

Le tribunal de commerce de Paris a condamné le développeur d'un moteur de recherche à « cesser de dénigrer » Qwant, au motif que « la divulgation d’une information de nature à jeter le discrédit sur un concurrent constitue un dénigrement, peu important qu’elle soit exacte, l’exception de vérité n’étant pas admise en [la] matière ». Nous avons donc voulu vérifier ce qu’il en était. Retour d'abord sur la génèse du conflit, puis, dans un second temps, sur son « fact-check ».
Véritable serpent de mer, la question de la dépendance de Qwant à Microsoft Bing est un boulet qu’il traîne depuis son lancement, en février 2013.
Edward Snowden n’avait pas encore fait son coming out, et la protection de la vie privée n’était donc pas le maître-mot du moteur. Dans son tout premier communiqué de presse, Qwant se présentait en effet comme « un moteur de recherche révolutionnaire comme il n'en a jamais existé », et qui « innove radicalement ». De fait, il proposait, sur une seule et même page, les résultats issus du web, des images et vidéos, des actualités, du shopping et « surtout les réseaux sociaux ».
En réponse à un journaliste qui lui demandait pourquoi il avait, jusque là, « gardé le secret sur ce moteur », Jean-Manuel Rozan, co-fondateur de Qwant, expliquait avoir « fait exprès de développer discrètement, pendant deux ans, ce moteur de recherche pour éviter de donner nos bonnes idées à nos concurrents ».
Mais trois jours plus tard, un blogueur anonyme révélait que celui qui était alors présenté comme un « Google killer 100 % français », ne faisait jamais, pour ses recherches web et médias, « qu’utiliser et resservir les résultats de Bing : toutes les requêtes renvoient exactement les mêmes résultats que Bing (...) En gros : Qwant paye Bing pour afficher ses résultats ».
Son « knowledge graph », lui, ne faisait que « récupérer le résumé de la colonne de droite de Wikipedia et l’intégrer dans sa page », mais sans le préciser, contrairement à ce que prévoyait la licence de Wikipedia. Cet « oubli » fut d'ailleurs rectifié dans la foulée.
En guise de conclusion, le blogueur qualifiait Qwant de « vraie déception » : « ce n’est pas un nouveau moteur de recherche et encore moins un moteur de recherche « made in France ». C’est juste une interface, pas forcément réussie, qui utilise les technologies d’autres moteurs de recherche et qui les présente à sa sauce ».
Il se demandait également « pourquoi cela a demandé 2 ans pour créer ce site, sachant qu’il n’y a aucune réelle technologie originale ni innovante derrière ? », tout en déplorant « beaucoup de buzz pour peu de chose et un pauvre travail d’investigation de la part de la presse spécialisée ».
« T'as juste étripé Qwant anonymement »
En réponse, un certain Laurent Bourrelly, se présentant comme un « search engine hacker », l’abreuvait d’insultes, au motif qu’il aurait « étripé Qwant anonymement, sans avoir pris la peine de (s)’informer correctement », et de conclure : « Ça mérite l’échafaud ».

Suite à la polémique, Qwant reconnaissait sur son blog que s’il avait bien « développé un système propre d’indexation », ce dernier nécessitait « non seulement de gigantesques puissances de calcul et de stockage, mais également un historique important ». Ce pourquoi Qwant complétait ses propres données avec des informations « obtenues auprès d’autres moteurs de recherches durant la phase de montée en puissance de son infrastructure ».
« Ces mélanges disparaîtront dès lors que le déploiement sera finalisé et l’ensemble des résultats proposés proviendront dès lors du seul travail d’indexation et de classement effectué par Qwant », précisait le communiqué.
Au Figaro, qui s’étonnait de découvrir que le moteur recourait « aussi massivement aux résultats de Bing (…) moyennant finances, selon un contrat passé avec Microsoft », Qwant reconnut que le fait de ne l’avoir jamais mentionné au préalable était une « erreur ».
« C'était une façon de faire pour que tous les mots donnent immédiatement des résultats », avait expliqué son directeur général, Éric Léandri. Le but de la manœuvre était de profiter des requêtes des premiers utilisateurs pour établir des statistiques et affiner la recherche sémantique du moteur, puis de basculer progressivement vers des résultats maison, accompagnés de ceux de Bing et d'autres sources.
Bourrelly publiait dans la foulée sur son blog une (longue) interview d’Eric Léandri, en réponse à ces accusations. En commentaire, un certain Marc, de l’annuairefrancais.fr, le félicitait : « il semble évident que Qwant aura sa chance quand il aura scanné lui-même le web pour le comprendre à sa manière et en donner une meilleure essence sémantique que la concurrence, pour apporter de la nouveauté » (les passages en gras sont de l'auteur, NDLR) :
« Je n’ai pas osé croire, par logique, que l’on mette des millions d’euros sur la table pour une supercherie et un gros buzz ... et qu’il était probable que cet outil vienne à faire son propre crawl…»
Une idylle brisée
Six ans plus tard, Qwant est devenue la bête noire de Marc Longo qui, via son compte Twitter, @annuaire_fr, n’a eu de cesse, ces derniers mois, de témoigner de son dépit d’avoir été « trahi » : « On nous a pris vraiment pour des billes, je supporte pas ça... Voilà pourquoi je suis fâché contre Qwant », écrivait-il ainsi en mars dernier.
En mai 2016, Bourrelly annonçait que ses podcasts étaient désormais sponsorisés par Qwant, et y qualifiait Éric Léandri (qu’il interviewe régulièrement depuis) de « mon ami ». Advisor de Qwant depuis janvier 2018, il en est aussi et surtout le « spin doctor », traitant Longo de « gros mytho » et de « grand taré », qui aurait besoin de « soins psychiatriques », entre autres.
Les médias ayant l’heur de publier des articles ne se contentant pas d’encenser le moteur ont eux aussi droit à son courroux, de Libération, accusé de « mensonge et de manipulation », au Figaro, de « mauvais journalisme et #QwantBashing mal placé ».
Sur le fil consacré à Qwant du forum de WebRankInfo, site de référence en la matière, Marc Longo, sous le pseudo Longo600, commençait à exprimer des doutes en janvier 2016, le qualifiant de « très bon méta-moteur mais pas du tout un vrai moteur de recherche », tout en précisant : « Souhaitons-leur d'y arriver, si c'est réellement leur objectif ».
En mars 2017, le même n’en décidait pas moins de « mettre les pieds dans le plat » dans un fil censé « ouvrir une polémique » :
« 42 millions d'Euros d'argent public pour un méta-moteur basé sur des API, les politiques ont perdu la tête ou quoi ? Qwant en est toujours à fournir des résultats identiques à Bing (…) à la lettre près, au mot près et à la quantité près (49 résultats fournis par l’API de Bing) ».
Pour lui, la communication de Qwant relevait de la « supercherie » : « les journalistes et les pouvoirs publics se laissent "enfumer" ». À quoi Bourrelly répondait, sobrement, via des interviews vidéo de Léandri, qu’indexer le web prenait du temps : « N'oubliez pas que Qwant n'a que 3 ans. Un peu de patience ».
Dans la foulée, sur Twitter, Longo tentait d'alerter la #presse, @ccifrance, la @CaissedesDepots et l’@AssembleeNat, sans pour autant être entendu, ni relayé. À l’époque, Qwant ne prit même pas la peine de répondre à ses accusations – hormis celle, polie, de Bourrelly. Depuis, la guerre est consommée.
En novembre 2018, Qwant décidait en effet de lever une partie du voile entourant le fonctionnement de son Index. « C'est un projet dont nous parlons peu mais c'est pourtant notre plus grande ambition : créer une indexation du Web indépendante », précisait-il sur Twitter, tout en renvoyant à un billet de blog intitulé « Indexation du Web : où en est l’indépendance de Qwant ? », qui se voulait pédagogique :
« Lorsque l’on parle de moteurs de recherche, il y a encore beaucoup de confusion entre les méta-moteurs qui se contentent d’afficher des résultats fournis par d’autres dans une interface différente, et les moteurs de recherche indépendants qui indexent eux-mêmes le contenu du Web et disposent de leurs propres algorithmes de classement des résultats. Chez Qwant, nous avons pris le pari depuis le premier jour de créer un véritable moteur de recherche indépendant, en indexant nous-mêmes le Web et en mettant au point nos propres algorithmes ».
À l’en croire, « c’est extrêmement important pour garantir une souveraineté technologique européenne. Il était en effet anormal que notre connaissance du Web dépende d’un ou deux acteurs américains, qui décident pour 95 % des Européens de ce qui est pertinent pour leurs recherches, en imposant leur vision et leurs intérêts ».
Qwant disposait alors « dans ses serveurs de 20 milliards de pages Web indexées » : « chaque jour nos crawlers passent sur plus d’un milliard de pages pour en ajouter, supprimer celles qui n’existent plus, ou mettre à jour toutes les informations qui les concernent », ce qui donnait à Qwant « la plus grande capacité d’indexation en Europe ».
« Des dizaines de millions de sites sont ainsi présents dans notre index », qui n’aurait recours à Bing que « pour compléter les résultats de recherche sur lesquels nous n’avons pas une pertinence suffisante, et sur les images où les capacités de stockage sont très importantes ».
« Nous faisons évoluer chaque jour nos algorithmes », concluait Qwant. « La bascule vers l’indépendance totale se fait donc progressivement », même si c’est « difficile à voir d’un œil extérieur ! »
Lanceur d’alerte, ou concurrent ?
Les réponses à ce billet furent, de fait, dubitatives : « ce qui serait réellement transparent, ce serait de montrer, ou de créer un baromètre, indiquant où en est le moteur aujourd’hui en termes de dépendance (ou d’indépendance) de Qwant par rapport à Bing » rétorquait ainsi Olivier Andrieu, du site Abondance.com, source de référence en matière de moteurs de recherche.
« L’immense majorité des SEO pensent que vous utilisez Bing et que vous êtes “seulement” un méta-moteur », embrayait Olivier Duffez, de WebRankInfo.com, autre source faisant autorité en la matière, tout en déplorant l’absence d’indications « sur le crawler et encore moins sur l’algo ».
Sur Twitter, tous deux déploraient par ailleurs que Qwant ne répondait pas à leurs questions et commentaires (Eric Léandri a depuis répondu à Andrieu).
En mars, Marc Longo, venait ajouter son grain de sel : « Pour des spécialistes, le résultat que vous affichez laisse à penser que l’indépendance n’est pas là, que les dépenses sont assez astronomiques et orientées vers la communication et le lobbying ».
Dans la foulée, il décidait de mandater un huissier afin de vérifier la pertinence de l’index de Qwant. Et le constat fut, à l’en croire, accablant, à mesure que son index n’aurait pas (ou marginalement) été mis à jour depuis 2017 :
« En réalité, lorsque l’on tape MACRON dans Qwant Junior éducation (https://www.qwantjunior.com/?q=macron&t=education ), il n’y a que ce vieil index de 2017, « Macron a toutes les chances d’être élu », « macron un candidat aux présidentielles »... Si l’on a le malheur de cliquer sur le premier lien, la page n’existe même plus, on est renvoyé a l’accueil site consulté ! Le deuxième lien peut-être ? Non plus, retour a l’accueil... Le 3eme lien ? Pareil, la page n’existe plus. Où est la promesse de mise à jour quotidienne, des retraits des pages introuvables ? »
Sur la partie web (et non Junior) de Qwant, les profils Instagram et Facebook d’Emmanuel Macron indiquaient, par ailleurs, un nombre d’abonnés largement inférieur à ce dont ils disposaient en avril dernier, les résultats semblant là aussi dater de 2017. Les recherches aux mots-clefs Tour de France, motogp, festival de Cannes, grand prix F1 ou rentrée scolaire ne renvoyaient, de même, qu'à des pages datant de 2017, sans aucune mention des années 2018 et 2019.
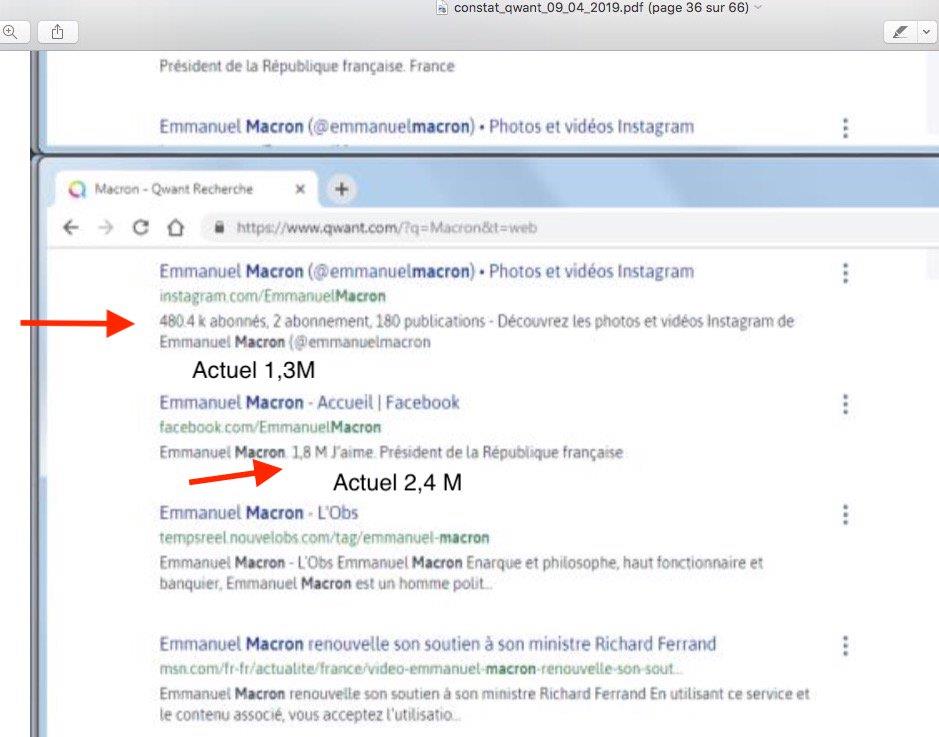
Aucune des pages indexées par Qwant (et donc non fournies par le moteur Bing de Microsoft) ne semblait avoir été mise à jour depuis 2017, et les liens étaient « soit périmés, soit répétitifs, les textes mal décodés, en résumé, inexploitables industriellement », déplorait Longo.
Mi-avril, Longo envoyait un courriel alarmiste et accusatoire à l’ensemble des parlementaires, comme l’avait révélé La Lettre A. Contacté par nos confrères, Qwant avait rétorqué que ce courrier contenait « de très nombreux éléments mensongers et diffamatoires », et qu’il allait engager les « procédures nécessaires ». En l’espèce, une assignation en justice.
Déplorant dans sa plainte une « campagne de dénigrement » qui se poursuivait par « des tweets quasi-quotidien », Qwant lui réclamait 15 000 euros par infraction constatée, 100 000 euros de dommages et intérêts, et 5 000 euros de frais de procédure, à mesure que le courriel envoyé aux parlementaires comportait des « indications trompeuses et dénigrantes », à commencer par un index « abandonné depuis 2017 », « ce qui est évidemment faux ».
Le 14 juin dernier, Marc Longo a en conséquence été condamné pour « dénigrement » en concurrence déloyale par le tribunal de commerce de Paris, à « cesser tout acte de dénigrement, sous quelque forme que ce soit et sous quelque support que ce soit, à l’encontre de la SAS Qwant et de son moteur de recherche », ainsi qu’à 2 000 euros de frais de procédure, mais sans dommages et intérêts.
Le conseil de Longo avait estimé que ses écrits relevaient de la liberté de parole, et que Qwant aurait donc dû l’attaquer pour « diffamation ». Mais le tribunal de commerce, suivant en cela la jurisprudence, ne fut pas de cet avis : « lorsque des propos litigieux ont pour objet de mettre en cause la qualité des prestations fournies par une entreprise et émanent d’une société concurrente exerçant dans le même secteur, ces propos relèvent d’une action en dénigrement et non d’une action en diffamation ».
Car Marc Longo a également lancé Premsgo.fr, un « moteur orienté marchand et e-commerce ». S’il ne cible pas les mêmes utilisateurs que Qwant, ne propose pas les mêmes fonctionnalités, ni ne boxe dans la même catégorie, il se présente comme « le seul moteur de recherche Français 100% indépendant et souverain anti-GAFAM ». Ce sur quoi repose précisément la communication de Qwant.
« La divulgation d’une information de nature à jeter le discrédit sur un concurrent constitue un dénigrement, peu important qu’elle soit exacte, l’exception de vérité n’étant pas admise en matière de dénigrement », estima dès lors le tribunal (nous avons surligné ces passages, NDLR).
Qwant visé par deux audits
Il convenait donc d’aller vérifier, a fortiori parce que Longo, qui a fait appel, a depuis été de nouveau assigné devant le juge de l’exécution du tribunal de grande instance de Paris, ce 22 juillet.
Qwant lui réclamait cette fois « une astreinte de 15 000 euros par infraction constatée afin d’assurer de façon effective l’exécution de cette décision », ainsi que la « condamnation solidaire de la société nouvelle l’Annuaire français et de Mr Longo à payer la somme de 10 000 euros à titre de dommages et intérêts ».
Il lui reprochait en effet d’avoir tweeté, à l’adresse des comptes du Sénat, de l’Assemblée, d’Emmanuel Macron, Cédric O et Matignon, un texte publié sur Linkedin suite à sa condamnation, intitulé « Quand la justice muselle les parlementaires d’accéder à l’information critique et avec elle la démocratie... », l’accusant de vouloir l’empêcher d’alerter le Parlement sur les carences supposées de Qwant.
De plus, Longo aurait également, d’après l’assignation, adressé un nouvel email à l’ensemble des parlementaires « critiquant violemment » Qwant, tout en continuant à « publier ou diffuser des tweets dérogatoires sur Qwant (...) se moquant totalement de la décision rendue par le Tribunal de commerce ».
À l’en croire, « ce dénigrement constant est extrêmement grave et de nature à décrédibiliser la société Qwant auprès du public et des pouvoirs publics, alors même que cette société poursuit des démarches afin de développer la fréquentation de son site, notamment auprès des administrations ».
Cédric O, secrétaire d’État au Numérique, avait en effet annoncé (.pdf), début mai, lors d’une table ronde du CEO Forum de VivaTech, que l’État avait choisi Qwant comme moteur de recherche pour ses administrations, suivant en cela de nombreuses entreprises et collectivités, et qu’il serait bientôt installé par défaut sur les postes de 2,5 millions de fonctionnaires.
Or, « malgré la volonté de l’Élysée d’avancer vite, le dossier Qwant suscite de nombreux doutes au sein de l’administration » révélait, début juillet, une enquête du Figaro. Au point que Cédric O a demandé deux audits à l’ANSSI et à la Direction interministérielle du numérique et du système d’information et de communication de l’État (DINSIC). Objectif : « vérifier ce qui se passe sous le capot de Qwant et s’assurer que l’entreprise progresse sur le plan technologique ».
« Nous déployons depuis quatre mois l’équivalent, selon nous, de la technologie de Google en 2016 », expliquait Éric Léandri au Figaro : « nous avons recours à Bing pour compléter nos résultats, et le déploiement de ces nouvelles technologies nous permettra à court terme d’assurer nous-mêmes 82 % des requêtes ». Qwant estimait alors pouvoir passer des 20 milliards de pages indexées à ce jour à 100 milliards de pages d’ici à la fin de l’année.
« L’État français y croit dur comme fer. La société fait l’objet d’un intérêt manifeste de l’Élysée, du gouvernement et de son bras armé, la CDC. Cette dernière a déjà investi près de 15 millions d’euros dans le projet début 2017 et s’apprête donc à suivre l’émission d’obligations convertibles », écrivait Le Figaro.
« Personne n’avait réussi à rafler le moindre point d’audience à Google depuis dix ans », précisait Éric Léandri, qui soupçonnait des « tentatives de déstabilisation de la concurrence et de la presse» : « Alors que nous préparons notre émission d’obligations convertibles pour accélérer, c’est comme par hasard maintenant que les attaques infondées convergent. »
Revenant de son côté sur le fait que Qwant serait « dépeint ici et là comme en faillite, une gabegie, un faux nez de Microsoft, une officine de l'État, un échec, une réussite suspecte... », Guillaume Champeau, directeur éthique et affaires juridiques de Qwant, relayait de son côté sur Twitter les conclusions d’un article de Challenges, qui se demandait d’où pourraient bien venir ce qu’il qualifiait d’« attaques grotesques et coordonnées » : « à mots couverts, certains administrateurs, comme l'entourage de Cédric O., secrétaire d'État en charge du Numérique, se demandent si le géant Google n'a pas décidé de se débarrasser du nain Qwant ».
Les (premières) explications de Qwant
Déplorant les attaques incessantes dont le moteur ferait l'objet, notamment de la part de Marc Longo (sans, pour autant, le citer), Tristan Nitot, vice-président Advocacy de Qwant, avait répliqué début juin par un post LinkedIn intitulé « Qwant : arrêtons la parano ! »
Dans un paragraphe intitulé « L’index date-t-il vraiment de 2017 ? », Nitot répondait : « Bien sûr que non, il est rafraîchi régulièrement. Par contre, lors du déploiement partiel d'un changement de stack logicielle au niveau de l'index, un fichier de cache contenant les résultats pour un ensemble de "top" requêtes datant de 2017 a pris la place du cache actuel pour ces requêtes. Dès que nous avons appris le problème, nous nous sommes employés à le comprendre et à le régler. Désormais, ces requêtes fonctionnent normalement. »
Seul « l'onglet "éducation" de Qwant Junior (1,2% des requêtes), qui fonctionne sur liste blanche, était bloqué sur un vieil index de 2017 » avait de son côté précisé, sur Twitter, Guillaume Champeau, quelques semaines plus tôt : « personne nous l'avait signalé jusque là puisque l'onglet est utilisé en classe pour des requêtes genre « orthographe », « addition », « gaulois », « dinosaures »... où a priori les contenus de 2019 ne révolutionnent pas la connaissance à avoir du sujet à l'école ; pour les contenus frais, la recherche par défaut («Web») ou spécialisée («actus») fonctionnait très bien, sur un index mis à jour chaque jour ».
Interrogé à ce sujet dans le n° de juin du Virus Informatique, Qwant expliqua : « c’est un bogue spécifique à l’onglet Éducation de Qwant Junior qui ne tape pas sur le même index que les autres et n’utilise pas les mêmes algorithmes. Fort heureusement, l’index de Qwant ne se résume pas à cet onglet de Qwant Junior ! »
Mais des recherches sur la page principale de Qwant étaient, elles aussi, « bloquées sur 2017 », selon le constat d’huissier consulté par le Virus, qui précisait : « Et, là, plus difficile d’avoir une explication officielle de la part de la société ». Un employé évoqua « un incident », suivi d’une « erreur » conduisant à « restaurer un index de 2017 sans s’en apercevoir ». « Un problème qui ne devrait être que ponctuel : l’index devant être recalculé en permanence », concluait le Virus.
D’autres employés évoquaient aussi « des changements en cours dans l’architecture matérielle et logicielle pouvant être à l’origine de dysfonctionnements temporaires », ainsi que « des bogues » pouvant « empêcher la régénération de certaines grappes de l’index ».
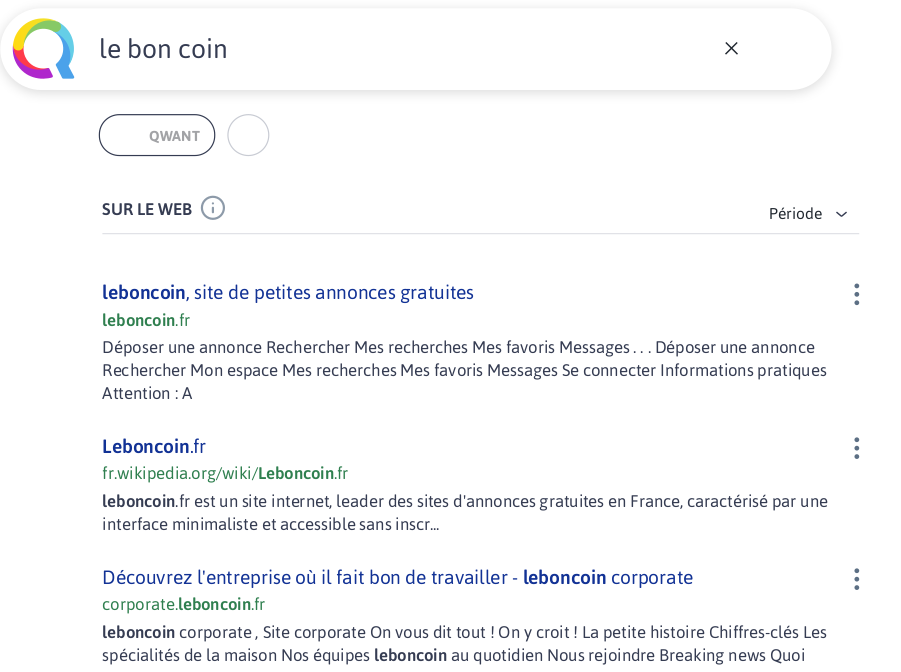
De fait, et « curieusement », écrivait le Virus, une recherche effectuée aux mots-clefs « le Bon Coin » (qui, d’après un employé de Qwant interrogé par le Virus, fait bien partie du corpus traité par son index, et n’émanant pas de Bing) renvoyait, à quelques heures d’intervalle, des résultats différents.
Après avoir affiché un compteur de J’aime de sa page Facebook « quasiment à jour », mais avec des résultats faisant « au mieux apparaître 2017, jamais 2018 ou 2019 », quelques heures plus tard, « les seules années qui apparaissent dans les résultats sont 2013 et 2014, et le compteur Facebook de la page Leboncoin est revenu en arrière (de deux ans ?), identique à celui figurant dans le constat d’huissier réalisé deux semaines plus tôt », soit « 359 373 J’aime ».
Mi-juillet, soit trois mois après que Marc Longo avait commencé à pointer du doigt l'âge de l'index de Qwant, et un mois et-demi après le même constat par Le Virus, ladite requête indiquait toujours que Facebook avait « 359 373 J’aime », alors qu’il en dénombre pourtant plus de 500 000.

De plus, la description enregistrée par Qwant de la page Le Bon coin sur Wikipédia (« leboncoin.fr est un site internet, leader des sites d'annonces gratuites en France, caractérisé par une interface minimaliste »), était celle en vigueur du 5 janvier 2013 au 15 août 2017. À défaut de savoir pourquoi elle n’aurait pas été mise à jour depuis, son indexation par Qwant datait donc a priori, et au plus tard, du premier semestre 2017.
Vérification faite, ce 31 juillet, deux jours avant la publication de notre article (et alors que nous avions posé nos questions à Qwant il y a près de 15 jours), son Index a de nouveau été (re)mis à jour : Facebook y affiche « 494k likes », soit 5 000 de moins que ce qu’il comptait le 10 juillet.
Et la description du Bon Coin sur Wikipédia, telle que présentée par Qwant (« Le Bon Coin, ou leboncoin.fr, est un site web d'annonces commerciales, fondé en France, durant l'année 2006, à l'initiative du conglomérat norvégien »), avait été introduite le 9 février de cette année, avant d’être de nouveau modifiée le 18 juin dernier.
La pertinence – et la véracité – des accusations de Marc Longo restaient donc, à l’aune des explications de Qwant, à « fact-checker ». Ce qui sera l'objet de la suite de notre enquête, avec les (nouvelles) explications de Qwant, aussi : Qwant : des résultats datés, limités (mais répétés).

























Commentaires (91)
#1
Ca fait quand meme beaucoup de casseroles, et aucune transparence, si ce n’est a posteriori des accusations …
#2
Longo l’a mauvaise et il le fait savoir assez largement et violemment… ça le dessert et ça dessert ses alertes, c’est dommage alors qu’il n’a pas vraiment tort dans le fond.
#3
Ça sent quand même bizarre cette histoire…
#4
C’est un peu étrange, d’avoir des concepts de dénigrement et de diffamation qui s’appliquent même si la personne a dit la vérité…
Protéger l’honneur et la réputation d’une personne ou une entreprise face à l’utilisation d’informations exactes, c’est une vision très minimaliste de la liberté d’expression.
#5
Ouais, c’est pas reluisant tout ça.
J’ai du mal à soutenir Longo qui a une comm souvent désagréable, et qui en tant que concurrent a des intérêts autres que la transparence et l’éthique pures, mais l’article rétablit pas mal la balance.
C’est quand même bizarre de dire “Non, notre truc marche bien, mais ça n’apparaît pas parce qu’il y a des bugs”. Malheureusement ce n’est pas l’intention qui compte. Si ça recrache du 2017, ça recrache du 2017. Même s’il y a quelque part sur les serveurs des données fraîches et propres.
Je vais suivre avec attention, j’aimerai retrouver les a priori favorables que j’avais sur Qwant.
#6
Je crois que le problème est que c’est un “concurrent” donc supposément ( aux yeux de la loi ), tu ne dénigre pas dans l’Intérêt du grand public, mais pour un intérêt commercial/pécunié .
Il aurait fallut qu’il prenne contact avec un journal, qui aurait lui même vérifié les fait etc, là il l’as fait en son nom en tant que “concurrent”
mais on est d’accord que ça parait bizarre comme loi à premiere vue
#7
#8
Il me semble que cela ne s’applique que parce qu’il est en situation de concurrence. C’est le même principe qui interdit dans une publicité à une marque de se comparer à une autre (en citant son nom). C’est l’intention de nuire qui est jugé, pas la vérité.
#9
Merci pour cet article très intéressant.
J’ai personnellement perdu confiance dans Qwant et j’attends maintenant de voir de vrais résultats montrant qu’ils font un travail de moteur de recherche.
#10
J’ai essayé d’utiliser par défaut Qwant pendant plusieurs semaines.
J’ai abandonné il y quelques jours (retour à Google) , les résultats de mes demandes de recherches n’étaient pas vraiment pertinents. Pire je le suis retrouvé plusieurs fois avec 0 réponses…
A+
#11
Merci pour l’article. Ça fait du bien un peu de retracer l’historique de Qwant.
Je n’étais pas au courant de tous ces déboires. Visiblement ils ont dû passer plus de temps à travailler en interne sans trop vérifier l’état du moteur. En même temps, quand il n’y a pas d’utilisateurs, il n’y a pas de retour…
#12
Je n’utilise pas Qwant et ce pour les raisons expliquées en début d’article. Quand c’est flou c’est qu’il y’a un un loup. Et qwant est flou depuis le début et c’est bien dommage, pour une fois qu’on aurait pu avoir un (presque) géant français à la matiere.
Très bon article, très précis qui compulse bien tous les tours et détours de l’histoire. Et ce n’est pas fini.
Reste que je ne comprends pas comment/pourquoi Tristant Nito et Guillaume Champeau ont bien pu se retrouver embarqués dans ce machin là… du coup ils rament comme des bêtes pour faire le SAV et les pompiers de services, exactement de la même manière que les politiques rament aux milieux des affaires, en utilisant les même méthodes réthoriques. Du coup ça casse leur image issu de la Mozilla fondation pour le premier ou de numerama pour le second.
#13
« Nous déployons depuis quatre mois l’équivalent, selon nous, de la technologie de Google en 2016 », expliquait Éric Léandri au Figaro .
 " />
" />
Mais bien sûr…
#14
Cher Boogieplayer,
Je ne vais pas parler pour Tristan mais en ce qui me concerne je suis très heureux d’être chez Qwant tout simplement parce que je sais quelle est la réalité de l’intérieur, et je me battrai aussi fort que possible pour la défendre. Je suis super étonné, pour pas dire plus, que Jean-Marc que j’apprécie et respecte beaucoup ait préféré faire un “fact-check” à distance depuis son navigateur de ce qui est dit sur Qwant, plutôt que de venir discuter avec nos chercheurs et ingénieurs pour constater in situ ce qu’il en est vraiment, comme il a été invité à le faire.
Mais ça fait un point commun avec Marc Longo qui effectivement a été condamné pour après des mois de dénigrement continu (qui ne cesse pas, d’où le recours au juge de l’exécution) et de refus de venir voir ce qu’on fait. Tous ceux qui viennent, bizarrement, n’ont plus aucun doute s’ils en avaient.
Amicalement,
Guillaume
#15
#16
#17
…l’exception de vérité n’étant pas admise en matière de dénigrement…
Ou quant la loi interdit de dire la vérité ! Faut pas s’étonner que les mensonges prolifèrent ensuite…
#18
Bonjour Guillaume,
comme je vous l’ai déjà expliqué à Tristan et toi par e-mail, j’ai décliné l’invitation parce que mon enquête porte sur le “moteur de recherche”, pas la “start-up”, et que ceux qui utilisent Qwant le font depuis leurs ordinateurs, pas depuis vos locaux.
Par ailleurs, on vous a aussi laissé 15 jours pour nous répondre, et vous n’avez pas répondu à toutes nos questions, malgré plusieurs relances. C’est gentil de m’inviter, mais ce que je voulais, c’était des réponses.
Et je ne vois pas ce que cela aurait changé que je vienne prendre un café, ou que vous me montriez vos serveurs : ce qui compte, ce sont les résultats du moteur de recherche, et les réponses à nos questions.
Accessoirement, mon enquête (avec la 2e partie, à venir) fait donc plus de 50 000 signes : ça m’a aussi pris “beaucoup” de temps.
Sincèrement
@manhack
#19
#20
#21
#22
#23
Dans un procès, l’accusation débute, la défense conclue les débats.
#24
#25
#26
C’est sûr que l’article ne fait pas bonne Pub à Qwant.
Je ne comprends pas pourquoi ils ne montrent pas patte blanche avec du concret pour le coup. Ce serait tellement plus simple… Et ca leur serai tellement bénéfique. Alors que laisser planer le doute avec des discours faire l’effet inverse.
Après, que Bing ait des résultats de merde en France par rapport à GG c’est un fait…. Que Qwant en ait avec ou sans Bing, idem… Tu ne vas pas rattraper la pertinence et la puissance d’un monstre comme Google en 3-5 ans.
#27
Bonjours Gchampeau. j’en profite que vous soyer là pour vous poser une question. Car il me semble que dans tous les accusations sur Qwant. Rien na était dit sur les accusations comme quoi la Cnill avait jugé que les technologies d’anonymisation de Qwant n’était pas suffisant en 2015.
Sourcehttps://www.developpez.com/actu/268567/Qwant-enquete-sur-les-deboires-du-Google-…
“ Le comble, c’est qu’en 2015, la CNIL avait signifié à Qwant lors d’un contrôle que ses mesures d’anonymisation n’étaient pas suffisantes. Si l’entreprise affirme s’être améliorée depuis, aucun régulateur ou tiers certificateur n’est en mesure de l’attester. ”
Peut t’être que next impact en parlera dans la 2eme parti, mais j’avoue que cela m’intrigue.
Cordialement
#28
Article très intéressant et bien documenté merci bien.
Au final, tout à vérifier (mode parano : Qwant nous roule, mode parano bis : des gens cherchent à couler Qwant, bouh Google)…
#29
Vous avez regardé si le crawler de Qwant passait régulièrement sur Next Inpact ?
#30
Ça tourne à la foire d’empoigne ici.
#31
Victoire à la pyrrhus pour qwant et au regard de la jurisprudence, si les critiques portent sur des éléments objectifs je doute que la cour confirme le jugement.
Dans tous les cas cet article est très intéressant et me permet de confirmer mes sérieux doutes sur qwant que j’ai plus vu mentionné dans les anti-chambres du pourvoir qu’utilisé sur les navigateurs…
#32
Guillaume, toi et moi, on se connait depuis longtemps, on a participé aux même combats pour les même causes et pour les même destinations. On a même partagé des écrits ensemble.
Je reste donc étonné que tu aies rejoint Qwant, mais c’est de mon point de vue, c’est à dire que je ne suis pas à ta place, j’observe simplement ce qui s’écrit et se prouve petit à petit au sujet de Qwant. Et je trouve que cela ne te ressemble pas, surtout avec ton talent d’écriture et d’analyse je te voyais ailleurs. Je respecte ton choix évidemment, qui suis-je pour le juger ? simplement je m’en étonne car je continue de penser que cela risque de te porter préjudice en terme d’image numérique (si je peux utiliser ce terme) cela ne change pas l’estime que j’ai pour toi évidemment.
Quant à Trisant pour l’avoir rencontrer souvent à l’époque de la Mozilla Fundation, j’avais compris le choix de Cozy Cloud. Là je ne le comprend pas.
J’espère de tout coeur que tout ce que vous avez pu écrire et dire pour “”“défendre”“” Qwant ne va pas vous revenir en boomerang plus tard.
Amicalement,
#33
#34
Qwant ça veux pas, ça veux pas " /> De toute façon, qui utilise Qwant, à part les geek et les barbus libriste
" /> De toute façon, qui utilise Qwant, à part les geek et les barbus libriste  " /> ?
" /> ?
 " />
" />
Rien de mieux que DuckDuckGo, c’est aussi précis que Google, Search, mais sans les pubs…enfin, il parait, mais j’ai pas été voir sous les plumes du canard
#35
Combien de millions issus de financements publics Qwant sera-t-il en droit de flamber avant de rendre des comptes?
Les audits de Qwant demandés à l’ANSII et à la DINSIC démontrent bien que personne ne sait vraiment si cette boîte respecte ses engagements : “créer un véritable moteur de recherche indépendant, en indexant nous-mêmes le Web et en mettant au point nos propres algorithmes, qui permettent de vous fournir l’information la plus pertinente sans avoir à collecter vos données personnelles.”
#36
Pourquoi personne ne parle de Duck Duck Go, ici ?
#37
peut-être parce-que le sujet est un imbroglio sur Qwant, pas un comparatif de moteurs de recherche…?
#38
#39
De toute facon pour moi Qwant c’est complètement flou depuis des années, j’avais posé la meme question quand a la sécurité des données a tous les moteurs connu a l’époque.
(A propos de TLS 1.3 et DNSSEC).
Ils m’ont tous répondu entre (le jour meme et un mois plus tard).
Sauf qwant, dont je n’ai jamais recu de réponse a ma question.
Donc si votre moteur marche bien en interne tant mieux pour vous, mais nous on externe on attend des résultats.
On les a pas donc on ne viens pas.
Fin de l’histoire.
Edit : Je ne parle que de mon avis personnel basé sur une expérience personnel libre a vous de ne pas me croire
#40
#41
#42
Utilisant avec satisfaction Qwant pour 90% de mes recherches, je ne vois pas dans cet article de raison de changer de crémerie.
Par contre, j’y vois pas mal de raisons de cesser d’en faire la promotion.
Merci pour ce super article. Ravi de financer ce média.
#43
#44
#45
C’est des accusations fortes ce que tu dis. Soit Tristan Nitot et Guillaume Champeau sont malhonnêtes, soit ils sont pas suffisamment compétents pour se rendre compte de l’intérieur que Qwant ment sur sa technologie. Tu parles de preuves : sur quelles preuves te bases-tu pour accuser ces deux personnes, pour qui tu dis avoir de l’estime par ailleurs ?
#46
T’enflamme Pas toi.
Il n’accuses personne.
Il dit que de son point de vue extérieur il ne comprend pas le choix de ces personnes qu’il a déjà côtoyé auparavant.
C’est tout.
Et pour adorer Numerama sous Guillaume, je rejoins son point de vue.
Mais j’attends.
Je leur laisse le bénéfice du doute, vue leur expérience, ça doit être plus compliqué que ça en a l’air de tout balancer.
#47
En fait, Qwant, ça fonctionne. Il suffit juste de faire un reportage sur eux, et ils mettent les mots clés cités dans l’article à jour…
 " />
" />
#48
#49
#50
Ouais il faudrait un audit de toutes les dépenses publiques dont le CICE. Mais cela n’empêche pas de demander des comptes à Qwant.
#51
https://lite.qwant.com/?q=qwant%20site%3Anextinpact.com&t=news
https://lite.qwant.com/?q=qwant+site%3Anextinpact.com&t=web
Ça va, l’index est plutôt à jour quand même.
Moi, j’aime bien cet article. Et je vais continuer à utiliser Qwant, parce ce n’est pas parfait, mais je n’ai pas mieux. Le but n’est pas de taper sur Qwant, mais de poser des questions pour leur demander de faire mieux, pas de fermer la boutique.
#52
Tu as recherché Qwant sur Qwant ?!
Mon Dieu il va péter Internet !
#53
#54
#55
#56
Quand même, toute cette histoire avec ces interrogations…
Je me disais qu’avec Nitot et Guillaume , ça devrait le faire.
Mais pourquoi ça coince?
C’est pas clair.
« Quand c’est flou, c’est qu’il y a un loup »
Allez @ManHack!!! Trouve nous la baleine sous les gravillons!
Le fin mot de l’histoire.
Nxi, le Mediapart du numérique!!! Lol
#57
Parce que ma navigation commence souvent par une recherche, mon navigateur, Firefox sur tous mes appareils, a un moteur de recherche comme page d’ouverture.
J’ai choisi Qwant, qui est aussi le moteur de recherche par défaut: depuis que la barre de recherche n’est plus distincte de la barre de navigation, il arrive que quand j’entre une URL incomplète, il n’y ait pas complétion à partir de mon historique mais que j’aie le retour d’une recherche. Ce comportement a bien évidemment été décidé par ceux qui commercialisent à la fois un OS et nos données personnelles issues notamment de nos recherches. En utilisant Qwant, c’est autant de données inutilement envoyées à Google ou Microsoft.
J’utilise donc Qwant au quotidien, mais je dois bien dire que c’est avec un esprit militant. Je suis satisfait globalement des résultats quand mes requêtes concernent tout ce qui n’est pas professionnel. Dès que je dois faire des recherches techniques, si j’ai le temps, je tente avec Qwant, sinon je fais tout de suite le choix de Google qui sera aussi ma solution si je ne suis pas satisfait de Qwant. Dans bien des cas j’ai besoin d’informations très récentes, l’indexation de Google fait la différence.
En terme d’ergonomie, la page d’accueil est tout simplement à vomir, bien trop lourde. Un autre commentateur rappelait que ce qui a fait aussi le succès de Google c’est la sobriété de l’accueil, chargement immédiat. Les contraintes de poids de pages sont moins fortes aujourd’hui, mais cette page est lourde (et très moche mais ce n’est que mon goût), chargée de composants qui me sont totalement inutiles, ou tellement mal présentés que je n’en comprends pas l’utilité.
#58
#59
#60
#61
En tout cas heureusement que NXI n’a plus de comparateur de prix, sinon, ils auraient pu être attaqués eux aussi pour dénigrement ! " />
" />
#62
Si seulement on obligeait les serveurs à s’équiper d’un logiciel permettant de renvoyer des requêtes, cela simplifierait considérablement le travail des moteurs qui n’auraient plus besoin de scanner tout le web…
Mais peut-être que ça existe déjà, non ?
#63
Merci pour l’article et vivement la suite.
Cela permettra de peut-être avoir quelques réponses ou au moins des explications qui sont demandées depuis maintenant quelques années.
#64
Oups, désolé, j’avais omis de rajouter le lien vers la 2e partie de mon enquête : Qwant : des résultats datés, limités (mais répétés)
#65
J’ai en effet lu trop vite ton commentaire et surinterprété tes propos. Toutes mes excuses.
#66
Accessoirement, c’était pas la seule chose qui a été dite par le concurrent condamné. L’article a fait le choix de faire un focus là dessus, mais dans les faits, il suffit de parcourir son twitter pour voir qu’il y a de tout. “Qwant c’est que Bing en fait”, “Qwant ne préserve pas la vie privée”, etc. etc.
Il y a pas mal d’incohérences dans les attaques. Comment un index peut dater de 2017 tout en étant en fait qu’un call API vers Bing ?
Le problème est que les rumeurs restent et que le temps que l’inverse soit démontré, une autre polémique est lancé.
#67
Les réponses sont donnés depuis longtemps. Mais elles ne vont pas dans le sens des accusations et sont donc ignorés.
#68
#69
Objectif : « vérifier ce qui se passe sous le capot de Qwant et s’assurer que l’entreprise progresse sur le plan technologique ».”
Ça ne sent pas bon du tout chez Qwant.
Je crains vraiment que les salaires de la honte prennent la place des beaux discours technologiques à l’issue des audits.
#70
Moi je vois tout à fait : on peut toujours trouver le petit truc kivapabien chez le concurrent, et communiquer de manière orientée dessus.
On (en tous cas moi) se plaint déjà que les réseaux sociaux ne soient bien souvent que des déversoirs de haine et de colère, si la communication business pouvait l’être, le marigot serait encore plus nauséabond…
Alors ça me va très bien que la pub comparative ne soit pas trop possible en France. Elle l’est, mais très très très encadrée, ce qui explique qu’elle soit ultra-discrète.
Dans les exemples : à Carrefour-Bonneveine, au rayon fruits et légumes, parfois un “ici la tomate/banane/pomme est à X.XX€/kg contre Y.YY€/kg à Leclerc Sormiou”. Et ça reste très discret. Probablement parce qu’une guerre n’apporterait rien de bon, chaque magasin a des produits moins chers et d’autres plus chers…
#71
#72
C’est typiquement le genre de déclaration qui les décrédibilise totalement… pourtant je suis utilisateur de qwant
#73
Article très intéressant, les conclusions de tout ça risque de changer pas mal de choses.
J’espère sincerement que Qwant n’est pas juste de la poudre aux yeux.
en termes d’expériences personnelles, l’utilisant régulièrement je n’ai pas vraiment à me plaindre, j’arrive très souvent à ce que je recherche et passe par des alternatives lorque ce n’est pas le cas.
J’ai constaté des améliorations de pertinances dans mes recherches ainsi qu’une amélioration de la stabilité du service au cours de mon utilisation. Pour ce qui est de la fraicheur de l’index je n’ai pas vérifier.
Un peu de transparence ferait effectivement du bien à tout le monde dans cette histoire, surtout que comme ça a été dit, on n’attend pas de Qwant qu’il soit aussi éfficace que google, simplement un service qui satisfait à ses propres déclarations et engagements.
#74
#75
C’est vrai que l’auteur de l’article n’a aucune légitimité et ne connaît pas le sujet ! Aller voir l’équipe n’aurait rien apporté, on a eu le discours officiel ici et il est assez affligeant !
Merci d’avoir apporté vos lumières.
Avez-vous un lien quelconque avec Qwant ? Votre pseudo est assez étrange et semble professsionel.
#76
#77
Merci pour cet article
 " />
" />
Un vrai travail de journaliste
#78
#79
#80
Sérieusement, quand tu n’as plus d’eau courante ou que ta voiture ne démarre plus, ça change quelque chose de rencontrer l’ingénieur en méca des fluides ou l’ouvrier de chez Peugeot?
Ils ont beau être compétents et volontaires, t’as pas d’eau et ta voiture reste au garage.
Ça serait différent si l’article parlait de problèmes de management ou de recrutement (par exemple) au sein de la boîte.
#81
Remettre en cause l’impartialité d’un journaliste comme Jean-Marc Manach qui a rédigé deux articles de qualité en dit long sur votre argumentaire. En l’espèce l’enquête portait sur les résultats fournis par l’outil de recherche Qwant, entreprise qui aurait coulée sans les subventions publiques. Et malheureusement, les conclusions de cette enquête ne sont pas élogieuses.
#82
Tu associes une volonté à un bug. Ils auront beau être aussi transparent que possible, si tu es convaincu qu’ils sont malhonnête, tu trouveras toujours quelquechose qui peut paraître louche.
#83
D’autres vous ont déjà répondu, mais oui, par rapport à ces 2 articles, rencontrer l’équipe n’aurait rien apporté.
Ils auraient expliqué que si, ils indexent bien le WEB en partie (et je veux bien le croire) et que les recherches les moins courantes remontent bien des réponses récentes et le prouvent donc. Mais le problème est que cet index récent n’est pas utilisé pour les requêtes les plus fréquentes et les plus simples pour une histoire de cache périmé utilisé afin de diminuer les ressources utilisées.
On a donc bien compris que qwant a à la fois un problème de ressources pour indexer tout le WEB (et on le savait déjà : c’est pour cela qu’ils ont annoncé utiliser azure pour accélérer leur indexation) et en plus un problème de mise à jour (ou invalidation, au choix) de son cache ce qui fait que certaines réponses sont périmées.
On a aussi compris qu’ils ont d’autres bugs, comme celui qui fait que les réponses sont répétées, ce qui me fait m’interroger sur leur politique de test.
Un cache, c’est un concept important en informatique et c’est très utile pour améliorer les performances et diminuer la consommation de ressources, mais, c’est la première fois que j’entends parler d’un cache aussi vieux surtout quand il s’agit de traiter le WEB qui bouge tout le temps.
Un troisième article qui pourra expliquer pourquoi qwant en est là et comment et quand ils comptent en sortir peut être intéressant et là, oui, il faudrait rencontrer les équipes, mais pas seulement le management et la communication mais aussi celles qui développent et qui gèrent l’exploitation.
Sinon, pourquoi avoir ignoré ma dernière question dans le message auquel vous répondez ?
#84
#85
Je n’ai pas “refusé” d’aller les rencontrer : je leur ai demandé, au préalable, de répondre à nos questions; or, les dernières réponses ne me sont parvenues qu’après la parution du premier volet de mon enquête…
#86
La publicité comparative n’est pas interdite, elle a même été assouplie en 2001. J’en veux pour preuve la surprenante publicité comparative pour la purée Vico en 2003, où ils expliquaient que la purée Mousline contenait des ingrédients chimiques alors que la leur était composée à 100% de pomme de terre, mais la comparaison s’arrête là. Note donc qu’ils se gardaient bien de dire que leur purée est meilleure (ils se contentaient de confirmer qu’elle a bon goût, sans commenter sur celui de la Mousline), même si c’est bien le sous-entendu de la comparaison (en plus du sous-entendu “produits chimiques = caca-boudin pour dedans ton corps”). Ainsi, Mousline ne peut pas attaquer Vico pour dénigrement, puisque la comparaison dans le spot s’en tient aux faits.
C’est un des rares exemples où la publicité comparative avait un impact réel (Vico se pose en David contre le géant leader du marché Mousline-Goliath). La raison pour laquelle il-y-a très peu de publicité comparative en France est parce qu’en général c’est quand même un gros potentiel d’emmerdes pour un impact souvent très limité voire contreproductif, comme expliqué dans cet article des Échos intitulé La publicité comparative effraie les marques françaises. Et vu le contenu de l’article, je suis bien content d’avoir raté la période des comparaisons entre les supermarchés à la fin des années 2000 !
Pour en revenir à notre cas, le monsieur est très virulent et y va de son commentaire, ce qui fait que ce n’est pas une simple comparaison mais bien un dénigrement (certes fondé, mais quand même bien relou) de son concurrent.
#87
#88
Pour en savoir plus sur lui.
Numérama était plutôt pas mal avant qu’il ne le vende. Mais un journaliste fait rarement un bon communicant pour une entreprise ou en politique.
Ce qui me chagrine est qu’il est Directeur Ethique et Affaires Juridiques. Il n’y a aucune éthique à attaquer ainsi Jean-Marc Manach qui est quelqu’un de respectable et ne mérite pas cet amalgame. En fait, comme il l’explique il est un communicant pour Qwant : “De leur côté, ils cherchaient un communicant, avec des besoins juridiques croissants”.
L’éthique, le juridique et la communication sont des sujets qui devraient être traités par des personnes différentes.
#89
#90
Ca aurai peut être éviter pas mal de procès d’intention
#91
Pour la n-ième fois : non content de leur avoir laissé 15 jours, “à leur demande”, pour nous répondre (alors que d’ordinaire c’est 24/48h), ils n’ont fini de me répondre qu’“après” la parution du 1er volet de mon enquête, alors que, et nos échanges de mails (publiés par Qwant avec notre accord) le démontrent : j’avais accepté leur “invitation” (sous la pression de Léandri) “à condition” qu’ils répondent à nos questions.
Ils ne l’ont pas fait, et d’aucuns me reprochent aujourd’hui qu’ils n’ont donc pas respecté les termes du deal qu’on avait donc conclu (nonobstant le fait que les utilisateurs de Qwant le sont devant leurs propres ordis pro/perso, pas depuis les bureaux de Qwant, et que le pb avait été rendu public fin.. avril).