

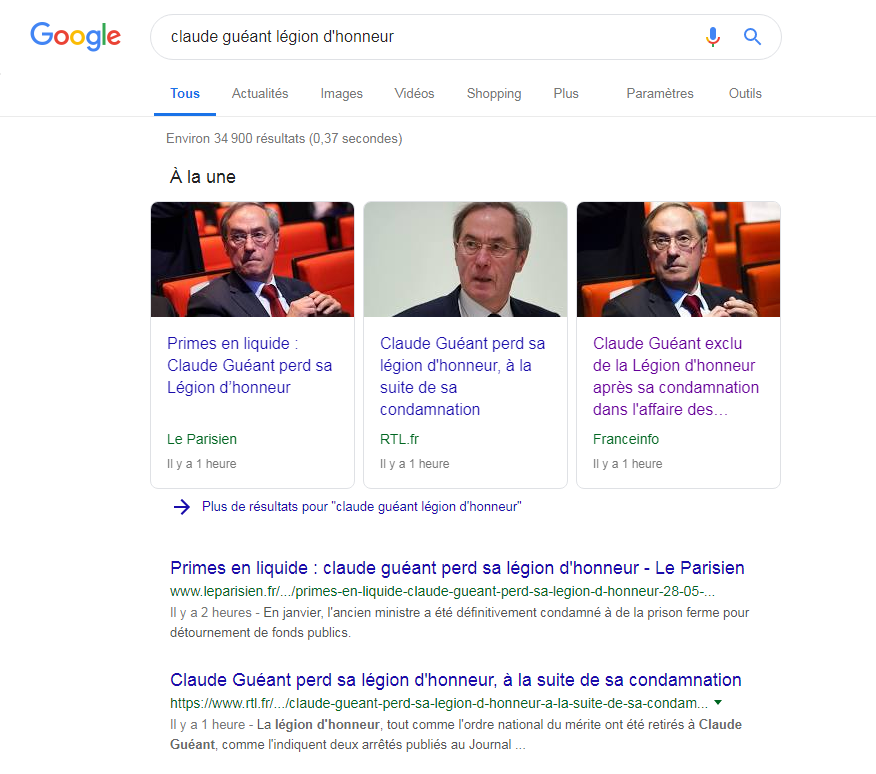
Au Journal officiel, deux arrêtés retirent la Légion d’honneur et l’Ordre national du Mérite à Claude Guéant. Des mesures ont été prises pour que Google et les autres ne puissent indexer ces données nominatives. Par contre, les mêmes moteurs peuvent indexer tous les articles qui citent le nom de l'intéressé.
Deux arrêtés ont été publiés au Journal officiel ce matin. Ils consacrent le retrait de ces deux décorations accrochées au veston de cette personne condamnée dans l'affaire des primes en liquide du ministère de l'Intérieur (premier arrêté, second arrêté).
Une précision a été apportée dans ces deux textes : ils ne peuvent faire l'objet d'un référencement par les moteurs. Pourquoi cette pudeur ? Conformément à l’article L221-14 du Code des relations entre le public et l’administration, certains actes individuels relatifs à l'état des personnes, « doivent être publiés dans des conditions garantissant qu'ils ne font pas l'objet d'une indexation par des moteurs de recherche ».
Et en application cette fois de l’article R221-15 du même code, parmi ces actes, figurent les textes prononçant l'exclusion ou la suspension « de l'ordre de la Légion d'honneur » ou de « l'ordre national du Mérite ».
Une indexation automatique interdite
Cette législation avait été intégrée à l’occasion des débats autour de la loi sur la dématérialisation du Journal officiel, de décembre 2015. Elle est donc antérieure au règlement général sur la protection des données personnelles.
À l’époque, Clotilde Valter, secrétaire d’État chargée de la réforme de l’État et de la simplification en avait justifié le sens : « s’agissant de la protection des informations nominatives et personnelles, les données relatives à l’état et à la nationalité des personnes feront l’objet d’un traitement spécifique, qui empêchera leur indexation automatique par des moteurs de recherche ».
« En pratique, détaillait le rapport parlementaire édité pour l’occasion, l’accès aux textes contenant des informations nominatives se fera uniquement à partir d’un sommaire du Journal officiel de la République française sur le site de Légifrance ». Ainsi, « les textes contenant les informations nominatives seront présents dans le sommaire au même titre que les autres, un système de protection par « Captcha » permettant de distinguer une utilisation humaine de l’accès par robot ».
Après vérification, on apprend en quelques clics que celui concerné par ces retraits est Claude Guéant. Le fait est que cette législation ne vise que les traitements de données personnelles réalisées au sein du Journal officiel, pas au-delà.
Voilà pourquoi, Google, Bing ou Qwant n’indexent pas les deux arrêtés dans leur intégralité, en stricte conformité avec ces dispositions. Par contre, ces mêmes moteurs ne se gênent pas pour indexer tous les articles qui en parlent, ces sites n'étant pas concernés par ces restrictions spécifiques. Sur le terrain du RGPD, la mise en balance entre la protection des données personnelles et le droit à l’information devrait pour le coup jouer en faveur de ce dernier


























Commentaires (25)
#1
Ils ont découvert robots.txt ou ils ont fait une assignation ou assimilé pour demander à google de le faire tout seul ?
#2
#3
J’ai pas compris à quel niveau se situe l’utilisation du captcha.
Le captcha protège l’accès au contenu intégral de l’arrêté ?
Ou bien le captcha protège le sommaire du Journal officiel de la République française.
Est-ce que c’est un sommaire particulier créé pour l’occasion ou bien LE sommaire ?
Il y aurait quoi dans robots.txt ?
Disallow: sommaire.html
Disallow: arreteGueant.pdf
Mais du coup, si les arrêtés ne sont recensés que via sommaire.html comment les robots sont censés trouver arreteTartempion.pdf s’ils ne peuvent pas crawler sommaire.html
Sinon je serai curieux de savoir si quelqu’un du métier pratique la protection par captcha pour des arrêtés sensibles (nominatifs) ou bien si vous vous contentez de ne pas publier sur internet en indiquant une possibilité de consultation en mairie.
#4
J’ai quand même du mal à me dire qu’un moteur de recherche ne peut pas résoudre une équation comme :
 " />
" />
“ 7 + ?? = 16”
Ce captcha est plus une interdiction de tenter la résolution, que la difficulté à le faire.
Mais au moins, Legifrance n’utilise pas cette daube de recaptcha de Google, qui nous fait bosser gratuitement…
#5
#6
tu peux lire ici, si tu avais raté l’info à l’époque " />
" />
Il me semble entre autres que les IA basées sur les réseaux de neurones sont très mauvaises pour “comprendre” une question du type : 1+1+1+1+1+1=?
#7
Il fut un temps ou mettre à l’index voulait dire mettre les méchants ( ou les bouquins prohibés) dans une liste
 " />
" />
Maintenant c’est tout le contraire , on n’a plus le droit de les mettre à l’index
#8
Le Captcha sur le JOFR est présenté au moment d’accéder au contenu du décret.
le fait de cliquer sur “accéder à l’espace protégé” affiche le captcha
il est écris “En application de l’article L. 221-14, et des articles R. 221-15 et R. 221-16 pris après avis de la CNIL, du code des relations entre le public et l’administration, les actes individuels relatifs à l’état et à la nationalité des personnes ne peuvent être publiés au Journal officiel de la République française, que dans des conditions garantissant qu’ils ne font pas l’objet d’une indexation par des moteurs de recherche. Les actes concernés sont accessibles sur le site Légifrance en cliquant sur le lien ci-dessous :
https://www.legifrance.gouv.fr/affichTexte.do;jsessionid=FC113D675959C20642E3DF4A4CB9BAC3.tplgfr33s_3?cidTexte=JORFTEXT000038510003&dateTexte=&oldAction=rechJO&categorieLien=id&idJO=JORFCONT000038509996
#9
Et maintenant, tout le monde est au courant de Guéant privé de déco " />
" />
#10
#11
Bah vu le nombre d’articles à ce sujet, c’est déjà le cas.
David soulève l’ironie de demander à un moteur de faire ça alors que des humains l’ont écris partout en libre accès. Les joies des lois mal écrites.
#12
Tout le monde parle du premier cas, un peu du deuxième cas mais qui parlera du dixième cas?
#13
Dans l’idée protéger le Journal officiel d’indexation c’est une bonne chose.
Vouloir protéger Guéant …. Mmmm je vais me taire et regarder la suite de Balkany …
#14
D’un autre coté, il est un peu vieux pour recevoir une médaille.
#15
L’intérêt de cette loi parfaitement bien écrite, c’est que quand c’est Jean Dupont qui est concerné, ça n’intéresse pas la presse et ça n’apparait donc pas dans les moteurs de recherche, la vie privée de Jeannot est préservée, tout va bien.
Dans le cas des personnes publiques, ça relève du droit à l’information, c’est publié dans la presse et donc accessible dans les moteurs de recherche, tout va bien.
#16
Je trouve cela très étonnant.
#17
Sur l’article en question sur Legifrance, en bas de page tu as un bouton “Accéder à l’espace protégé” qui après le clic propose le capcha. Ensuite on a visiblement 5 mn pour lire l’article.
 " />
" />
Au passage, ce système est très mal branlé.
Le bouton “?” censé expliquer comment fonctionne le captcha renvoie une erreur 404.
Et si on se trompe de réponse au captcha, on a simplement une erreur “Veuillez répondre à la question” qui n’indique pas que la réponse est mauvaise.
Je passe sur le mélange chiffres/lettres qui fait qu’on peut douter du format de la réponse à donner
#18
Guéant, Balkany, Fillon tous tombés, reste leur “grand” parrain qui cours toujours entre les tribunaux: Paul Bismuth " />
" />
#19
En parlant de captcha, il faudrait en ajouter un quelque part.. " />
" />
#20
Maintenant que les journalistes annoncent la fin de partie. Sauve qui peut.
Manquerait plus que Balkany se mettre à table pour impliquer toute la clique.
#21
ça serait épique
#22
peut-être pas tant que ça, même si les combinaisons sont complexes les jeux (go, échecs, Starcraft…) font au final intervenir assez peu de compétences. Résoudre un test mathématique nécessite de comprendre l’énoncé et d’établir une stratégie de résolution en fonction des données du problème. Au final, c’est extrêmement varié.
Et c’est encore plus drôle quand il s’agit de prouver des théorèmes mathématiques non triviaux (un exemple en lien, simple dans l’énoncé mais qui a occupé les esprits les plus brillants pendant 350 ans).