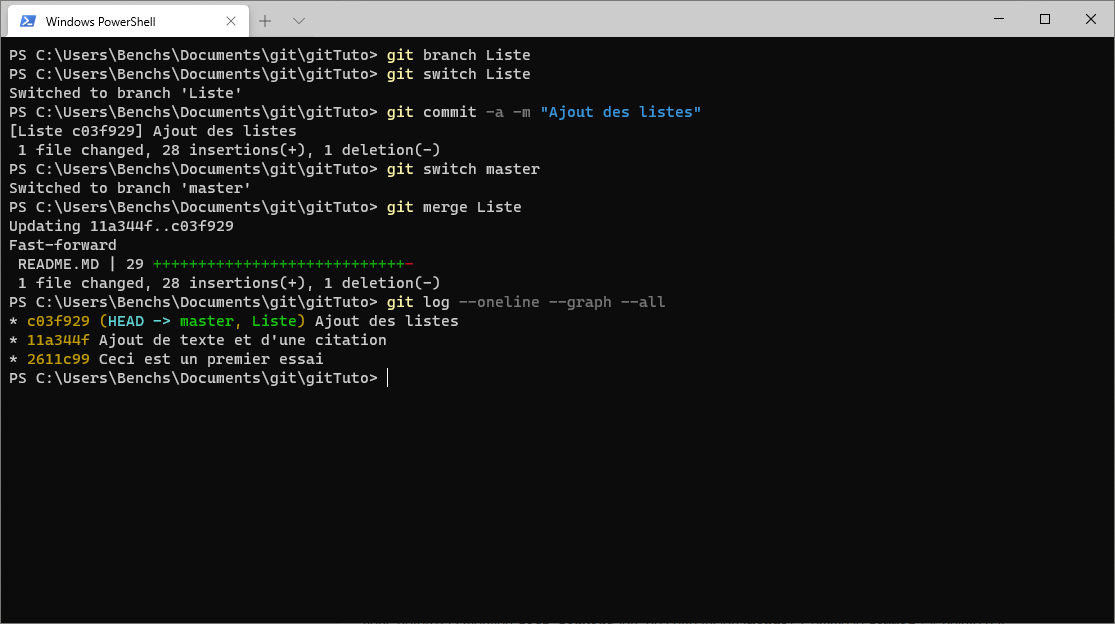
git merge Liste
Une fois la procédure terminée, le texte devrait intégrer le contenu de base, les listes et le code. Vous pouvez visualiser à nouveau l'historique de votre dépôt sous forme de graphique. Le résultat est assez simple puisqu'il n'y avait qu'un commit, sans modifications dans la branche principale.
Git a donc utilisé une procédure dite Fast-forward, avec le résultat suivant :
Dans la suite de ce dossier, nous étudierons le travail à plusieurs sur un même document, notamment à travers un dépôt distant (remote) et des services d'hébergement Git comme GitLab ou GitHub.

























Commentaires (54)
#1
Super article pour les non initiés à cet outil à la fois obscur et extrêmement intelligent.
Il y a une lecture que je conseille à ceux qui utilisent déjà git au quotidien mais qui ont l’impression de passer un peu à côté de la puissance de l’outil ou qui le trouvent inutilement compliqué : Git From The Bottom Up.
C’est un “livre” qui se lit en un peu moins d’une heure et qui permet d’apprendre/comprendre git de manière “inversée” : au lieu d’expliquer comment utiliser git puis comment ça fonctionne, ce livre apprend d’abord comment fonctionne “réellement / techniquement” Git puis en déduit comment l’utiliser.
Personnellement j’ai compris énormément de choses juste en le lisant. Et surtout, j’ai compris des commandes que je pensais extrêmement mal nommées tellement elles me semblaient obscures ou incantatoires. Et maintenant je les trouve au contraire d’une clarté qui force au génie (de Torvalds).
Je sais pas si c’est accessible aux débutants de 0, mais ce qui est sûr c’est que c’est extrêmement accessible à qui a déjà juste utilisé un peu git (du genre, à la suite de l’article ci dessus) et qu’après l’avoir lu je me suis enfin senti autonome sur git.
#1.1
C’est souvent le cas, en allant dans les tréfonds d’un outil on en comprends mieux les mécaniques ou ce qui peut paraître étrange/mal pensé (alors que pas trop). Bon après, on peut aussi dire qu’une logique qui ne paraît pas claire après 200h d’explications a peut être besoin d’être présentée autrement
#1.2
Yep, mais souvent fouiller les tréfonds d’un outil peut être décourageant, d’où le “livre” que j’ai cité qui y arrive brillamment en l’espace d’une heure (perso je l’avais lu sur une pause dej).
Par contre là où je te rejoint, c’est que pour un outil “du quotidien” et pour les tâches courantes (versionnage basique, switch entre les tâches …), git peut sembler un peu aride. Mais peut être que ce qui manque réellement, ce sont des “frontends” (pas forcément au sens graphique du terme) qui viennent adapter la puissance de git à un métier en particulier (il y a un peu git flow pour le dev mais ça reste plus un framework que personne ne respecte réellement plus qu’une réelle abstraction de git adaptée au métier de développeur).
#1.4
Et encore ils ont fait beeaucoup d’efforts ces trois dernières années, notamment en officialisant certains alias d’enchaînements de commandes qui permettent de clairement distinguer différents cas d’usage (typiquement “checkout” vs “checkout – file” pas mal de gens que j’ai formé ont galéré à cause de ça. Maintenant il y une commande dédiée, ‘restore’ je crois, pour le deuxième cas d’usage, c’est devenu limpide).
Après tout, clairement comprendre comment git permet d’atteindre un niveau de maîtrise assez incroyable, mais tout le monde n’en a pas besoin non plus. :=)
#1.3
Merci pour le lien, je le lirai avec intérêt !
#2
Une “cheat sheet” interactive très sympa qui montre les commandes faisable et leurs source et destination
https://ndpsoftware.com/git-cheatsheet.html
Et un petit jeu interactif pour apprendre le branching dans git :
https://learngitbranching.js.org/?locale=fr_FR
#3
J’utilise git depuis des années mais je suis toujours un débutant, ça ne rentre pas lol.
#3.1
D’où la précision en début d’article
Il y a aussi des soucis inhérents à ce genre d’outils : certains trucs ont été ajouté/modifié au cours de son histoire, pas forcément les guides en ligne sur lesquels se basent les débutants et ceux qui font des tutos à la va-vite. On rencontre souvent ce problème.
Puis il y a les batailles de chapelle qui n’aident pas forcément à avancer sur un sujet. Notamment le merge/rebase, github/gitlab et autres “non mais ce client c’est le meilleur (jusqu’à ce qu’il renforce son offre payante comme Kraken).
Tout ça fait un “bruit” autour d’un outil de base qui décourage parfois les néophytes (surtout quand tout le monde se tape dessus 3 jours après qu’ils aient posé une simple question).
#4
#4.1
Si on pouvait éviter de dériver inutilement, merci BTW, j’utilise les termes de l’outil et de sa doc. Si Git modifie ses dénominations, on utilisera les nouvelles comme pour n’importe quel autre outil au moment où l’on rédige nos guides/tutos.
BTW, j’utilise les termes de l’outil et de sa doc. Si Git modifie ses dénominations, on utilisera les nouvelles comme pour n’importe quel autre outil au moment où l’on rédige nos guides/tutos.
#5
Je l’utilise rarement, mais il existe aussi tig et qui est intégré à Git for Windows: c’est un peu le vim/less collé sur la lecture de l’historique et des diffs.
#6
Ecrire des documents en Markdown, c’est quand même un peu pour les barbus (les gens “normaux” utilisent Microsoft Word ou Google Docs). Et pour les fichiers docx, Git est beaucoup moins efficace (ou alors je ne connais pas l’astuce)
#6.1
C’était pour donner un exemple autre que du code source (mais non les langages de balisage ne touchent pas que les barbus. Il y a pas mal de gens qui rédigent dans de tels formats plutôt que du Word & co qui ajoutent pas mal de complexité, notamment dans la lecture simple et le traitement des documents). Le traitement/conversion pouvant être fait ensuite.
#6.2
J’aime beaucoup l’attribution aux gens “normaux” de word et docs!
Ces gens “normaux” peuvent donc utiliser aussi git.
#7
Sympa, merci. Toujours utile d’avoir ce genre de lecture sous la main
#8
Comme quoi on en apprends tous les jours, je ne connaissais pas git switch ! J’étais toujours resté sur l’équivalent avec git checkout.
#8.1
De mémoire checkout fait la même chose dans ce contexte mais peut être utilisé à d’autres fins, ce qui n’est pas le cas de switch qui sert juste à changer de branche.
#9
pourquoi faire un document de centaines de Ko sous word alors qu’un petit fichier markdown suffit d’autant plus qu’il existe de nombreuses passerelles pour produire depuis le markdown à peu près ce que l’on veut comme format.
De plus la comparaison entre deux version markdown est très aisée
#10
Personnellement, je me suis fait un alias (gla), avec quelques infos en plus :
Edit: Il semble y avoir une erreur d’affichage :)
#11
Comment ça sans “git rebase”, c’est la meilleure commande !
#11.1
#11.2
Sinon généralement ça se passe bien
#12
Le rebase c’est bien, jusqu’à ce qu’un système de branche circulaire soit mise en place, et que quelqu’un fait un rebase puis ne comprend pas qu’il a ces propres commits en conflict avec ces mêmes commits
#13
L’option switch n’est pas dans git –help.
#13.1
Si et il est présent dans la liste des commandes dans l’aide de base de git. Tu es sur quelle version ? Pour rappel git switch/restore ça date de la version 2.23.0 d’août 2019, donc pas totalement nouveau,
#13.2
Je suis en 2.17.1, pas de màj proposée. Je vais essayer de trouver un ppa pour avoir une version plus récente.
Edit : https://launchpad.net/~git-core/+archive/ubuntu/ppa
#13.3
La 20.04 LTS est sortie, il faut se mettre à jour
#13.4
Il y a des programmes qui ne sont plus dispo en 20.04 (j’ai oublié lesquels, j’avais vu ça en avril). Et puis si les LTS durent 5 ans, c’est pas pour rien :)
#13.5
Oui, après près de deux ans de retard sur Git c’est moche quand même 😬
#13.6
Ouais, alors à prendre avec des pincettes tout de même.
La doc indique clairement que c’est une commande expérimentale, tout n’est pas encore rentré dans le marbre concernant cette commande.
THIS COMMAND IS EXPERIMENTAL. THE BEHAVIOR MAY CHANGE.
(src: https://git-scm.com/docs/git-switch# / v2.27)
Et typiquement, elle n’est pas sur la dernière Stable de Debian.
Ceci étant dit, je comprends tout à fait qu’elle facilite la compréhension du bouzin pour le néophyte, vis à vis du
checkoutqui a plusieurs casquettes.P.S. Damn, ce Markdown qui n’en n’est pas me rend confus à chaque fois.
#13.7
Oui après son comportement de base (changer de branche) ne risque pas de fondamentalement changer plus d’un an après son introduction ;)
Pour le reste et comme dit pour Ubuntu 18.04 LTS, la version actuelle est la 2.20 de décembre 2018. Je ne suis pas responsable des mauvaises pratiques des distributions Linux
On rédige toujours les tutos de ce genre au regard des docs récentes. Les backports sont d’ailleurs en 2.27.
#14
Ha bha tien, si il y a bien une commande git que j’utilise presque tout les jours et qui me semble sortir de nul part c’est bien celle là. checkout, ok mais alors le “–” Il sort d’où ?
Mais du coups merci pour le “restore”, c’est effectivement plus claire.
#14.1
En bash le – signifie la fin de toutes les options (-a -b -c -d …) d’une ligne de commande. Signifiant que tout ce qui est derrière est l’input de la commande.
Exemple : une fausse manip et un fichier “-v” est créé. Tu veux le supprimer, mais rm -v sera considéré comme l’argument rm –verbose.
Il faut donc lui dire rm – -v (rm findesoptions -v) pour qu’il accepte de faire la suppression.
Edit : un peu relou l’affichage code en ligne qui créé des retours chariot.
#14.2
Ok merci, :)
#14.3
Pour être plus précis vis à vis de git, mettre – sert à éviter le cas où le fichier à restaurer aurait le même nom qu’une branche. (ex : je veux restaurer un fichier du nom de “master”, git va croire que je veux aller sur la branche “master”)
Car sinon dans les faits, git checkout . fonctionne aussi.
https://git-scm.com/docs/git-checkout#_examples
#15
Sur le principe, git, c’est génial.
Mais franchement, qu’est-ce que les CVS d’antan me manquent…perforce, clearcase, et autres, C’était quand même moins compliqué et ça faisait le taf.
(oui oui je sais…“c’était mieux aaaaaavant”)
#15.1
J’aimais beaucoup TFS, surtout le checkout partiel, en plus il était possible de l’utiliser en mode connecté ou déconnecté suffisait de choisir ce qu’on voulait dans les paramètres du workspace.
#15.2
Oui, après on oublie aussi pas mal que Git ne s’est pas imposé comme la référence du secteur par magie ou par la force de persuasion de Torvalds. Beaucoup des CVS utilisés auparavant avaient leur limites et leurs problèmes (centralisation, lourdeurs, complexité au travail en équipe, inadaptés à de gros projets, etc. Git apportait des réponses concrètes.
Mais beaucoup de CVS continuent d’exister. On est donc toujours libre de les utiliser si on le souhaite. C’est peut être même une solution qui peut s’avérer pratique pour de petits projets perso où l’on peu se passer de ce qui est à la fois le gros atout et le gros défaut de Git : être capable de tout mais au prix d’une certaine complexité.
#15.3
Je ne suis pas spécialement d’accord avec la complexité de Git (après je n’ai de recul qu’avec SVN, sinon je n’ai vu que ce dernier). Celle-ci s’adapte au besoin d’une certaine façon.
Un projet maintenu par une seule personne n’aura pas spécifiquement besoin de gérer la complexité de l’arbre, des branches, de faire du cherry-picking et autres joyeusetés. A partir de là, c’est principalement “add, commit, push, bisou” et git n’a aucune complexité. Voire peut être de se faire une branche de test et merge. Soit rien de bien violent.
Au final elle s’adapte au projet. De mon expérience, nous en avons qui sont très simples (les repo sont gérés en auto par la CICD), et d’autres plus complexes car liés à des packages pour lesquels on doit acter le contenu à livrer parmi tous les points développés et donc construire le livrable en conséquence. A ce moment-là l’intelligence de Git est très puissante, mais un peu plus difficile à appréhender.
#15.4
Git reste un outil complexe dans le sens ou tu peux faire un peu tout et n’importe quoi avec. Oui, tu peux simplement faire des choses basiques (comme on l’explique ici). Mais tu peux vite aussi te retrouver dans des situations peu confortables si tu ne fais pas attention. Ce qui ne sera pas le cas avec un outil plus limité/cadré.
#16
git version 1.8.3.1 sur tout nos serveurs
#16.1
RHEL / CentOS 7 ?
Il me semble que c’est la version qu’on trouve dessus.
Bah il suffit de faire une branche “test” avec un fichier “test” pour foutre le bordel
Pour ça que mes mots clés sont “pouet”, “tralala” et “coucou”.
#16.2
Haha git 1.8 sur les serveur de prod souvent en CentOS 7, à chaque fois j’ai envie de me tirer une balle quand je vois ça !
Heureusement il y a le RHSCL !
https://www.softwarecollections.org/
#16.3
Yep c’est le souci des distributions avec support à long terme telles que RHEL quand les logiciels n’ont pas de canal LTS.
Software Collection aide pas mal pour ça, ou encore quand l’outil possède son propre repo (comme Ansible, quand on ne veut pas spécialement l’installer via pip) comme ça on évite d’être tributaire des repos de la distrib quand les versions proposées sont trop anciennes.
Le plus relou, c’est surtout des cas comme Nextcloud qui a cassé l’année dernière la compatibilité PHP 7.1 à partir de sa version 16 (de mémoire) alors que celle-ci faisait partie de la LTS d’Ubuntu 16.04 qui est supportée jusqu’en 2021. Bon, à titre perso je suis tranquille pour quelques temps, tous mes serveurs persos sont en CentOS 8.2… Et j’essaye de pousser au taff pour qu’on commence à jouer avec histoire d’avoir une distrib un peu moins vieille que la 7.
#16.4
Pour le coup ansible est très simple à mettre à jour vu que c’est maintenu par RedHat, donc même sur une CentOS / RHEL 7 ont a les dernières versions très simplement même sans utiliser le dépot ansible de souvenir.
Mais oui les ditribs LTS utilisées dans la majorité des prod ont ce gros inconvénient.
Et te plaint pas pour ton taf, j’arrive encore à trouver du RHEL 2 en cherchant bien. :)
#16.5
Effectivement pour ansible je confondais avec le fait qu’on est passé par le repo officiel pour pouvoir maîtriser la version. (le temps de corriger les éventuelles dépréciations ou valider que le code est OK avec les nouvelles avant de la mettre sur nos outils de dep)
#17
Le premier qui ose créer un fichier avec un mot clé, il passe par la fenêtre
#18
H.S. Bon, bah, j’abandonne le Markdown pour ce soir :) Ici, les sauts de lignes ne sont pas respectés en cohérence avec l’article Wikipedia linké sur le bouton (I) des commentaires.
#18.1
Je me suis permis d’ouvrir une issue sur leur bugtracker à ce sujet, c’est assez irritant d’avoir un résultat cassé vis à vis de la simplicité du Markdown.
#18.2
Disons que c’est même pour ça (que les lecteurs fassent des remontées) qu’on a un bugtracker ;)
#19
Pour avoir utilisé plusieurs années SVN avant de passer à Git (depuis 10 ans déjà rhâ), ce dernier permet beaucoup plus de choses, même si je n’ai pas retesté SVN depuis, il existe encore ?
Il est quasiment impossible de perdre quelque chose. Par contre, je n’ai jamais compris pourquoi git checkout permettait de revert un fichier…et aussi de changer de branche. Ca m’a joué quelques tours au début. Heureusement , tous les IDE modernes ont un historique local !
#19.1
Oui, il est géré par la fondation Apache depuis une dizaine d’années.
#19.2
Je vais jeter un œil, merci !
#19.3
En fait la commande checkout sert à naviguer entre des arbres de commits et les états de révision. D’où le fait qu’elle donne l’impression d’être un peu fourre tout et nébuleuse de prime abord…. Et qu’ils ont depuis ajouté deux commandes plus spécifiques pour changer de branche et restorer un fichier à un état donné.